参考文章:
https://juejin.im/post/5a9ca0d6518825555c1d1acd
数据库的范式:
参考链接: https://www.zhihu.com/question/24696366
范式(NF):符合某一种级别的关系模式的集合,表示一个关系内部各属性之间的联系的合理化程度
1NF, 2NF, 3NF, BCNF, 4NF, 5NF 一般考虑到BCNF就可以,符合高一级范式的设计,必然符合低一级范式
1NF(所有关系型数据库的最基本要求, 如果不符合这个要求,创建表操作一定不成功):关系中的每个属性都不可再分
反例:
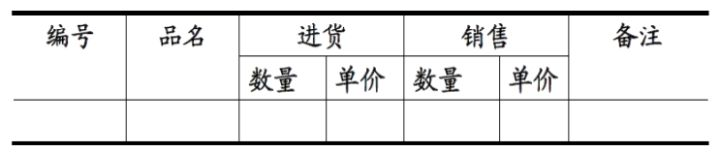
进货下面不能再分为数量和单价
改正:

2NF(解决1NF中存在的数据冗余过大,插入/删除/修改异常等问题): 表中的字段必须完全依赖于全部主键而非部分主键
其他字段组成的这行记录和主键表示的是一个东西,而主键是唯一的,它们只需要依赖于主键,也就成为了唯一的
3NF():非主键外的所有字段必须互不依赖 数据只在一个地方存储,不重复出现在多张表中,可以认为是消除传递依赖
比如,我们大学分了很多系(中文系、英语系、计算机系……),这个系别管理表信息有以下字段组成:系编号,系主任,系简介,系架构。那我们能不能在学生信息表添加系编号,系主任,系简介,系架构字段呢?不行的,因为这样就冗余了,非主键外的字段形成了依赖关系(依赖到学生信息表了)!正确的做法是:学生表就只能增加一个系编号字段。
什么是事务?
一个Session钟所进行的所有操作,要么同时成功,要么同时失败
AtomicityConsistency*Isolation**D*urability 数据库正确执行的四个基本要素
举例: A向B转账,转账这个流程如果出现问题,事务机制可以让数据恢复为原来的样子【只可能出现A减B加或A不减B不加两种结果,不可能出现A减B不加和A不减B加】
JDBC默认情况下是关闭事务的,
【假定一切正常】
//JDBC默认的情况下是关闭事务的,下面我们看看关闭事务去操作转账操作有什么问题
//A账户减去500块
String sql = "UPDATE a SET money=money-500 ";
preparedStatement = connection.prepareStatement(sql);
preparedStatement.executeUpdate();
//B账户多了500块
String sql2 = "UPDATE b SET money=money+500";
preparedStatement = connection.prepareStatement(sql2);
preparedStatement.executeUpdate();
【假定转账过程中出现了问题】: 代码抛出异常导致A账号少了500块钱,B账户的钱没有增加。
String sql = "UPDATE a SET money=money-500 ";
preparedStatement = connection.prepareStatement(sql);
preparedStatement.executeUpdate();
//这里模拟出现问题
int a = 3 / 0;
String sql2 = "UPDATE b SET money=money+500";
preparedStatement = connection.prepareStatement(sql2);
preparedStatement.executeUpdate(); //开启事务,对数据的操作就不会立即生效。
connection.setAutoCommit(false);
//A账户减去500块
String sql = "UPDATE a SET money=money-500 ";
preparedStatement = connection.prepareStatement(sql);
preparedStatement.executeUpdate();
//在转账过程中出现问题
int a = 3 / 0;
//B账户多500块
String sql2 = "UPDATE b SET money=money+500";
preparedStatement = connection.prepareStatement(sql2);
preparedStatement.executeUpdate();
//如果程序能执行到这里,没有抛出异常,我们就提交数据
connection.commit();
//关闭事务【自动提交】
connection.setAutoCommit(true);
} catch (SQLException e) {
try {
//如果出现了异常,就会进到这里来,我们就把事务回滚【将数据变成原来那样】
connection.rollback();
//关闭事务【自动提交】
connection.setAutoCommit(true);
} catch (SQLException e1) {
e1.printStackTrace();
}事务隔离级别:
- Serializable【可避免脏读,不可重复读,虚读】
脏读: 一个事务读取到另一个事务未提交的数据
举例:A向B转账,A执行了转账语句,但A还没有提交事务,B读取数据,发现自己账户钱变多了!B跟A说,我已经收到钱了。A回滚事务【rollback】,等B再查看账户的钱时,发现钱并没有多。
不可重复读: 一个事务读取到另一个事务已经提交的数据,一个事务看到其它事务所做的修改
举例: A查询数据库得到数据,B去修改数据库的数据,导致A多次查询数据库的结果都不一样
虚读:在一个事务内读取到了别的事务插入的数据,导致前后读取不一致
举例: 和不可重复读类似,但虚读(幻读)会读到其他事务的插入的数据,导致前后读取不一致
数据库的乐观锁和悲观锁是什么?
