python数据科学入门与分析
第二章 数据科学的Python核心
1.print("hello".capitalize());将第一个字符转化为大写,其他字符转化为小写
2.print("hello world ".strip());:注意lstrip,rstrip,strip的用法
3.print("www.baidu.com".split(".")):会用split里面的分割符进行分割
4print("a".islower());:islower,isupper,isspace,isdigit,isalpha的使用
5.print("-".join("210.34.148.51".split(".")));: #.join函数仅在字符串之间进行插入,在字符串的开头一个末尾都不进行插入
多行的注释方式为ctrl+1
#计数器的运用
from collections import Counter
phrase = "世界 你 好,你好! 你好"
cntr = Counter(phrase.split())
print(cntr.most_common)
8.爬取数据,并注意相应的异常处理机制
#这里是从web中爬取相应的数据
#这里一定要有相应的异常处理机制 try except
import urllib.request
try:
with urllib.request.urlopen("http://www.networksciencelab.com") as doc:
html = doc.read();
print("yes")
except:
print("couldn't not open file");
首先,你应该熟记正则表达式的各种表示形式,附下图
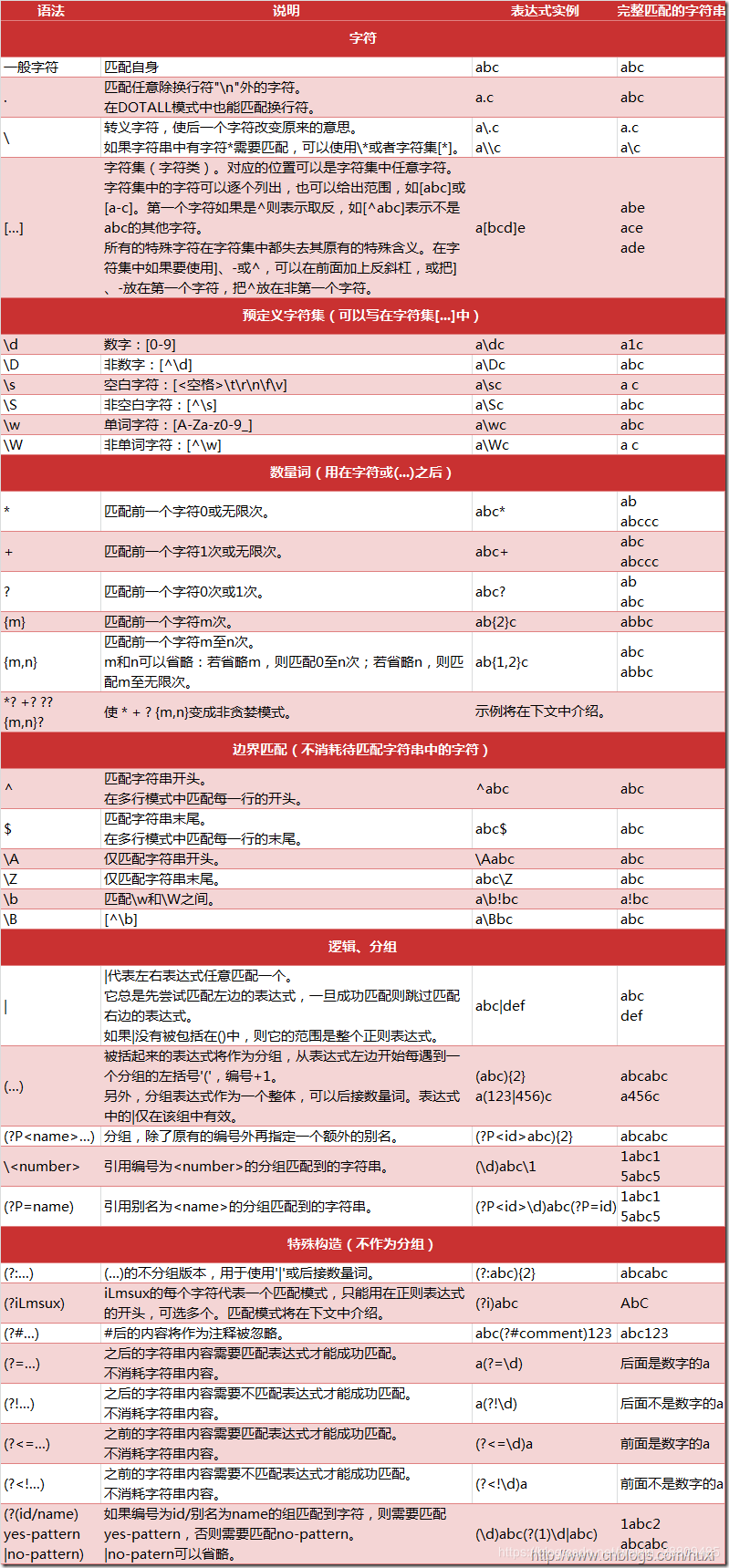 示例
示例
1.re.findall
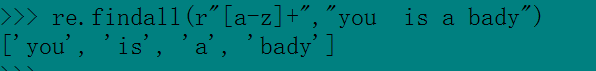
2.re.split
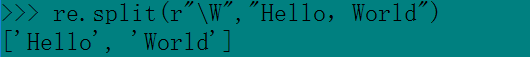
3.re.sub(pattern,repl,string),用 repl替换字符串中的所有非重叠匹配部分

示例 glob函数
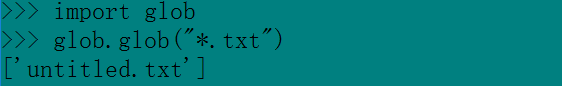
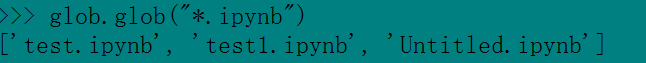
pickle模块用于实现序列化-将任意的python数据结构保存到一个文件中,并将其作为python表达式读回。
作用:python程序运行中得到了一些字符串,列表,字典等数据,想要长久的保存下来,方便以后使用,而不是简单的放入内存中关机断电就丢失数据。
import pickle
a = {" name ": "Tom", "age": "40"}
with open('text.txt', 'wb') as file:
pickle.dump(a, file)
with open('text.txt', 'rb') as file2:
