1、有没有看过JDK源码,看过的类实现原理是什么。
2、HTTP协议
3、TCP协议
4、一致性Hash算法
5、JVM如何加载字节码文件
loading、verification、preparation 、 Resolution、initialization 、using 、unloading
6、类加载器如何卸载字节码(不是很清楚)
堆中的相应对象置为null,清空方法区中对应的二进制数据结构及其他数据变量等。
7、IO和NIO的区别,NIO优点
同步异步IO:同步异步指的是 应用程序与操作系统OS之间的关系,同步需要等待操作系统切换到内核状态进行IO,等待IO结束后,切换到用户状态,继续执行 ;或者,用户程序轮询访问IO。即同步IO需要参与到IO这个过程。而异步是交给OS一个IO任务,IO完成后OS会通知应用程序。同异步体现在操作IO的主体,同步的主体是用户线程需要执行最后的IO(包括轮询),而异步IO是操作系统执行最后的IO,用户线程只需要获取数据即可。
阻塞非阻塞IO:传统IO即BIO即是阻塞IO,而JDK后面提出的NIO就是非阻塞的IO,阻塞IO需要获得指定的所有数据才可以返回用户状态(或者网络传输获得指定的所有数据)。而非阻塞的IO可以在获得一部分后即可以返回,在新的数据再次到来时再获取,并不会阻塞请求线程。尤其体现在网络数据接收中,如果使用阻塞IO,针对每一个client,都必须有一个线程监听(IO是断断续续的),但是使用非阻塞的时候,只需要很少的线程不断轮询指定的端口,分别获取标识的数据即可。不会有很多的线程被阻塞住。阻塞非阻塞体现在函数上,会阻塞线程。
同步非阻塞:NIO初版。引入buffer,同步即操作主体仍然为用户线程,非阻塞即不会阻塞在线程,但是需要线程轮询检查IO状态,buffer的循环读取。
异步非阻塞:NIO2.0,buffer和回调,操作主体为内核,OS完成之后即回调给用户线程并通知。更不会阻塞线程。
传统IO:面向流。即输入输出字符字节流 InputStream、Reader。之后加上了buffer缓冲。总之是字符字节流的所有扩展API。
NIO:面向块。同步非阻塞IO。引入channel和buffer,文件输入流获取channel→读入buffer→buffer写入channel→channel写入文件。
NIO优点:1、网络NIO无阻塞(很重要) 2、引入buffer,能够减少文件操作次数 3、面向块,操作速度比传统IO快。
示例:
public static void copyFileUseNIO(String src,String dst) throws IOException {
//声明源文件和目标文件
FileInputStream fi = new FileInputStream(new File(src));
FileOutputStream fo = new FileOutputStream(new File(dst));
//获得传输通道channel
FileChannel inChannel = fi.getChannel();
FileChannel outChannel = fo.getChannel();
//获得容器buffer
ByteBuffer buffer = ByteBuffer.allocate(1024);
while (true) {
//判断是否读完文件
int eof = inChannel.read(buffer);
if (eof == -1) {
break;
}
//重设一下buffer的position=0,limit=position
buffer.flip();
//开始写
outChannel.write(buffer);
//写完要重置buffer,重设position=0,limit=capacity
buffer.clear();
}
inChannel.close();
outChannel.close();
fi.close();
fo.close();
}
关于NIO的网络编程:此处体现了非阻塞的IO。
流程简述:有些类似于 severSocket 与 Socket 编程。
服务器端:ServerSocketChannel监听端口,并多开几个channel,同时将channel注册到selector组件里面,并给selector设置channel发来的感兴趣事件(此处是client与server都会设置的东西,4种值),设置好事件后,需要对channel进行循环监听,并且判断client过来的事件属性,做出channel数据接收。
客户端:SocketChannle,初始化hostname与port,将输入输入封装为byte[] → byte数组put进入byteBuffer → bufferBuffer写入channel。
8、Java线程池的实现原理,keepAliveTime等参数的作用。
线程池,对提交上的线程进行统一的管理。用户创建线程但是由线程池来管理执行,以及所有线程的执行顺序、生命周期等,都是由线程池管理,用户不再需要关心线程池何时清除。线程池
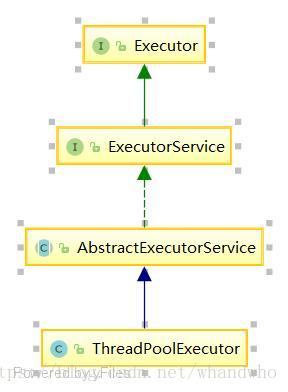
4个构造函数,参数分别是下面参数的部分组合。
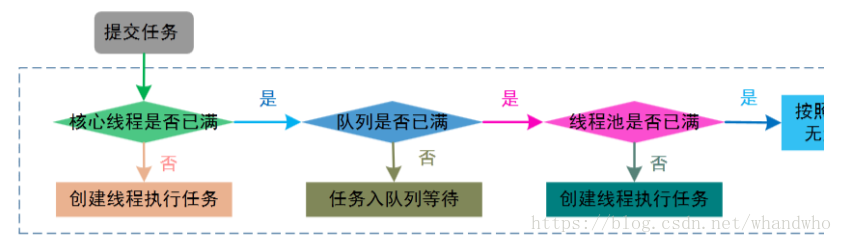
线程池执行流程是:提交线程 → 核心线程是否满?继续:创建 → 等待对列是否满?继续 : 入队 → 是否超出最大线程数?异常处理handler : 继续 → 非核心是否满?创建 图
- corePoolSize:核心池的大小,这个参数跟后面讲述的线程池的实现原理有非常大的关系。在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务,除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法,从这2个方法的名字就可以看出,是预创建线程的意思,即在没有任务到来之前就创建corePoolSize个线程或者一个线程。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中;