数据库的锁机制中介绍过,数据库管理系统(DBMS)中的并发控制的任务是确保在多个事务同时存取数据库中同一数据时不破坏事务的隔离性和统一性以及数据库的统一性。
悲观并发控制(Pessimistic Concurrency Control,缩写“PCC” 悲观锁):假定会发生冲突,屏蔽一切可能违规的操作
在查询完之后就把事务锁起来,直到提交事务 实现:使用数据库中的锁机制
悲观锁的实现,往往依靠数据库提供的锁机制 (也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)
流程:
- 在对任意记录进行修改之前,先尝试为该记录加上排他锁(exclusive locking)
- 如果加锁失败,说明该记录正在被修改,那么当前查询可能要等待 或抛出异常
- 如果加锁成功,就可以对记录做修改,事务完成后就会解锁
- 在被加锁期间,如果有其它的记录对该记录做出修改或加排他锁,都会等待我们解锁或直接抛出异常
乐观锁: 假定不会发生冲突,只在提交操作时检查是否违规
在修改数据的时候把事务锁起来,通过version的方式来进行锁定
实现:使用version版本或者时间戳
数据库索引
索引(在MySQL当中也叫做Key)是存储引擎用于快速找到记录的一种数据结构。这是索引的基本功能。
索引优化可以被认为是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高几个数量级。
最优 比 好的 索引性能要好两个数量及,创建一个真正最优的索引经常需要重写查询。
索引基础
查字典
索引中找到对应值,根据匹配的索引记录找到对应数据行
索引是什么
SELECT first_name FROM sakila.actor WHERE actor_id = 5;
索引可以包含一个或多个列的值。如果索引包含多个列,那么列的顺序也十分钟要,因为MySQL只能够高效地使用索引的最左前缀匹配,一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。
举例:a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
索引可以包含多个列
索引的类型
MySQL中,索引是在存储引擎层而不是服务器层面实现的,所以没有统一的索引标准:不同存储引擎的索引的工作方式不同,也不是所有的存储引擎都支持所有类型的索引
B-Tree索引
B-Tree简介
B+Tree:每个叶子节点都包含指向下一个叶子节点的指针, 从而方便叶子节点的范围遍历
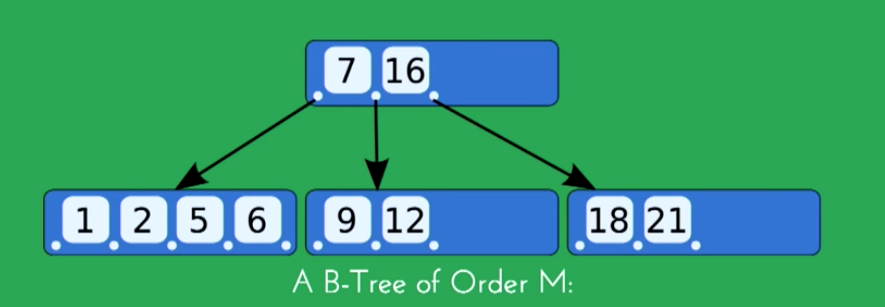
Every node has at most m children
A non-leaf node with k children contains k - 1 keys
The root has at least two children if it is not a leaf node
Every non-leaf node(except root) has at least [m/2] children
All leaves appear in the same level
B-Tree对索引列是顺序组织存储的,所以很适合查找范围数据。
举例:对于一个基于文本域的索引树上,找出所有以A到C开头的名字 效率很高
CREATE TABLE People (
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
gender enum('m', 'f') not null,
key(last_name, first_name, dob)
);
索引对于多个值进行排序的一句是CREATE TABLE语句中定义索引时列的书序,比如例子中最后两个条目中,如果两个人的姓和名都一样,则根据他们的出生日期进行排序
适用查询类型:全键值,键值范围或键前缀查找(最左)
不适用的查询类型:
* 不是按照索引的最左列开始查找,则无法使用该索引
* 举例: 上面数据表中,无法查询名字为Bill的人,无法查找某个特定生日的人,因为这两列都不是数据最左列,也无法查找姓氏以某个字母结尾的人
* 不能跳过索引中的列
* 如果查询中有某个列的范围查询,则右边所有列都无法使用索引优化查找
哈希索引
建索引的原则
- 最左前缀匹配原则
MySQL 索引类型,隔离级别以及实现
MongoDB + AWS
谈谈乐观锁
MySQL的事务
如何进行索引调优
MySQL索引的数据结构, 使用B树的原因
Mybatis的一二级缓存
有一个数据表的数据量比较大,读多写少的数据库如何设计
数据库的数据量比较多时,查询较慢,如何进行优化?
数据库的联合索引是什么? 如何进行索引优化? 如何知道SQL语句是否使用了索引,以及使用了哪些索引?
你知道数据库分库分表有哪些?各自在何种情况下使用?
数据库分库分表时如何进行划分?
对于MySQL的索引有哪些了解? 哪些列适合建索引? 索引是越多越好么?
悲观锁和乐观锁
MySQL存储引擎、事务隔离级别、锁
MySQL索引,面试官写了一条SQL语句,问使用到了哪些索引,为什么?
Mybaitis 和 Hibernate 区别