一、Prometheus简介
Prometheus是一套开源的系统监控报警框架。Prometheus作为新一代的云原生监控系统,相比传统监控监控系统(Nagios或者Zabbix)拥有如下优点。
易管理性
Prometheus: Prometheus核心部分只有一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
Nagios: 需要有专业的人员进行安装,配置和管理,并且过程很复杂。
业务数据相关性
Prometheus:监控服务的运行状态,基于Prometheus丰富的Client库,用户可以轻松的在应用程序中添加对Prometheus的支持,从而让用户可以获取服务和应用内部真正的运行状态。
Nagios:大部分的监控能力都是围绕系统的一些边缘性的问题,主要针对系统服务和资源的状态以及应用程序的可用性。
另外Prometheus还存在以下优点:
高效:单一Prometheus可以处理数以百万的监控指标;每秒处理数十万的数据点。
易于伸缩:通过使用功能分区(sharing)+联邦集群(federation)可以对Prometheus进行扩展,形成一个逻辑集群;Prometheus提供多种语言的客户端SDK,这些SDK可以快速让应用程序纳入到Prometheus的监控当中。
良好的可视化:Prometheus除了自带有Prometheus UI,Prometheus还提供了一个独立的基于Ruby On Rails的Dashboard解决方案Promdash。另外最新的Grafana可视化工具也提供了完整的Proetheus支持,基于Prometheus提供的API还可以实现自己的监控可视化UI。
二、Prometheus框架的组成和工作流
2.1 Prometheus的框架组成
Prometheus的框架如下图(参考自Prometheus官网)
Prometheus Server:Prometheus Sever是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储及查询。Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Sever需要对采集到的数据进行存储,Prometheus Server本身就是一个实时数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。Prometheus Server对外提供了自定义的PromQL,实现对数据的查询以及分析。另外Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据。
Exporters:Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可以获取到需要采集的监控数据。可以将Exporter分为2类:
直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
间接采集:原有监控目标并不直接支持Prometheus,因此需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如:Mysql Exporter,JMX Exporter,Consul Exporter等。
AlertManager:在Prometheus Server中支持基于Prom QL创建告警规则,如果满足Prom QL定义的规则,则会产生一条告警。在AlertManager从 Prometheus server 端接收到 alerts后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,webhook 等。
PushGateway:Prometheus数据采集基于Prometheus Server从Exporter pull数据,因此当网络环境不允许Prometheus Server和Exporter进行通信时,可以使用PushGateway来进行中转。通过PushGateway将内部网络的监控数据主动Push到Gateway中,Prometheus Server采用针对Exporter同样的方式,将监控数据从PushGateway pull到Prometheus Server。
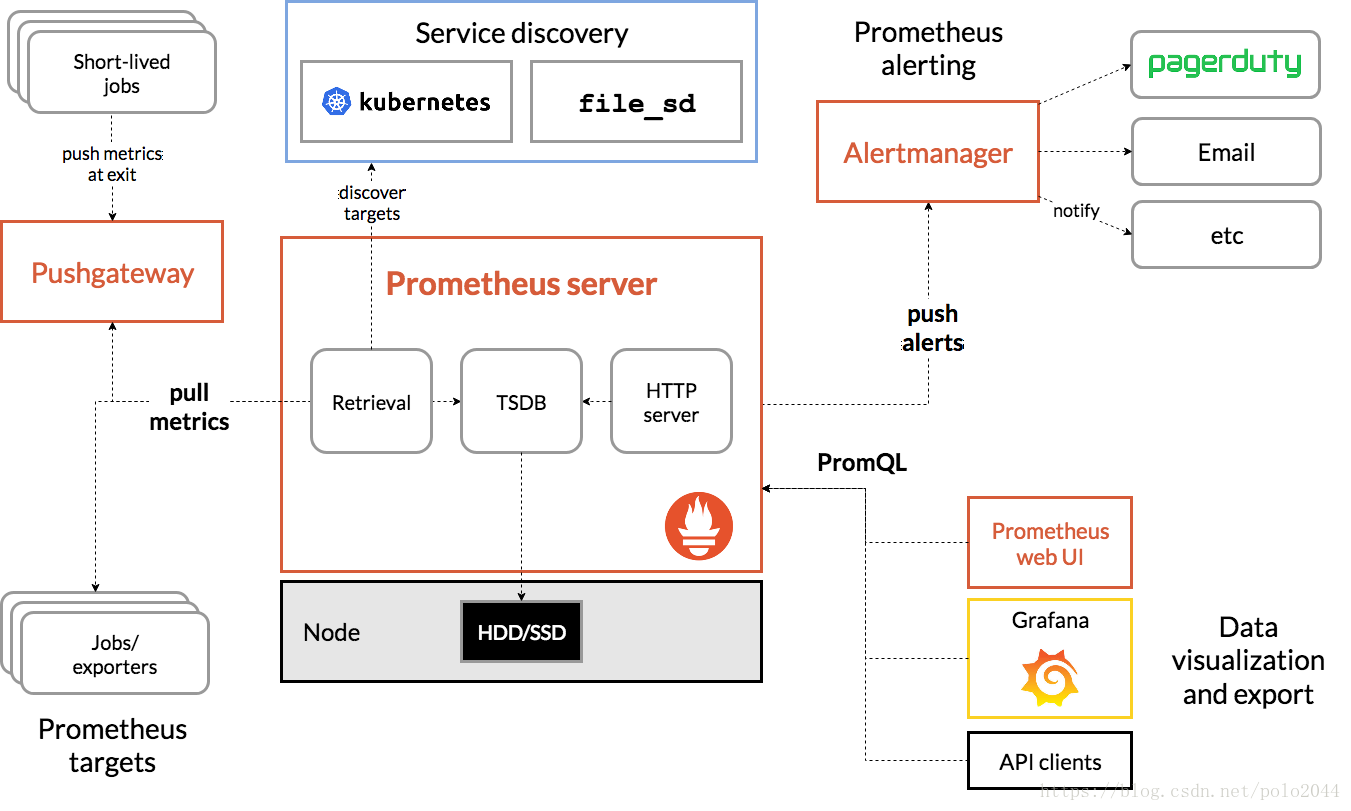
2.2 Prometheus的工作流:
1.Prometheus server定期从配置好的jobs或者exporters中拉取metrics,或者接收来自Pushgateway发送过来的metrics,或者从其它的Prometheus server中拉metrics。
2.Prometheus server在本地存储收集到的metrics,并运行定义好的alerts.rules,记录新的时间序列或者向Alert manager推送警报。
3.Alertmanager根据配置文件,对接收到的警报进行处理,发出告警。
