一、exists和in - - - 小表驱动大表
前言: 500*10000和10000*500,在数学角度来说是没什么区别的,从java角度来说是这样的:
for(int i=0;i<500;i++){
for(int j;j<10000;j++){
}
}和
for(int i=0;i<10000;i++){
for(int j;j<500;j++){
}
}但是对于mysql来说是有区别的。这关系到连接和释放的次数。
简介: exists和in到底谁性能好是没有绝对一说的,这需要看表数据的大小。
in: SELECT * FROM dept where deptno in (SELECT deptno FROM emp )这句sql,在mysql翻译之后是这样的:
for(SELECT deptno FROM emp) {
for(SELECT * FROM dept where emp.deptno =dept.deptno){
}
}exists: SELECT * FROM dept where EXISTS (SELECT 1 FROM emp where emp.deptno =dept.deptno)这句sql,在mysql翻译之后是这样的(这里的1可以换成任意常量,比如A、a之类的):
for(SELECT deptno FROM dept ) {
for(SELECT * FROM dept where emp.deptno =dept.deptno){
}
}分析: 如果使用in,则需要连接emp的条数次;如果使用exists,则需要连接dept 的条数次。
案例:向emp中插入100万条记录,向dept表中插入5万条记录。
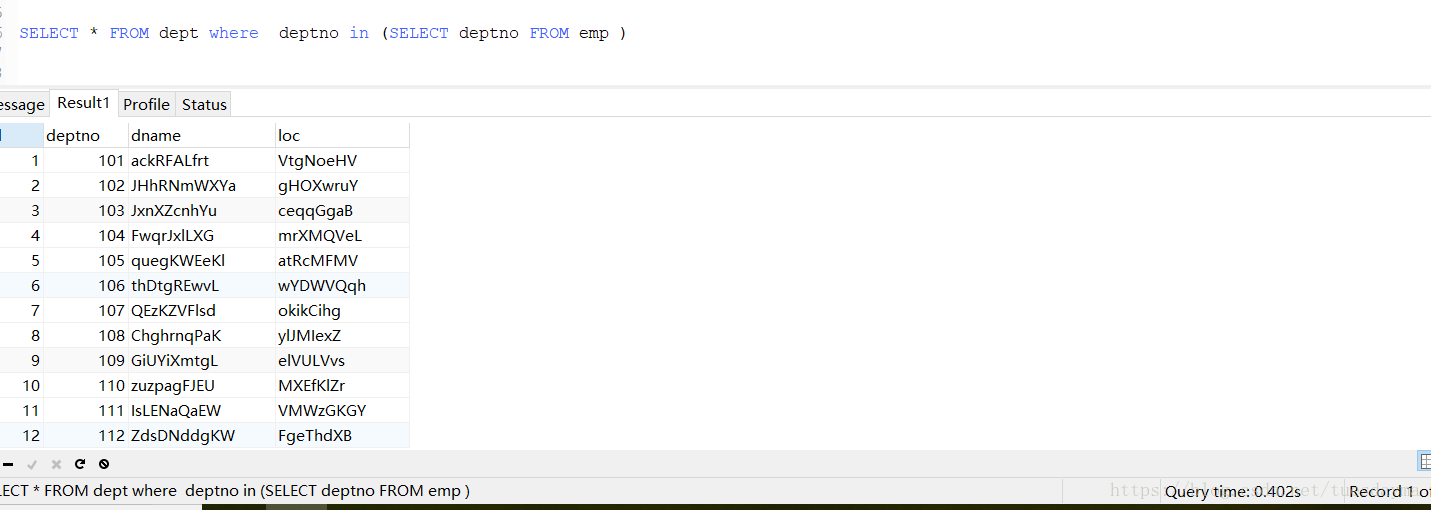
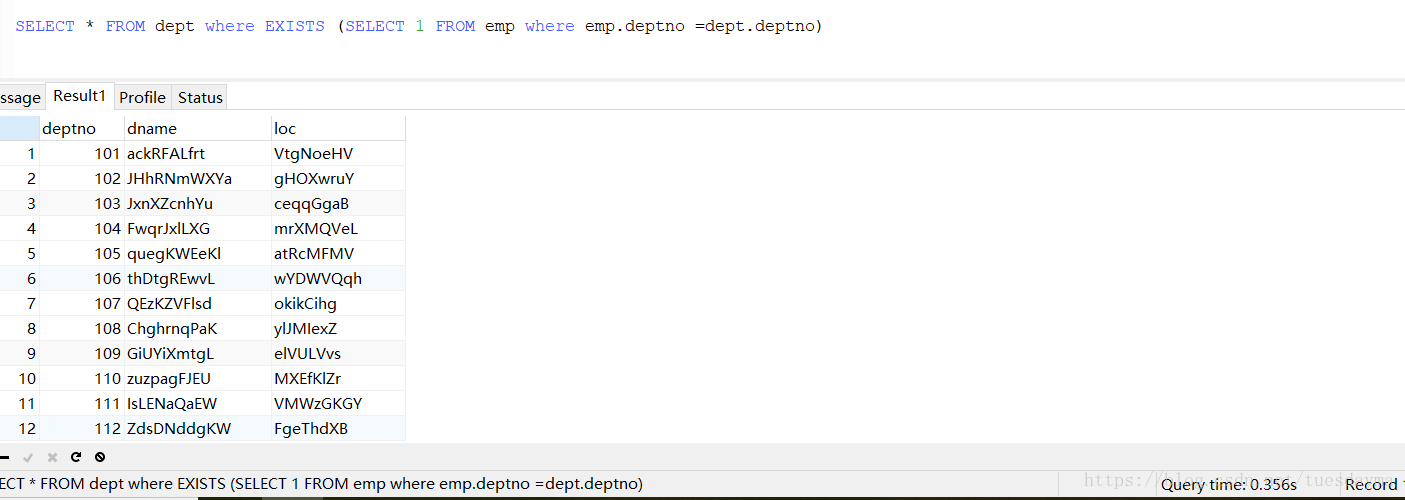
结论: emp表比dept表小的时候使用in,emp表比dept表大的时候使用exists。即:内小in,外小exists。
二、order by 之 filesort
简介: order by的排序总共有两种,一种是使用索引(index)进行排序,还有一种是没法使用索引进行排序的,称为filesort排序(文件排序)。using index效率比using filesort高。
准备工作:
CREATE TABLE test01 (
c1 varchar(3) ,
c2 varchar(3),
c3 varchar(3),
c4 varchar(3)
);
create index c1c2c3 on test01(c1,c2,c3);
insert into test01 values('a1','a2','a3','a4');
insert into test01 values('b1','b2','b3','b4');几种常见的场景:
1、只有order by 没有where条件:这个可能其他版本的mysql是不会产生filesort的(因为我看到网上说这种情况是不会产生的),我也没试过,但是mariadb的10.0.17版本是会产生的
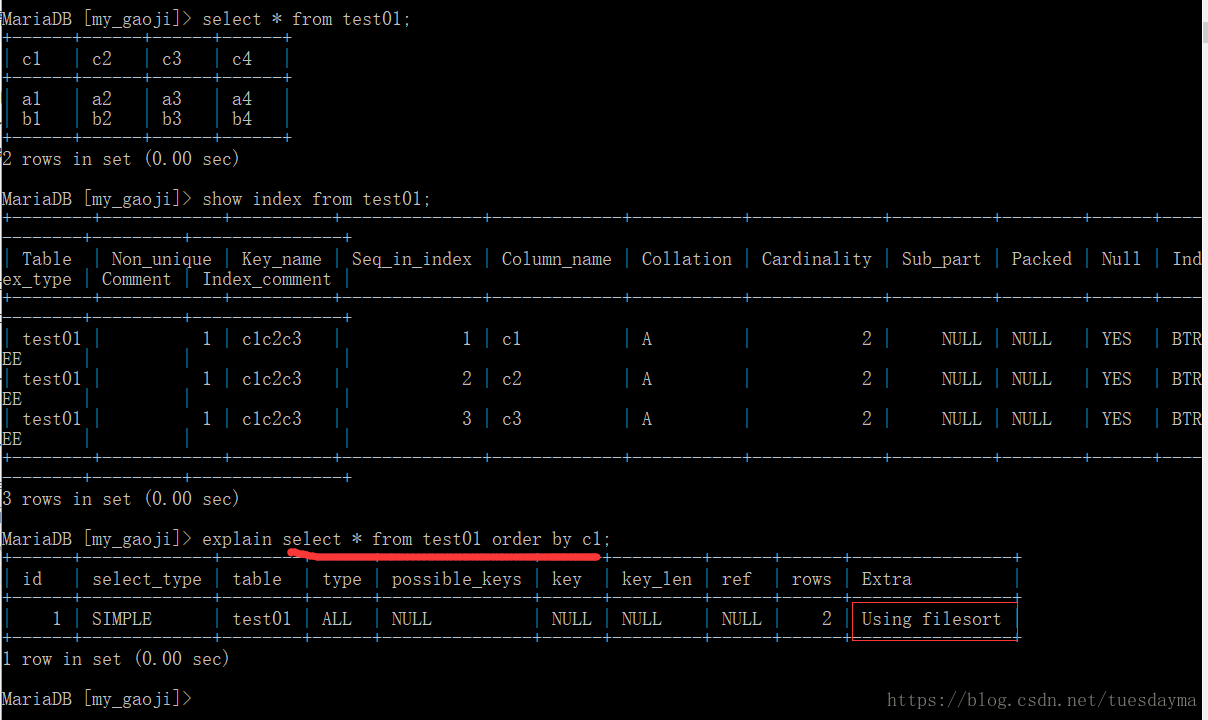

