版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/boy_of_god/article/details/83717085
文章目录
1对表中的记录进行操作
本博客中的测试数据库
create database studyTest;
use studyTest;
create table user(
id int primary key auto_increment,
username varchar(16) unique,
password varchar(16) not null,
age int,
birthday date
);
1.1SQL添加表的的记录
- 向表中插入某些列:
insert into 表名 (列名1,列名2,列名3…) values (值1,值2,值3…)
- 向表中插入所有列:
insert into 表名 values (值1,值2,值3…);//要与表中的字段对应
- 注意
1.值的类型与数据库中表列的类型一致。
2.值的顺序与数据库中表列的顺序一致。
3.值的最大长度不能超过列设置最大长度。
4.值的类型是字符串或者是日期类型,使用单引号引起来。
运行结果 :
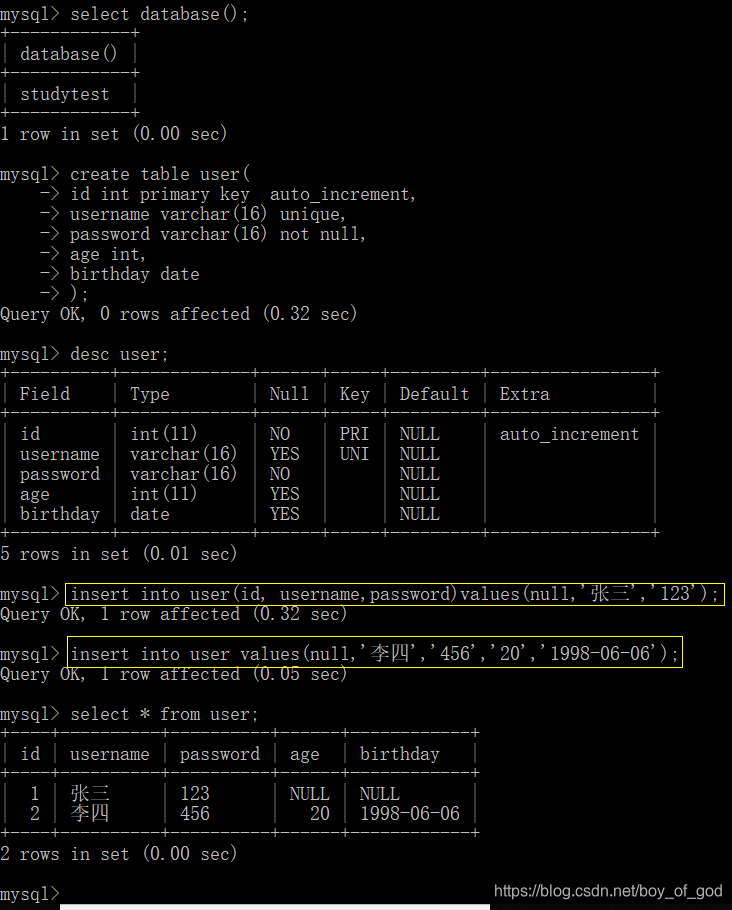
直接向数据库中插入中文记录会出现错误!!!
