Spark是一个快速且通用的集群计算框架
一、Spark的特点
1.Spark是快速的:
Spark扩充了流行的MapReduce计算框架
Spark是基于内存的计算
2.Spark是通用的:
Spark的涉及容纳了其他分布式系统拥有的功能:批处理、迭代式计算、交互查询和流处理等
其优势是:降低了维护的成本
3.Spark是高度开放的:
Spark提供了Python、Java、Scala、SQL的API和丰富的内置库
二、Spark的组件
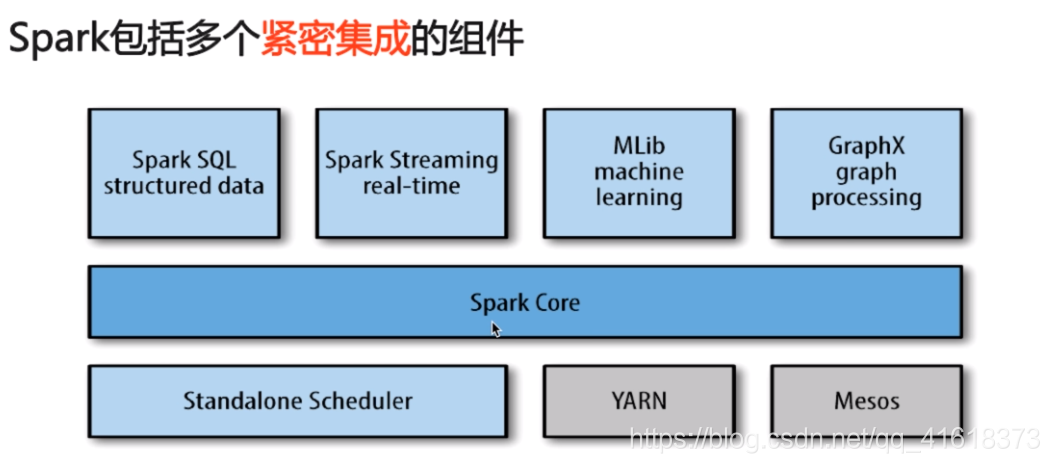
1.Spark core:
包含Spark的基本功能,包含任务调度,内存管理,容错机制等
内部定义了RDDs
提供了很多APIs来创建和操作这些RDDs
应用场景:为其他组件提供底层服务
2.Spark SQL:
是Spark处理结构化数据的库,就像Hive SQL,Mysql一样
应用场景:企业中用来做报表的统计
3.Spark Streaming:
是实时数据流处理组件,类似Storm
Spark Streaming提供API来操作实时数据流
应用场景:企业中用来从kafka接受数据做实时统计
4.Mlib:–机器学习
5.Graphx:–处理图
6.Cluster Managers:
就是集群管理,Spark自带一个集群管理,是单独调度器
常见的集群内管理包括:Hadoop YARN,Apache Mesos
7.密集集成优点:
Spark底层优化了,基于Spark底层的组件,也得到了相应的优化
紧密集成,节省了各个组件组合使用时的部署,测试等时间
向Spark增加新的组件时,其他组件,可立刻享用新组件的功能
三、Spark与Hadoop的比较——应用场景的比较
1.Hadoop的应用场景:离线处理、对时效性要求不高
2.Spark的应用场景:时效性要求高的场景,机器学习等领域
3.比较:(中立的观点)
这是一个生态系统,每个组件都有其作用,各善其职即可
Spark不具有HDFS的存储功能,要借助HDFS等持久化数据
大数据将会孕育除更多的新技术
四、通过命令行执行Spark——WordCount
1.启动Spark:spark-shell --master local[2]
2.spark实现word count
1)读取数据:var file=sc.textFile(“file:///home/hadoop/data/hello.txt”)
2)拆分每一行:var a=file.flatMap(line=>line.split(" "))
3)为每个单词赋上1,用于计数:var b=a.map(word=>(word,1))
4)将相同单词的计数加和:var c=b.reduceByKey(_ + _)
上述执行,可以通过下面这一条语句执行,得到相同的结果:
sc.textFile(“file:///home/hadoop/data/hello.txt”).flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_ + _).collect
五、通过idea写好Spark程序,打包,在集群上执行
1.在虚拟机上使用Spark时,同样需要配置ssh免密登陆,同hadoop的配置相同,每台虚拟机仅需要配置一次即可
2.写好程序后,需要打成jar包,这里介绍使用idea打jar包
file->project structure->artifacts->左上角加号->jar->选择下面的那个->要打包的项目名->main class的名字->上面的选项是连依赖包一起打成jar包/下面的选择是不包含依赖包->apply->ok
3.build->build artifacts->build
4.虚拟机啊启动master和worker:sbin目录下执行:./start-all
5.把jar包copy到集群上:idea上打好的jar包在output中
在C:\Users\PYN\IdeaProjects\scalatrain\out\artifacts\scalatrain_jar 下执行命令:scp scalatrain.jar hadoop@***.***.***.***:~/lib
6.提交,运行
在spark目录下执行:
./bin/spark-submit --master local[2] --class com.scala.scala.com.spark.WordCount /home/hadoop/lib/scalatrain.jar