准备环境
CentOS 7
jdk1.8 (这里建议使用1.8版本的jdk 链接:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)
hadoop-2.7.3.tar.gz ( 链接:http://mirrors.hust.edu.cn/apache/hadoop/)
机器环境
使用三台机器搭建hadoop集群,其中一台为Master,两台为Slave1.Slave2; (搭建集群的机器数量最好为奇数,包括master)
这里我们准备三台机器,来搭建一个小型hadoop分布式集群,分别是 master(主节点),slave1,slave2 。
三台机器IP 如下:
- 192.168.1.106
- 192.168.1.105
- 192.168.1.104
三台机器在集群中的作用:
master 担任 NameNode、DataNode、ResourceManager、NodeManager
slave1 担任 DataNode、NodeManager
slave2 担任 DataNode、NodeManager
hadoop环境准备
设置主机名

打开后ins进入编辑模式 输入主机名 master;同理 slave步骤也一样 (我这里已经设置好了)
Esc :wq! 保存退出
这里需要重启 主机名生效
设置IP与主机名映射

进入编辑IP与主机名映射
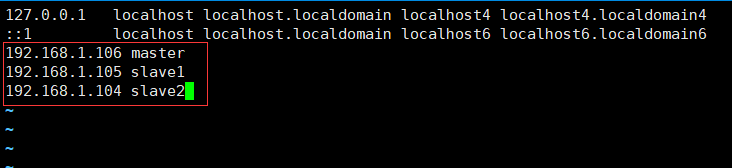
# 这里 三台机器都要需要此操作
#这里 注意 IP与主机名之间 应有一个空格
在之后添加集群 则需要在 /etc/hosts中添加映射关系 并且分发个各个集群
关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service

配置ssh免密登录
集群之间的机器需要相互通信,所以我们必须先配置免密码登录。在三台机器上都得配置免密。(每台机器都需要配置)

以 rsa 算法生成密钥。连续按四个空格,有yes输入yes
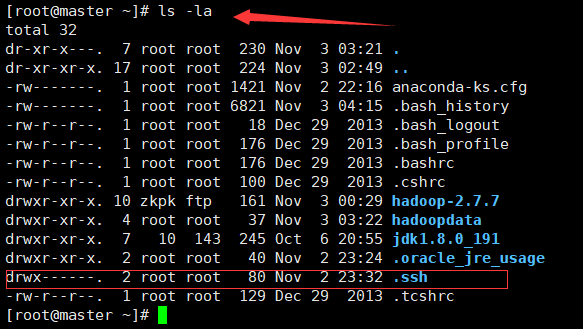
完成之后 ls -la 查看当前隐藏文件
看到一个 .ssh 的文件 这就是刚才生成的 存放密钥的文件夹
有.ssh 说明你密钥已经生成成功了!!!
cd .ssh cd 进去之后可以看到有两个文件

id_rsa 为私钥
id_rsa.pub 为公钥
known_hosts 进行记录链接到对方时,对方给的host key进行简单的验证 (首次创建免密且没有任何链接的 是没有这个文件)
给密钥添加权限:
chmod 600 ~/.ssh/authorized_keys

复制公钥文件 给 authorized_keys
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys (首次创建免密且没有任何链接的 是没有这个文件)
#注意 文件明必须是 这个名称!!!
按照以上步骤 把slave1, slave2 ,的 公钥 拷贝到 authorized_keys 文件中。(这里只有一个authorized_keys文件,且内容包括 master,slave1,slave2,的公钥)
把三台机器的公钥拷贝给 authorized_keys 后。分发给各个slave
scp ~/.ssh/authorized_keys root@slave1:~/ (同理分发给 slave1,slave2 ,)
验证是否 免密成功
以下操作在主节点master上
ssh master(此步骤是验证master是否给master免密成功)
ssh slave1
ssh slave2



出现这种情况表明ssh免密成功
exit 退出当前用户

安装jdk
上传jdk安装包到 Linux 上 (参考软件 Xshell 等)
解压 jdk
tar -zxvf jdk-8u152-linux-x64.tar.gz (解压到当前目录下)
配置环境变量

vi /etc/profile 打开后再最后加上一下几句话:
export JAVA_HOME=/root/usr/java/jdk1.8.0_152
export PATH=$JAVA_HOME/bin:$PATH

使用source /etc/profile让profile文件立即生效。

输入 java 命令测试是否完成
如出现以下情况 则完成环境的安装:
输入 java -version 来验证,如出现以下则为成功:

输入 jps
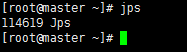
出现 jps则成功
hadoop安装
下载hadoop-2.7.3.tar.gz 解压
tar -zxvf hadoop-2.7.3.tar.gz (解压到当前目录)
cd 到Hadoop目录下
cd hadoop-2.7.3/etc/hadoop/

配置环境变量 hadoop-env.sh
进入Hadoop目录下
ls 查看 文件

vi hadoop-env.sh
打开后在文件靠前的一部分找到
export JAVA_HOME=${JAVA_HOME}

修改为你本机 jdk安装的路径

这里修改的是我本机 jdk 的路径
保存 退出 :wq!
配置环境变量 yarn-env.sh
vi yarn-en.sh
在文件靠前一部分找到以下代码:
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/

将这行代码修改为下面的代码(将#号去掉):
export JAVA_HOME=/root/usr/java/jdk1.8.0_152 (这里是本机的 jdk 路径)

配置核心组件 core-site.xml
vi core-site.xml
用下面的代码替换 <configuration> 中的内容:
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
配置文件系统 hdfs-site.xml
vi hdfs-site.xml
用下面的代码替换 <configuration> 中的内容:
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop_tmp</value>
</property>
配置文件系统 yarn-site.xml
vi yarn-site.xml
用下面的代码替换 <configuration> 中的内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
配置计算框架 mapred-site.xml
先把mapred-site-template.xml更名为 mapred-site.xml
mv mapred-site-template.xml mapred-site.xml
vi mapred-site.xml
用下面的代码替换 <configuration> 中的内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
在 master 节点配置 slaves 文件
vi slaves
用下面的代码替换 slaves 中的内容:
slave1
slave2
以上配置是集群的主机名 (如需要添加集群 这里配置需要添加)
#以上配置需要都在slave等从机设置以上配置,或者手动添加配置,或者拷贝过去。
配置 Hadoop 启动的系统环境变量
先回到根目录
cd ~
vi .bash_profile

export HADOOP_HOME=/root/bigdata/hadoop-2.7.3
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin

刷新环境变量
source ~/.bash_profile
格式化 Hadoop 集群
首先进入Hadoop安装目录下 的 bin 目录
hdfs namenode -format
至此格式化完成,Hadoop安装完成
启动 Hadoop 集群
首先进入Hadoop安装目录下
sbin/start-all.sh (只需要在master节点上启动一次,无需再slave节点上启动此命令!!!)
出现以下情况Hadoop则为启动成功:

在master节点上输入 jps 查看进程
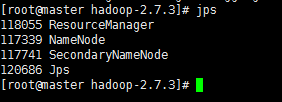
在slave节点上分别输入 jps 查看进程

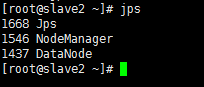
出现以上进程则为成启动成功
为验证是否Hadoop启动成功,请在同局域网下的浏览器下输入
master:50070 (有部分情况显示解析不了 则把master换成master节点机器的ip地址)
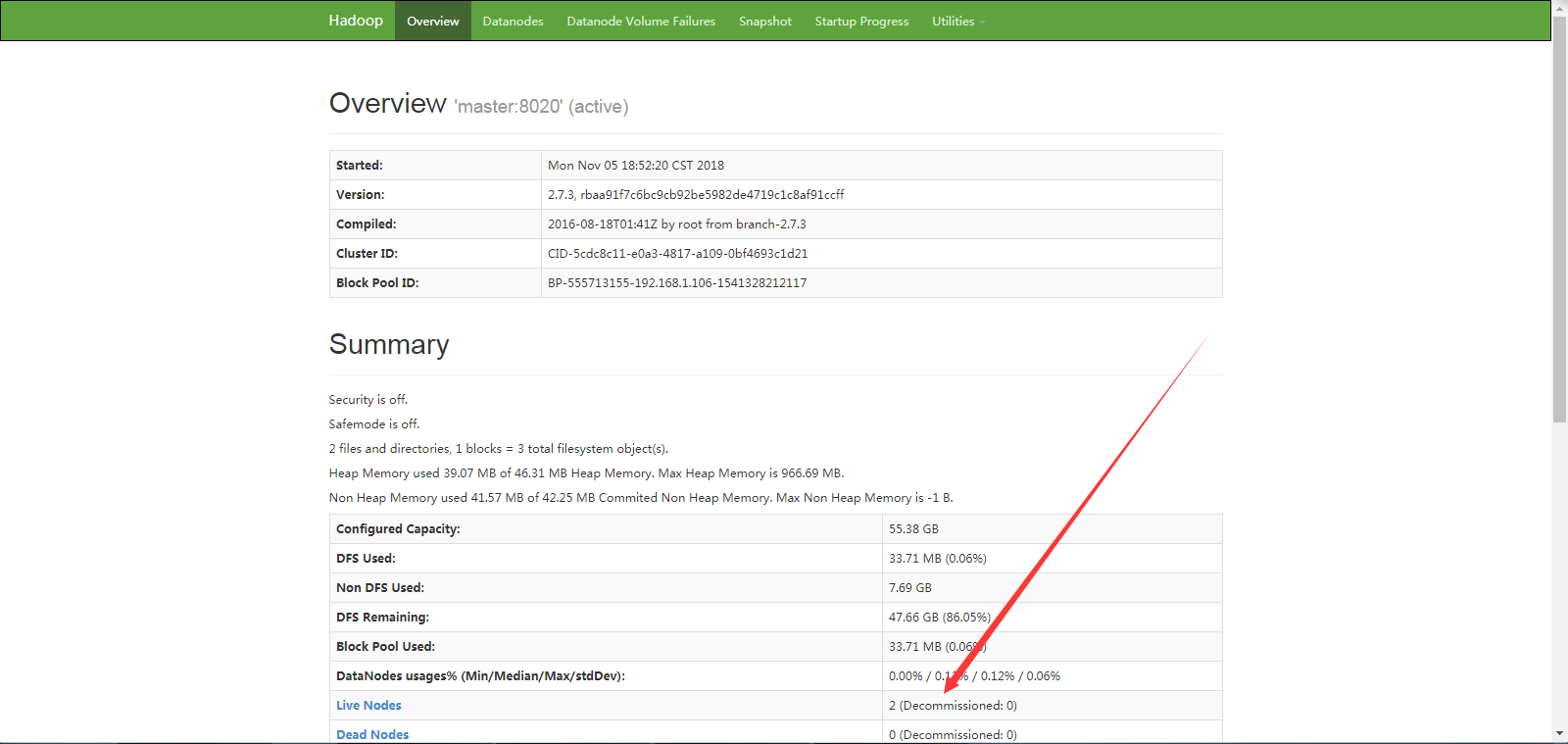
可以发现 存活的节点 数量为 2 。可是我们是三台机器
开始排查错误
打开web管理界面的 DataNode

查看存活的节点

可以发现 slave1, slave2 。节点存活正常,而管理界面可以打开,则master的namenode为正常,因无数据 则 DataNode 可能没有启动
我们单独先启动DataNode进程
首先进入Hadoop目录下
输入以下命令:
sbin/hadoop-daemon.sh start datanode

启动完成,我们jps查看以下启动的进程,看看DataNode启动没有

可以发现 DataNode启动成功,我们打开web管理界面 刷新看看有没有master节点
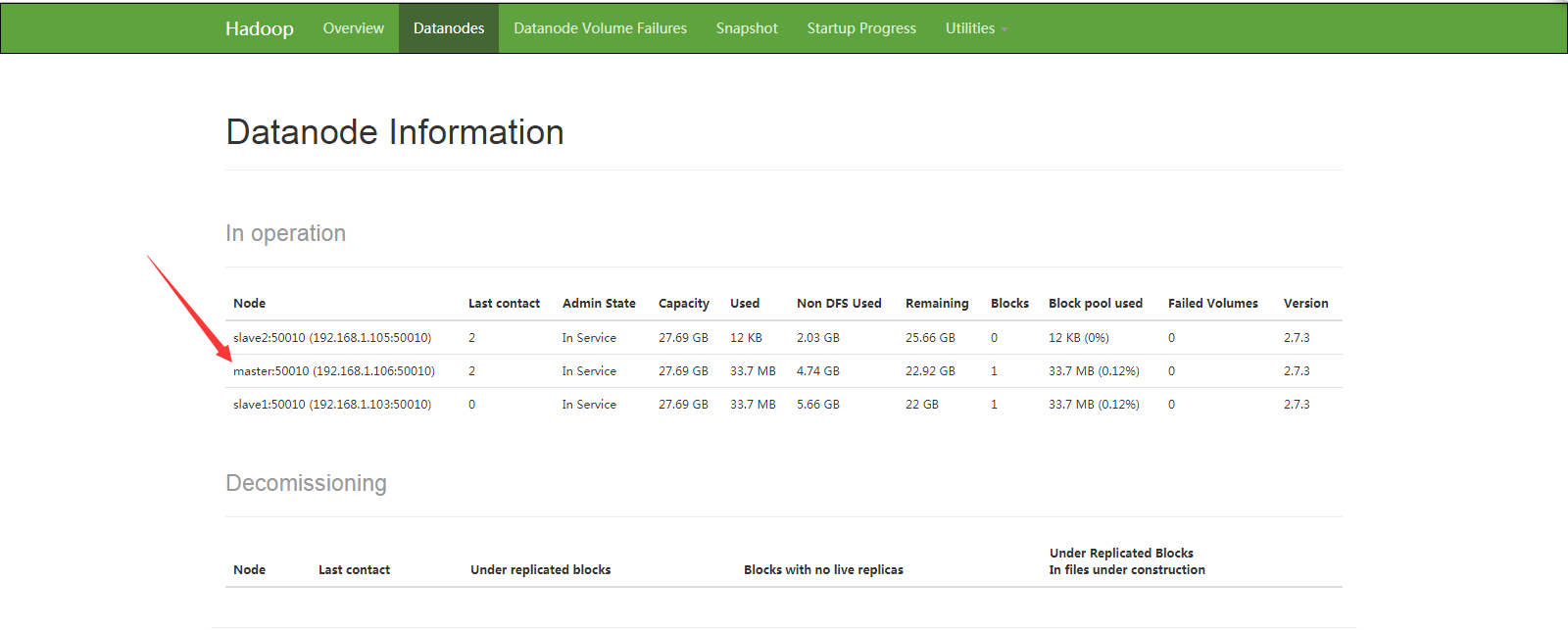
可以看到 master(主节点)启动成功;
现在打开yarn管理界面