解决方法:
show variables like ‘%character%’; --查看数据库中与字符集相关参数:
需要将MySQL数据库服务器中的客户端部分的字符集改为gbk。
找到MySQL的安装路径:my.ini文件,修改文件中[client]下的字符集
1.2SQL修改表的记录
- 修改表中的记录
update 表名 set 列名=值,列名=值 [where 条件];
- 注意;
1.值的类型与列的类型一致。
2.值的最大长度不能超过列设置的最大长度。
3.字符串类型和日期类型添加单引号。 - 修改某一列的所有的值
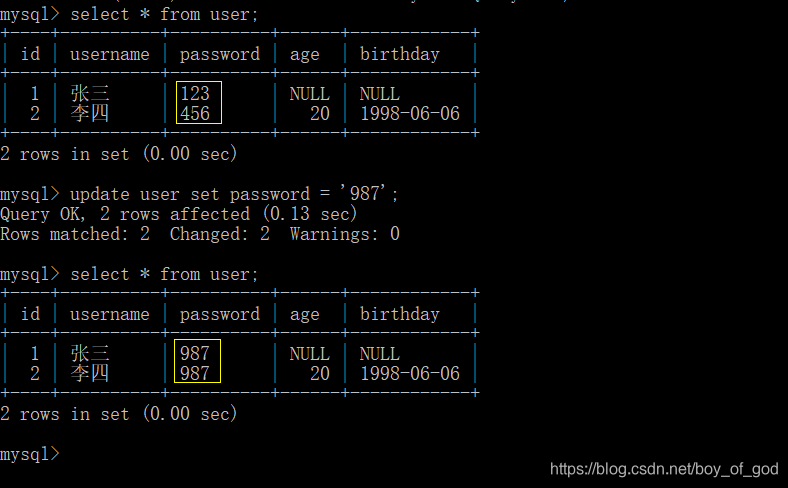
update user set password = '987';
结果:
- 按条件修改数据(修改一条记录的值)
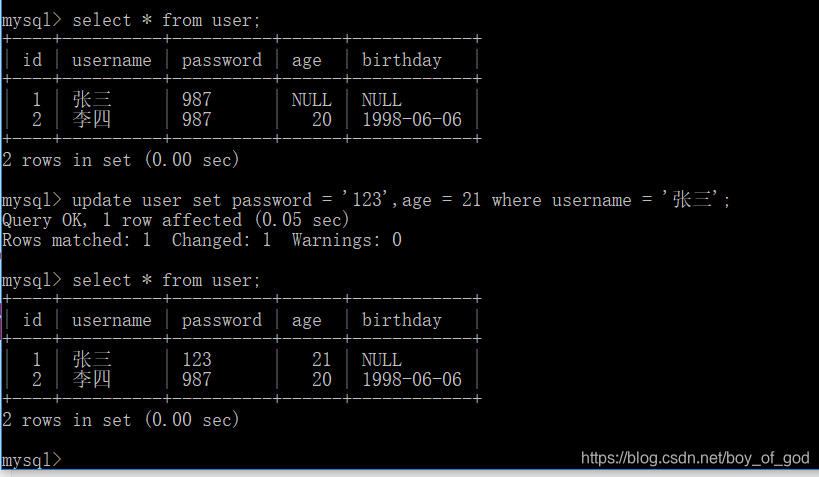
update user set password = '123' ,age = 21 where username = '张三';
运行结果:
1.3SQL删除表的记录
- 语法
delete from 表名 [where 条件];
-
注意
1.删除表的记录,指的是删除表中的一行记录。
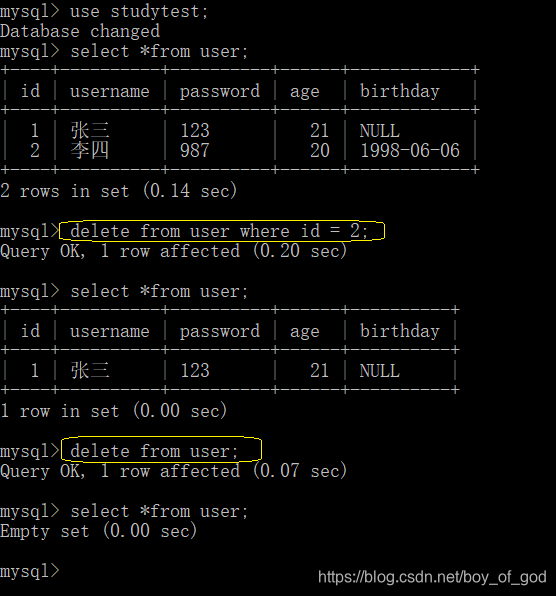
2.删除如果没有条件,默认是删除表中的所有记录。- 删除某一条记录
delete from user where id = 2;- 删除表中所有记录
delete from user;运行结果:
-
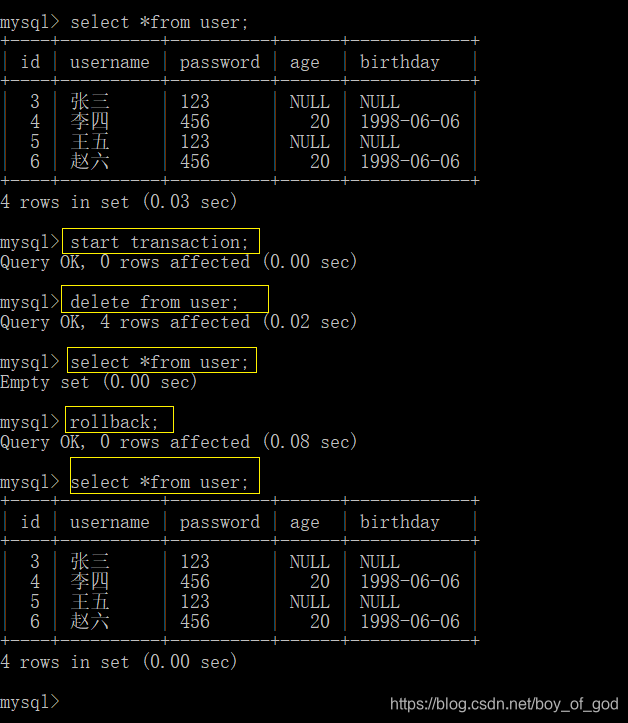
delete from user;
属于DML语句,一条一条记录的删除,事务可以作用在DML语句中
start transaction;//开启事务
rollback;//事务回滚
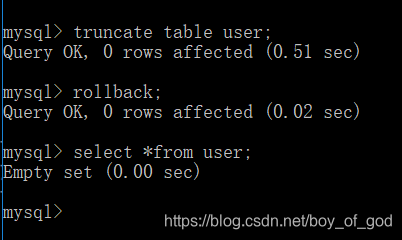
- truncate table user;
属于DDL,将表删除然后重建一个结构一样的表,事务不能控制DDL