- maximumPoolSize:线程池最大线程数,这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程;
- keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会终止,直到线程池中的线程数不超过corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0;
- unit:参数keepAliveTime的时间单位,有7种取值,在TimeUnit类中有7种静态属性:
TimeUnit.DAYS; //天 TimeUnit.HOURS; //小时 TimeUnit.MINUTES; //分钟 TimeUnit.SECONDS; //秒 TimeUnit.MILLISECONDS; //毫秒 TimeUnit.MICROSECONDS; //微妙 TimeUnit.NANOSECONDS; //纳秒
- workQueue:一个阻塞队列,用来存储等待执行的任务,这个参数的选择也很重要,会对线程池的运行过程产生重大影响,一般来说,这里的阻塞队列有以下几种选择:
ArrayBlockingQueue; LinkedBlockingQueue; SynchronousQueue;ArrayBlockingQueue和PriorityBlockingQueue使用较少,一般使用LinkedBlockingQueue和Synchronous。线程池的排队策略与BlockingQueue有关。
- threadFactory:线程工厂,主要用来创建线程;
- handler:表示当拒绝处理任务时的策略,有以下四种取值:
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。 ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。 ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程) ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务具体参数的配置与线程池的关系将在下一节讲述。
而官方不推荐这种方法,而是给出了Executors中的4个静态创建线程池方法,已经定义好部分参数。
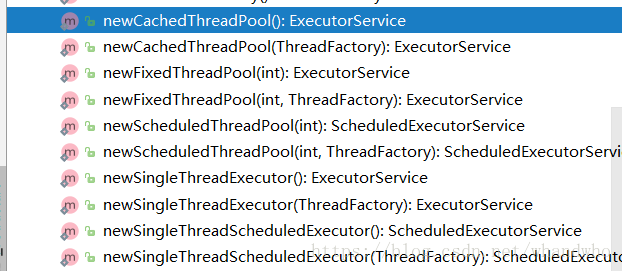
CachedThreadPool:可缓存的线程池,该线程池中没有核心线程,非核心线程的数量为Integer.max_value,就是无限大,当有需要时创建线程来执行任务,没有需要时回收线程,适用于耗时少,任务量大的情况。同步排队策略
SecudleThreadPool:周期性执行任务的线程池,按照某种特定的计划执行线程中的任务,有核心线程,但也有非核心线程,非核心线程的大小也为无限大。适用于执行周期性的任务。特定的一种延迟排队策略
SingleThreadPool:只有一条线程来执行任务,适用于有顺序的任务的应用场景。linked排队策略
FixedThreadPool:定长的线程池,有核心线程,核心线程的即为最大的线程数量,没有非核心线程。linked排队策略
针对排队策略的深层探讨:
ArrayBlockingQueue:数组形式的,有界排队策略,可以避内存被耗光。AQS 抽象排队同步器
LinkedBlockingQueue:链表形式的排队策略,无界。AQS
SynchronousQueue:同步的,队列中只能存一个,且这个必须被取走后下一个才能进入。 CAS 比较并交换
AQS 与 CAS(????????):AQS CAS AQS
AQS 即抽象排队同步器,可重入 reenstrantLock 也是根据内部实现一个自定义同步器来实现的,同步器又分为了 独占锁 和 共享模式,自定义同步器只需要重写部分方法即可。 并且其中还有 公平 与 非公平的策略提高并发量。
CAS 即比较并交换,现有的值 A 与期待值 B 不一样,则将现有值 A 赋值为 C,否则不操作,不断的循环请求,并且现有值 A 是通过 volatile 关键字修饰的,可以保证每次get的 A 是最新的值,这样就可以确保执行的线程是一个有序的线程序列,实现了不加锁的同步方式。因为CAS是基于乐观锁的,也就是说当写入的时候,如果寄存器旧值已经不等于现值,说明有其他CPU在修改,那就继续尝试。所以这就保证了操作的原子性。其中有ABA的缺点,即经过几次修改变回之前的值A,而被阻塞的线程只会判断值,所以引入版本判别,记录更改记录。使用volatile(省掉锁,却不能原子性,因为一次赋值操作分为了三步,copy到本地→赋值→刷新到缓存),而Atomic(volatile+CAS),同时起作用实现锁。关于 volatile 非原子性
参考:
https://www.cnblogs.com/xzn-smy/p/9172555.html
https://blog.csdn.net/wbb_1216/article/details/62882921
http://m.blog.sina.com.cn/s/blog_ee34aa660102wsuv.html#page=7
9、HTTP连接池实现原理
主要是用来降低 连接次数,因为每次请求都经过三次握手、四次释放,网络延迟很大。(具体使用方法及原理?????等计算机网络学完部分)
10、数据库连接池实现原理
建立一个管理机制,对connection、statement、result三种资源进行统一的管理,即开有限次资源的接口,交给一个数据结构进行统一的管理,然后释放线程对这个接口的使用权,通过并发控制来决定线程拥有公有访问接口的权利及顺序。很类似与线程池。https://www.cnblogs.com/newpanderking/p/3875749.html
11、数据库的实现原理
参考:
数据库实现原理: