最近学习容器和集群,别人推荐XXXXXXX,我说我在看官方的swarm,都说不推荐。不推荐是一回事,官方能搞出来并没把他删掉,证明肯定有使用场景。所以学习一下,学到哪记到哪,当中也有百度里找的资料,我相信我这篇是集各百度之所长,一些无实际用的也就不写出来的。
环境是centos7.5 ,docker是yum安装的1.13
##开启转发功能
vi /etc/sysctl.conf
net.ipv4.ip_forward=1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-arptables = 1
sysctl -p
#安装1.13docker服务
yum remove -y docker*
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
sudo yum install docker -y
修改/etc/sysconfig/docker文件
# 将--selinux-enabled设置为false,不然可能会由于selinux服务不能用导致docker启动失败
OPTIONS='--selinux-enabled=false --log-driver=json-file --signature-verification=false'
##修改docker存储目录(默认var/lib/docker不合适正式环境#
#通过disable enable 查看docker配置文件
[root@localhost _data]# systemctl disable docker
Removed symlink /etc/systemd/system/multi-user.target.wants/docker.service.
[root@localhost _data]# systemctl enable docker
Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /usr/lib/systemd/system/docker.service.
##修改/usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd-current \
-g /data/docker \ ##更换路径
--add-runtime docker-runc=/usr/libexec/docker/docker-runc-current \
--default-runtime=docker-runc \
##重载配置
systemctl daemon-reload
##重启服务 ##修改后原有信息不会保留已经跑的业务注意迁移
systemctl restart docker
systemctl enable docker && systemctl start docker
建议先修改独立唯一的主机名
# 在A机器创建集群
docker swarm init --advertise-addr 本机内网IP
#在A机器
docker swarm join-token (manager|worker) 输出 以什么身份的加入集群的token值
#在B机器输入
docker swarm join --token SWMTKN-1-2ftsa277uecm0edb238e9a84h34ifarknitkn9yrqzn1wnafdb-71xjwcjhpzubgqts0ou73h3m9 192.168.0.140:2377
加入A机器的集群
###删除集群
docker swarm leave --force
docker node --help (节点相关
docker service --help(容器相关
docker service rm NAME (此命令删除运行中容器无需确认,谨慎使用
#查看指定节点上运行的service
docker node ps docker123
#把名为nginxtest的nginx容器创建到hostname为docker123的node上。(constraint 参数可以指定多个不同的hostname的节点)
docker service create --replicas 1 --constraint node.hostname==docker123 --name nginxtest nginx
#在集群中创建4个副本 名为test123的 alpine 容器,并执行参数ping docker.com
docker service create --replicas 4 --name test123 alpine ping docker.com
#给node ID为“hbex1b6iw7wfjsushdbot9gfs ” 添加nginx标签 (ID参数也可使用hostname)
docker node update --label-add func=nginx hbex1b6iw7wfjsushdbot9gfs
#把nginx容器创建到带nginx标签的node上。
docker service create --name my_testnginx --constraint 'node.labels.func == nginx' nginx
#查看节点标签
docker node inspect hostname
#删除标签
docker node update --label-rm func hostname
#把docker123节点排除掉 并停用该节点上所有容器,将这些容器移动到别的可用节点上
docker node update --availability drain docker123
#把docker123节点排除掉不再分配任务,但允许已运行的容器继续运行。
docker node update --availability pause
#恢复为可用状态 允许任务被分配到该节点上
docker node update --availability Active docker123
# 减少服务副本,增加服务副本
docker service scale SERVICE=副本数量
##docker swarm无法常规重启单个副本容器(副本容器通过docker ps也可以查看到,也可以用docker restart ID的方式重启,但是一旦操作该副本会转移到其他可用节点上,并且本机器会不停尝试启动该副本,不建议操作)
##在学习这块的时候因为没有接触过集群,百度的时候一直搜索重启集群容器,然而在swarm的环境中没有“重启”这个名词,官方文档解释的也极其简单,作为一个傻瓜式的教程(不,可能傻瓜的是我。。)还是在此说明,swarm集群只有“更新”的概念,update就是重启。修改完容器内的配置后,可以使用以下命令更新。
#强制更新,一次更新1个副本,每隔30秒更新下一个副本 更新服务myweb
docker service update --force --update-parallelism 1 --update-delay 30s myweb
###不采用挂载目录的情况下如何把文件拷入容器
#显示test123服务的全部ID
docker service ps test123 -q
#显示该服务的信息
docker service ps test123
#找到对应副本的对应ID
docker ps查看本机docker id,再用 docer cp 本机目录 容器ID:容器目录 的方式把包放到集群的容器里
在使用docker的过程中发现基于swarm使用Storage Driver: overlay的方式进行存储.但是发现这个特别占用存储空间.