结果1:
结果2
1.4SQL查看表的记录
测试查询代码
create table exam(
id int primary key auto_increment,
name varchar(20),
english int,
chinese int,
math int
);
insert into exam values (null,'张三',85,74,91);
insert into exam values (null,'李四',95,90,83);
insert into exam values (null,'王五',85,84,59);
insert into exam values (null,'赵六',85,84,59);
insert into exam values (null,'李四',60,90,83);
1.4.1基本查询
select [distinct] *|列名 from 表 [条件];
[distinct]:去除重复的信息
-
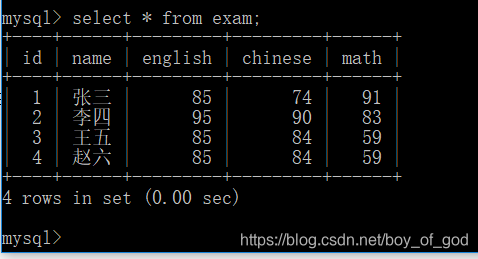
查询所有信息
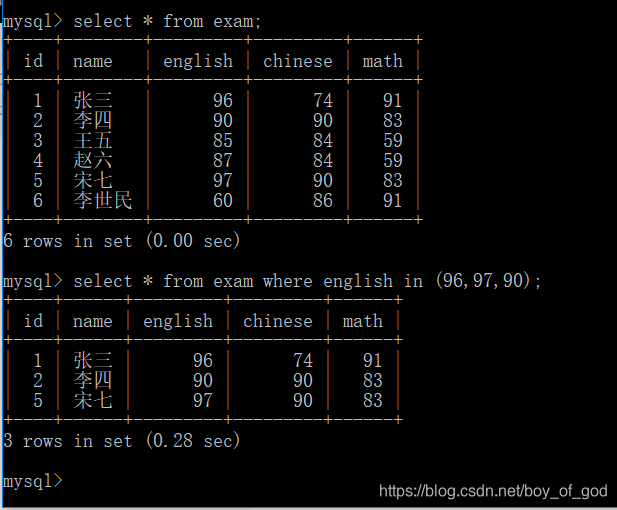
select * from exam;结果;
-
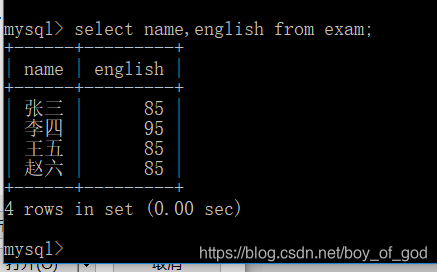
查询所有学生的姓名和英语成绩
select name,english from exam;结果:
-
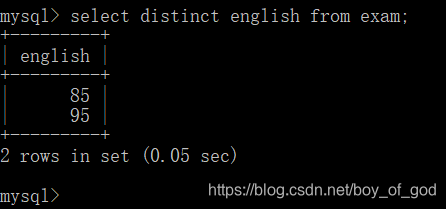
查询英语成绩信息(不显示重复的值)
select distinct english from exam;运行结果:
-
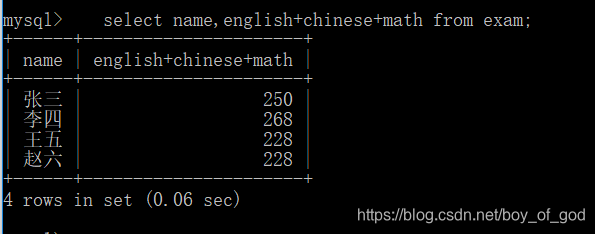
查看学生成绩的总和
select name,english+chinese+math from exam;运行结果:
-
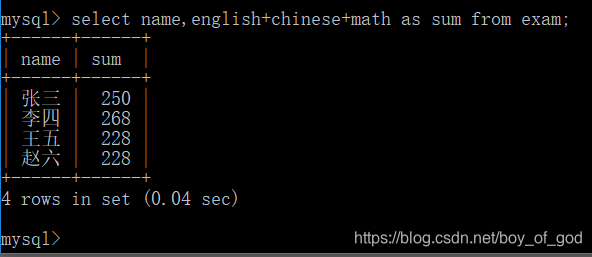
别名查询
select name,english+chinese+math as sum from exam;运行结果:
1.4.2条件查询
-
使用where子句
- 如> , < , >= , <= , <> ,=
- like:模糊查询
- in:范围查询
- 条件关联:and , or ,not
-
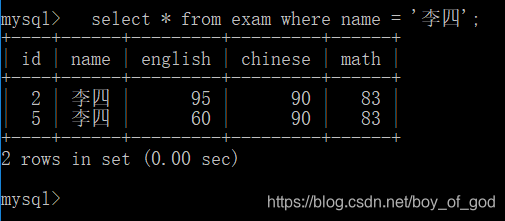
查询李四学生的成绩
select * from exam where name = '李四';运行结果:
-
查询名称叫李四学生并且英文大于90分
select * from exam where name = '李四' and english > 90;运行结果:

-
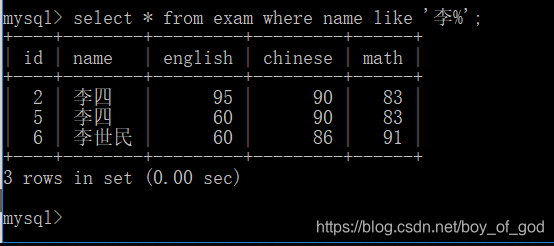
查询姓李的学生的信息
like可以进行模糊查询,在like子句中可以使用_或者%作为占位符。_只能代表一个字符,而%可以代表任意个字符。- like ‘李_’ :名字中必须是两个字,而且是姓李的。
- like ‘李%’ :名字中姓李的学生,李子后可以是1个或任意个字符。
- like ‘%四’ :名字中以四结尾的。
- like ‘%王%’ :只要名称中包含这个字就可以。
select * from exam where name like '李%';运行结果:
- 查询英语成绩是69,75,89学生的信息
select * from exam where english in (69,75,89);运行结果:
-
查询英语成绩是96,90,97的学生信息
select * from exam where english in(96,90,97);
1.4.3排序查询
- 使用order by 字段名称 asc/desc;
- asc:升序、desc:降序
- 查询学生信息,并且按照语文成绩进行排序:
select * from exam order by chinese; - 查询学生信息,并按照语文成绩倒序
select * from exam order by chinese desc;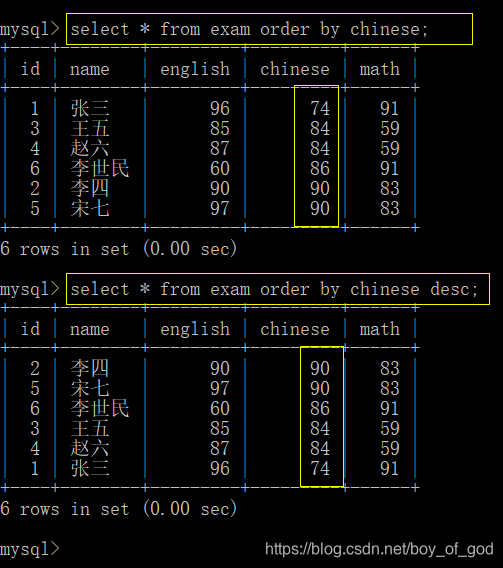
- 查询学生信息,先按照语文成绩进行倒序排序,如果成绩相同再按照英语成绩升序排序
select * from exam order by chinese desc,english asc;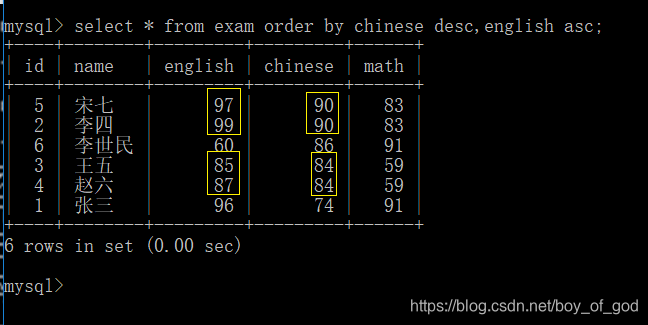
- 查询姓李的学生英语成绩按照降序排列
select * from exam where name like '李%' order by english desc;
1.4.4分组统计查询
1.4.4.1聚合函数
-
sum()
- 获取所有学生的英语成绩的总和:
select sum(english) from exam;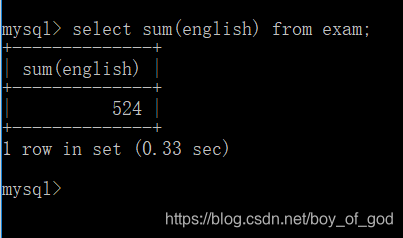
- 获取所有学生的英语成绩和数学成绩总和:
select sum(english),sum(math) from exam;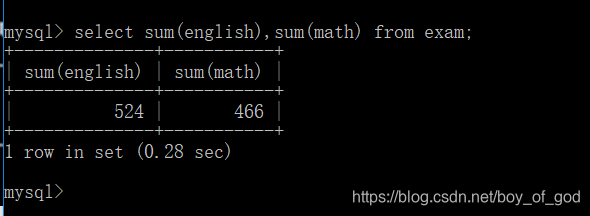
- 查询姓李的学生的英语成绩的总和
select sum(english) from exam where name like '李%';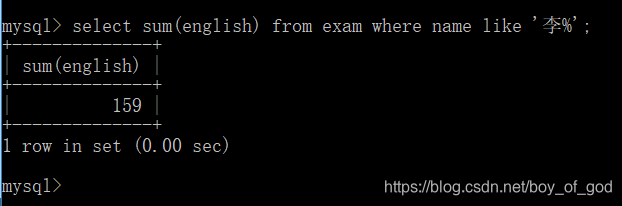
- 查询所有学生各科的总成绩:
select sum(english)+sum(chinese)+sum(math) from exam;照列的方式统计,英语成绩总和+语文成绩总和+数学成绩总和 select sum(english+chinese+math) from exam;先计算英语+数学+语文然后再求和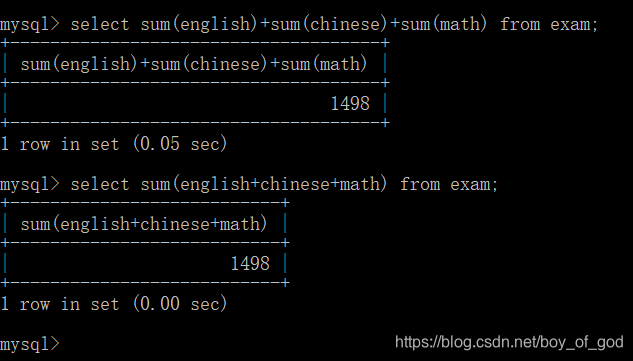
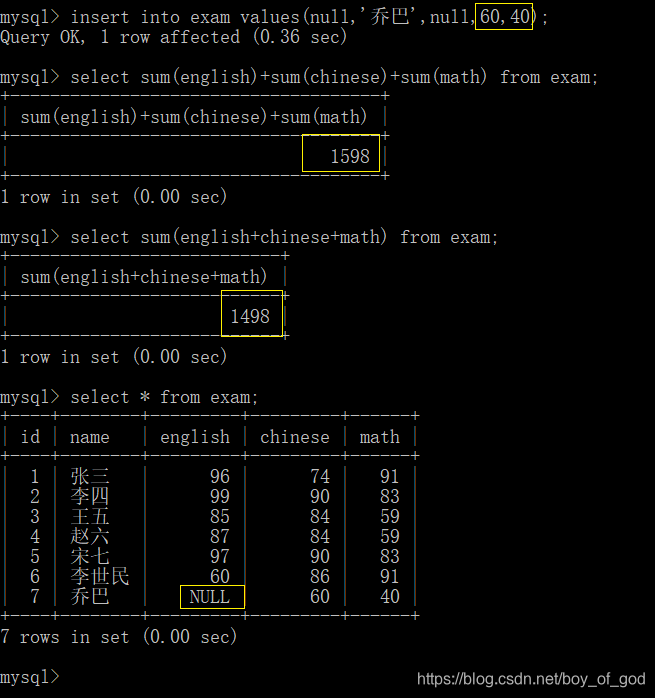
- 使用ifnull()
select sum(ifnull(english,0) + chinese + math) from exam;
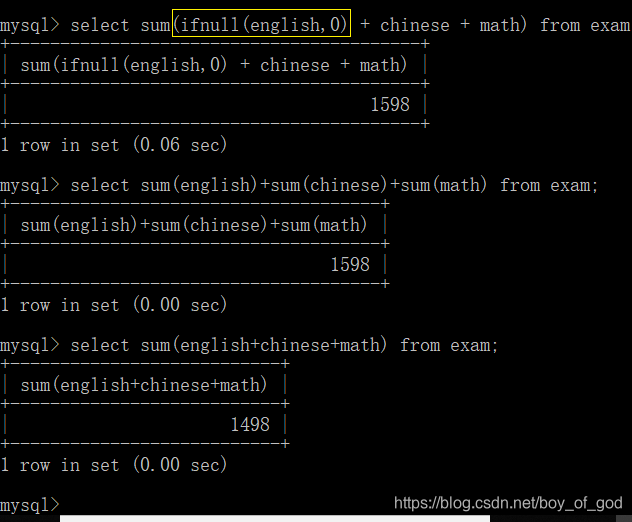