2、where条件中有c1,但是order by中没有c1,只有c2和c3

3、where 条件中有c1 ,但是order by中只有c3: 这个就属于中间兄弟丢了

4、where条件中有c1,但是order by中没有c1,只有c2和c3,而且c2正序,c3倒序:必须同正同逆

5、where条件中有c1,order by中有c1、c2和c3,但是order by c1 ,c3,c2:必须要和复合索引字段顺序一致

6、where 条件中有c1 ,但是c1的条件是个范围,order by中只有c2和c3: 范围之后全失效

7、where 条件中有c1 ,但是c1的条件是个范围,order by中有c1、c2和c3:

8、where条件中没有c1,有c2,但是order by中有c1:这个可能不同版本之间也有不同的答案

9、where条件中没有c1,但是order by中也没有c1,只有c2和c3: 这个就属于带头大哥死了

总结: 产生filesort的原因主要有:
1、带头大哥或者中间兄弟丢了。
2、order by之后的字段顺序和复合索引中的字段顺序不一致。
3、没有where条件(不同版本的mysql可能不一样)
4、尚硅谷总结图:

filesort的两种算法:双路排序和单路排序
双路排序: mysql在4.1之前使用的都是双路排序,字面的意思就是两次扫描磁盘,最终得到数据。即:读取行指针和order by 列,对他们进行排序,然后扫面已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出。简单来说就是:从磁盘中读取需要排序的字段,在buffer中进行排序,然后再从磁盘中读取其他字段。