b = pickle.load(file2)
print(type(b))
print(b)
其实,就是将数据按照某种格式存入文件之中,而不是以字符串的形式读入的。
第三章 使用文本数据
Beautifulsoup的使用
from bs4 import BeautifulSoup
from urllib.request import urlopen
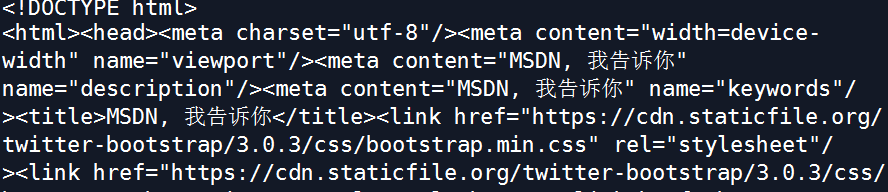
soup3 = BeautifulSoup(urlopen("https://msdn.itellyou.cn/"),"lxml")
print(soup3)
效果
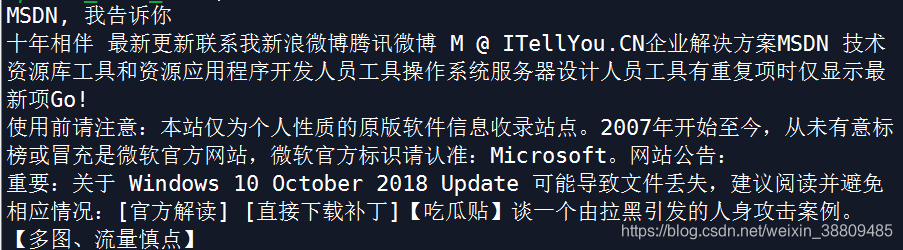
 使用soup.get_text()方法可得到标记文档中取出了所有标签的文本部分
使用soup.get_text()方法可得到标记文档中取出了所有标签的文本部分
 soup的函数:soup.find(),soup.find_all()
soup的函数:soup.find(),soup.find_all()
##beautifulsoup模块的运用
from bs4 import BeautifulSoup
from urllib.request import urlopen
soup3 = BeautifulSoup(urlopen("https://msdn.itellyou.cn/"),"lxml")
##print(soup3.get_text())
#soup4 = soup3.find(id = "mySmallModalLabel")
#print(soup4)
#links = soup3.find_all("a")
#firstLink = links[0]["href"]
#print(firstLink)
CSV文件
CSV是一种结构化文本文件格式,用于存储和转移表格数据。一个CSV文件由表示变量的列和表示记录的行组成。
JSON
Json(JavaScript Object Notation)是一种轻量级的数据交换格式,Json支持原子数据类型,数组,对象,键值对
将复杂数据存储到Json文件中的操作称为序列化,相应的反向操作则称为反序列化
学习的网站:菜鸟教程
总是要通过一定的扩展,才能真正的掌握一些 东西的。
编码json数据
#编码为json数据
import json
data = [ { 'a' : 1, 'b' : 2, 'c' : 3, 'd' : 4, 'e' : 5 } ]
json = json.dumps(data)
print(json)
解码json数据
import json
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}';
text = json.loads(jsonData)
print(text)
也许,你到这里对json也还是一知半解,只知道它对数据格式的转换还是挺有用的。