- 获取所有学生的英语成绩的总和:
-
count()
- 获得学生的总数
select count(*) from exam; - 获得姓李的学生的个数
select count(*) from exam where name like '李%';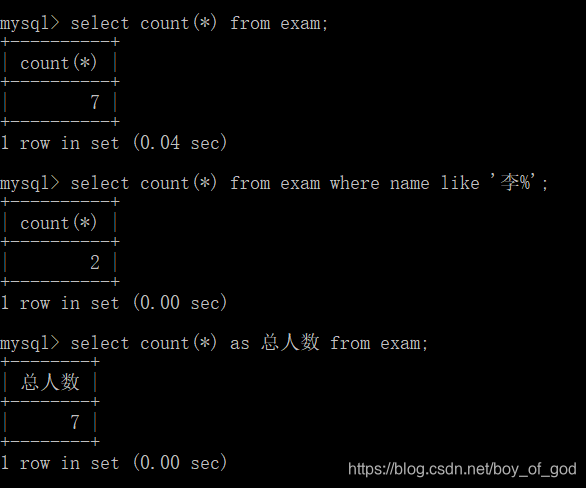
- 获得学生的总数
-
max()
- 获得数学成绩的最高分:
select max(math) from exam;
- 获得数学成绩的最高分:
-
min()
- 获得语文成绩的最小值
select min(chinese) from exam;
- 获得语文成绩的最小值
-
avg()
- 获取语文成绩的平均值
select avg(chinese) from exam;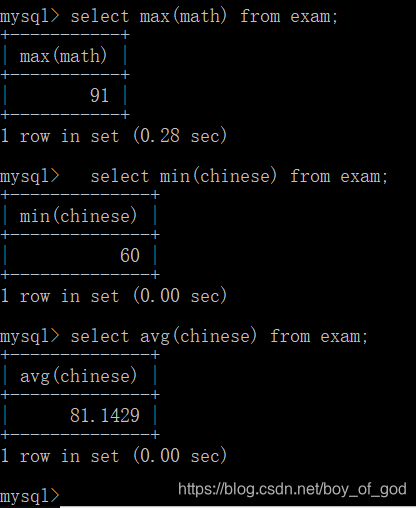
- 获取语文成绩的平均值
1.4.4.2分组查询
- 使用group by 字段名称
环境
create table orderitem(
id int primary key auto_increment,
product varchar(20),
price double
);
insert into orderitem values (null,'电视机',2999);
insert into orderitem values (null,'电视机',2999);
insert into orderitem values (null,'洗衣机',1000);
insert into orderitem values (null,'洗衣机',1000);
insert into orderitem values (null,'洗衣机',1000);
insert into orderitem values (null,'冰箱',3999);
insert into orderitem values (null,'冰箱',3999);
insert into orderitem values (null,'空调',1999);