清理所有停止的容器
docker container prune
清理所有不用数据(停止的容器,不使用的volume,不使用的networks,悬挂的镜像)
docker system prune -a
# type=volume,将容器目录映射到卷存储上。docker volume create创建出的卷,可用在此处。
#如果拷贝war文件到该卷后 再重启某节点docker服务 该节点容器恢复后 使用的卷新增的文件不会被删除。
#以下面为例,4个副本,2个副本在A节点,A节点如果进入某个容器的shell环境删除了 该卷下的一个tomcat自带文件,则两个容器里的相应文件都会被删除,且重启docker服务后该文件不会生成。
##换言之 用了挂载卷后,相当于对应容器的副本 共用同一个卷,且数据全部存在本地磁盘上 而非容器里,可以理解为容器里的该目录只是磁盘的一个映像。
docker service create --mount src=tomcatdata,dst=/usr/local/tomcat/ --name myweb --publish 80:8080 --replicas 4 tomcat
#tomcatdata卷会自动创建
#可以使用docker volume inspect tomcatdata 查看卷信息
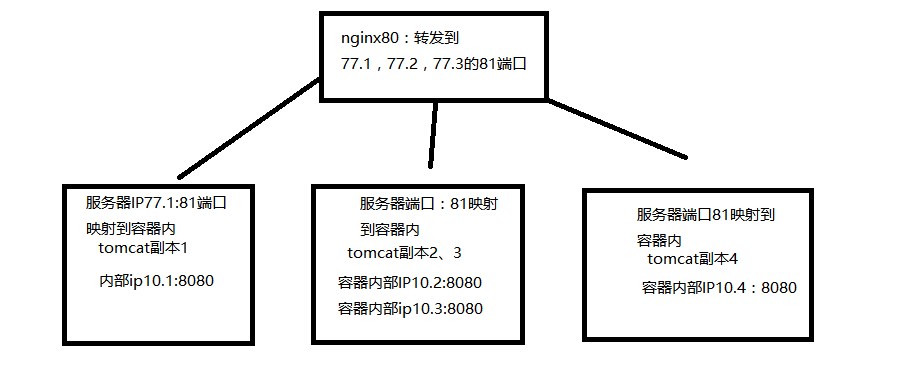
#实测,起了4个副本,分布3个节点,有一个节点是2个副本的,然后请求了4次, 的确是每个副本收到一次访问,两个副本因为挂载的目录相同 所以日志写入在同一个文件里了。
#牛逼的是 #我nginx反向代理是反向到3个节点的81端口,理论上是负载均衡到3个节点的docker对外端口,如果docker集群只是往副本做负载均衡,那么B节点应该不会知道A节点是否访问,可能造成AB两个节点同时转发到同一个副本上导致容器负载不均衡。。
#而docker集群应该是做了处理,不管请求是转发到哪个节点的容器对外端口,转发到后端副本容器的请求 都被负载均衡了。
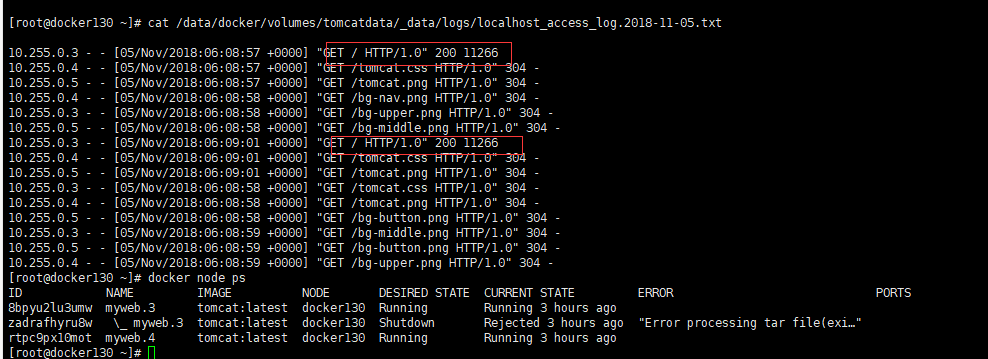
以副本模式的方式起容器,则在一个节点上会存有镜像,在我删除myweb服务后,去三个节点执行
docker system prune -a
命令,会发现只有一个节点删除了400多M的数据,其他的数据都只有几M甚至更少,推测是有一个节点存储镜像,其他节点副本都是通过这个镜像起的,之前测过如果存镜像的节点宕机,发生漂移,会在漂移的目标端下拉新的镜像,在最后清理时会有2个节点有400M的数据被清理,而镜像节点宕机时也不会影响在跑节点。
最后是不同类型的节点重启影响范围:
worker节点重启docker服务时,本节点容器重启,不会影响其他节点。
manager节点重启docker服务时,本节点容器重启,也不会影响其他节点。
manager节点(Leader)重启docker服务时,会造成Leader转移到其他manager节点,本节点容器重启,不会影响其他节点。
线上环境我觉得如果规模不是那种巨型量级的话是可以考虑使用swarm集群的,以挂载卷的方式启动容器,然后用rsync同步所有tomcat的目录(排除日志目录)。
目前尚待验证的几个问题:
1.如果我节点出现异常,容器漂移后 等节点恢复 如何把容器重新平均分布(用减少副本和增加副本的方法试过,不过感觉应该有更好的方法)
2.假设上面的例子 其中的2副本节点宕机的情况下 两个副本是否会转移到同一个节点上,如果转移到同一个节点,那么一个节点有3个副本,到时候会否导致一个节点承载了75%的量,另一个只有25%。
如有人知道以上问题的还请帮助解答下,谢谢。