4.在图形界面中,可视化采集数据。
三、Prometheus的安装和配置
3.1 Prometheus的安装
Prometheus的安装有两种方式:1.从官网下载Prometheus镜像进行安装;2.从 docker上获取镜像进行安装。
从官网下载Prometheus镜像进行安装
wget https://github.com/prometheus/prometheus/releases/download/v2.3.2/prometheus-2.3.2.linux-amd64.tar.gz
tar txvf prometheus-2.3.2.linux-amd64.tar.gz
cd prometheus-2.3.2.linux-amd64.tar.gz
./prometheus --config.file=prometheus.yml
从Docker获取镜像进行安装
docker pull prom/prometheus
3.2 Prometheus的配置
Prometheus运行的命令配置参考如下:
docker run -p 9090:9090 -v /tmp/prometheus.yml:/etc/prometheus/prometheus.yml \
-v /tmp/first.rules:/etc/prometheus/first.rules \
-v /tmp/prometheus-data:/prometheus-data \
prom/prometheus
备注:Prometheus在运行过程中会出现各种不同的bug,关于bug的问题和解决方案可以参考博客Prometheus配置过程中出现的bug及解决方案
Prometheus配置文件的规范和解析
Prometheus的配置文件采用的是yaml文件,yaml文件书写规范要求如下
1.大小写敏感
2.使用缩进表表示层级关系
3.缩进时不允许使用tab键,只允许使用空格
4.缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
Prometheus的配置文件解析如下:
# Prometheus全局配置项
global:
scrape_interval: 15s # 设定抓取数据的周期,默认为1min
evaluation_interval: 15s # 设定更新rules文件的周期,默认为1min
scrape_timeout: 15s # 设定抓取数据的超时时间,默认为10s
external_labels: # 额外的属性,会添加到拉取得数据并存到数据库中
monitor: 'codelab_monitor'
# Alertmanager配置
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"] # 设定alertmanager和prometheus交互的接口,即alertmanager监听的ip地址和端口
# rule配置,首次读取默认加载,之后根据evaluation_interval设定的周期加载
rule_files:
- "alertmanager_rules.yml"
- "prometheus_rules.yml"
# scape配置
scrape_configs:
- job_name: 'prometheus' # job_name默认写入timeseries的labels中,可以用于查询使用
scrape_interval: 15s # 抓取周期,默认采用global配置
static_configs: # 静态配置
- targets: ['localdns:9090'] # prometheus所要抓取数据的地址,即instance实例项
- job_name: 'example-random'
static_configs:
- targets: ['localhost:8080']
Prometheus模块定义的告警规则如下
groups:
- name: test-rules
rules:
- alert: InstanceDown # 告警名称
expr: up == 0 # 告警的判定条件,参考Prometheus高级查询来设定
for: 2m # 满足告警条件持续时间多久后,才会发送告警
labels: #标签项
team: node
annotations: # 解析项,详细解释告警信息
summary: "{{$labels.instance}}: has been down"
description: "{{$labels.instance}}: job {{$labels.job}} has been down "
value: {{$value}}
参考:
1.prometheus官网
2.Prometheus操作指南
3.Prometheus 入门与实践
4.Prometheus 和 Alertmanager实战配置
5.使用Prometheus+grafana打造高逼格监控平台