-
按商品名称统计,每类商品所购买的个数:
select product,count(*) from orderitem group by product;//即查名称又查个数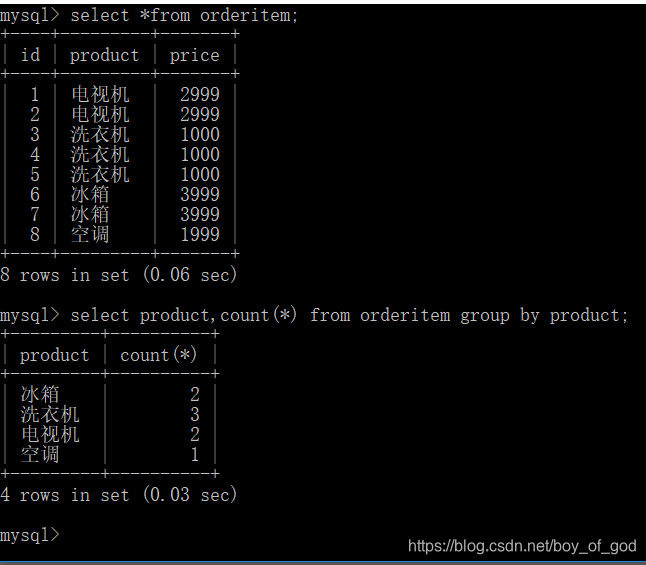
- 按商品名称统计,每类商品所花费的总金额:
select product,sum(price) from orderitem group by product;//即查名称又查总金额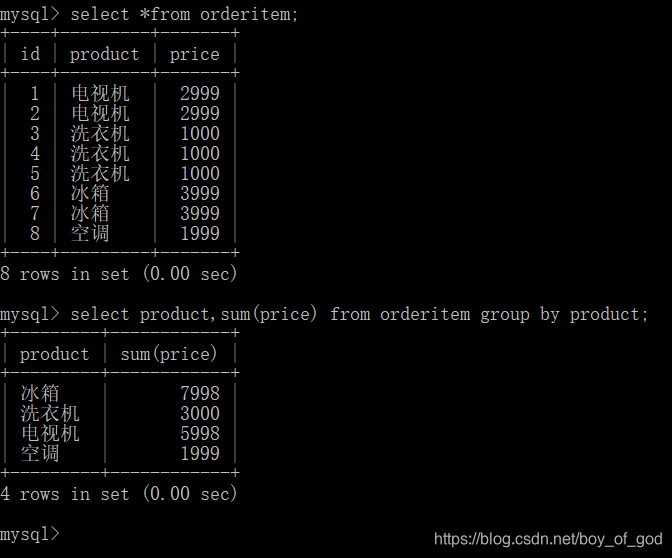
- 按商品名称统计,每类商品所花费的总金额:
-
按商品名称统计,统计每类商品花费的总金额在5000元以上的商品
where的子句后面不能跟着聚合函数。如果现在使用带有聚合函数的条件过滤(分组后条件过滤)需要使用一个关键字having
下面两个是错的。
select product,sum(price) from orderitem where sum(price) > 5000 group by product
select product,sum(price) from orderitem group by product where sum(price) > 5000
select product,sum(price) from orderitem group by product having sum(price) > 5000;

- 按商品名称统计,统计每类商品花费的总金额在5000元以上的商品,并且按照总金额升序排序
select product,sum(price) from orderitem group by product having sum(price) > 5000 order by sum(price) asc;
S(select)…字段… F(from)…表格…W(where)…条件1(不能是聚合函数)…G(group by)…分组…H(having)…条件2(可以有聚合函数)…O(order by) …排序;