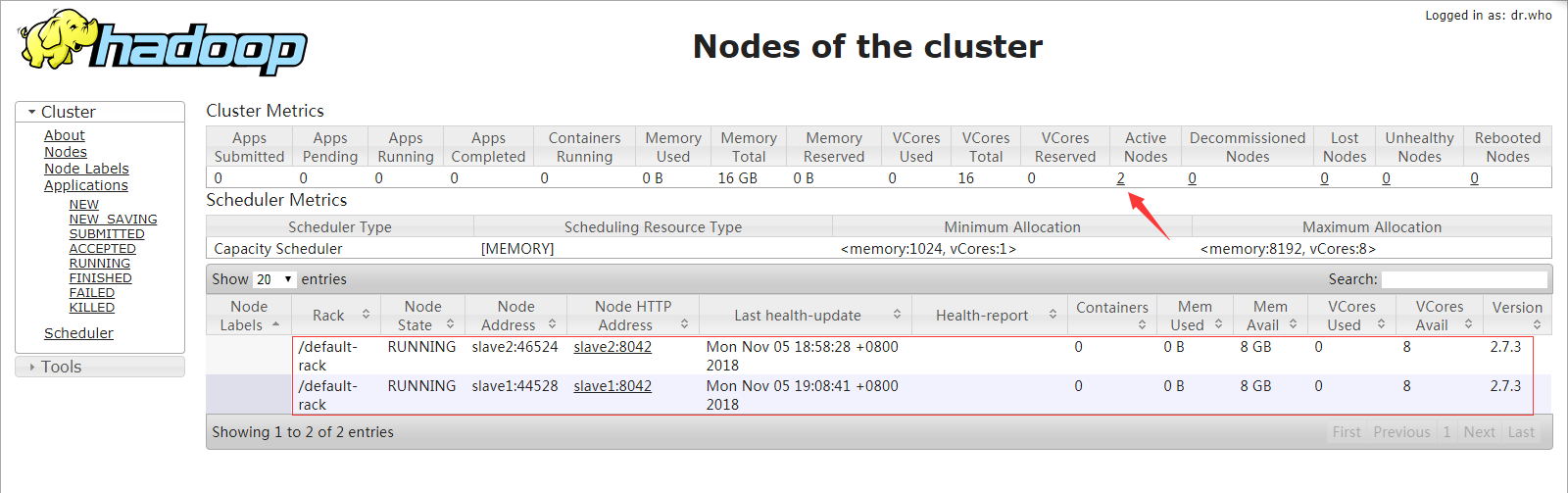
存活节点为 2 节点 slave1,slave2,都为正常
Hadoop停止
首先进入Hadoop安装目录下
sbin/stop-all.sh
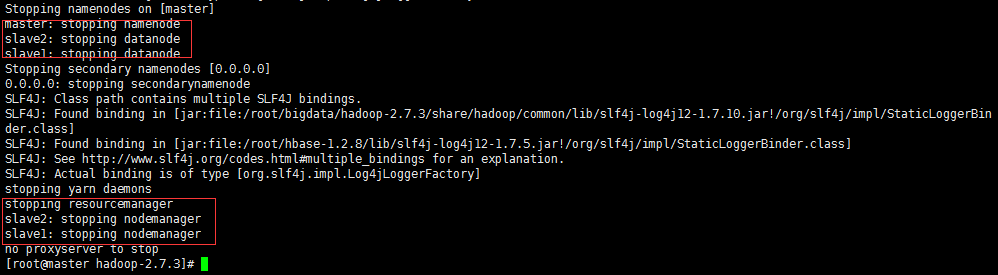
出现次情况则停止成功!!!此外 我们刚才单独启动了 DataNode 我们再次 jps 查看一下进程


可以看出 master 节点上 DataNode 没有停止。slave节点上都正常停止。
接下来我们单独 关闭 DataNode 节点

master slave 节点进程全部关闭完成!!(在关机前必须得关闭所有的进程!!!)
至此 Hadoop安装完成安装 谢谢!!