单路排序: 双路排序需要读取两次磁盘,但是i/o是非常消耗内存和时间的,所以,能不能将读取磁盘的时间减少为1次呢?于是就有了单路排序:从磁盘中读取查询需要的所有列,按照order by列在buffer中对他们进行排序,然后扫描排序之后的列表进行输出,他的效率要比双路快,因为他将每一行的所有字段都保存在了内存中。
单路排序的缺点: 因为单路是将所有的字段都放在了内存中,假如,这张表是在太大,大的超过了sort_buffer这个值了,那么每次都只能取sort_buffer的数据,来进行排序(会创建临时tmp文件,然后多路合并),相当于多路了,这样一来效率比双路还要差。
优化单路:
1、尽量少用select *,想要那个字段就查那个。
2、在配置文件中增大sort_buffer_size 参数的值。
3、适当调大max_length_for_sort_data,这个值将会决定filesort使用哪种算法,如果查询的字段大小综合小于这个值,那么将会使用单路算法,否则使用双路算法。但是如果设置的太高,因为单路算法是查询所有字段,这样就会导致单路超过sort_buffer_size的可能性增大,从而产生单路的缺点。
三、group by 之 temporary
简介: 分组之前必排序,换句话说,有using temporary 的地方必定有using filesort。using temporary 的意思就是创建临时文件,using filesort的意思就是使用文件排序,两者都是导致你查询速度变慢的原因。
案例:
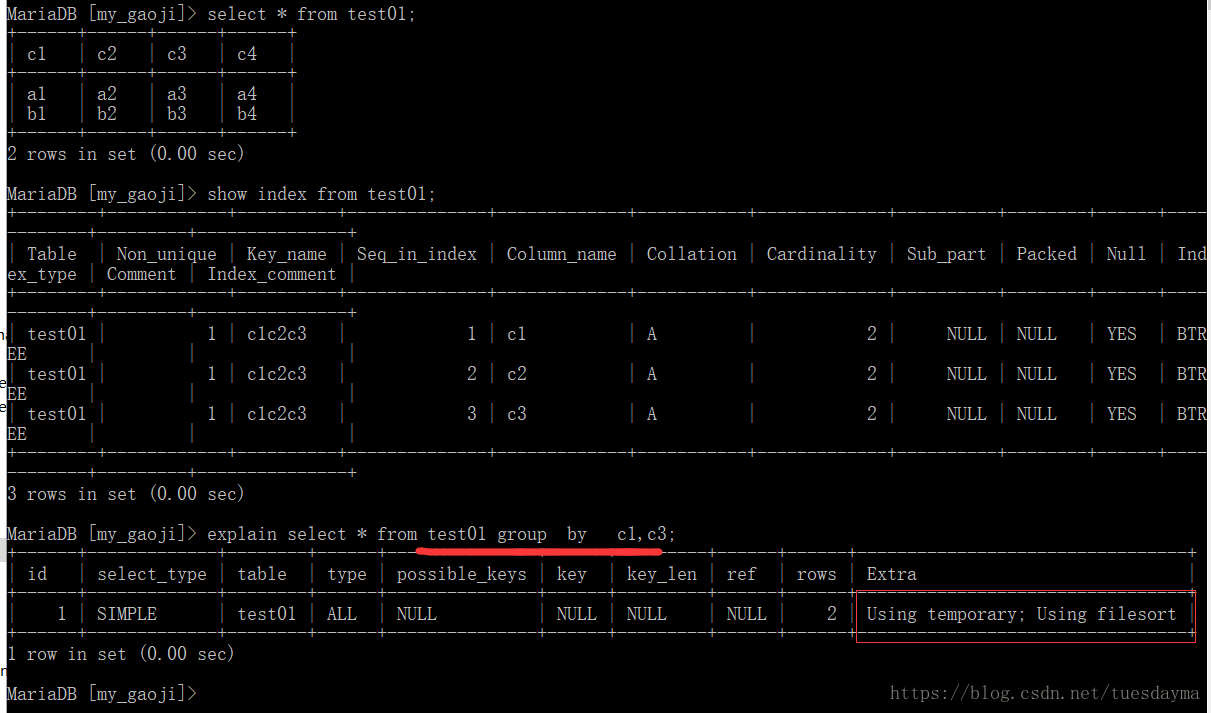
几种常见情况:
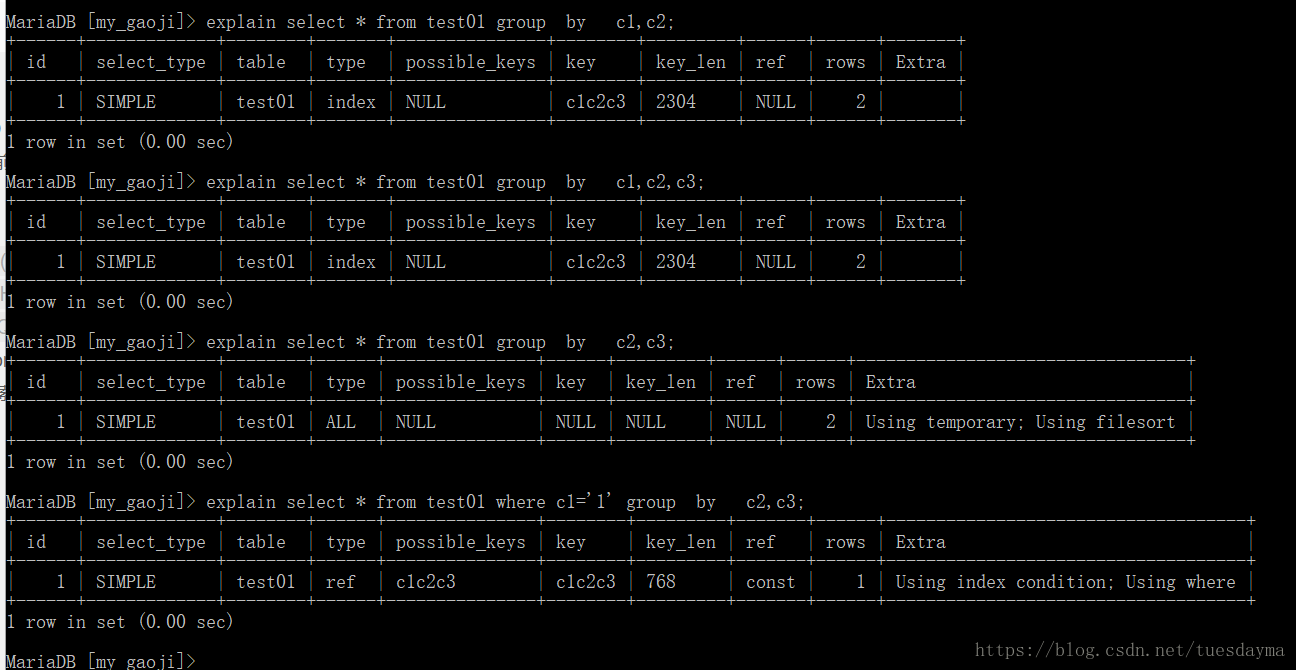
总结: 情况和order by的差不多,只是从using filesort变到了using temporary,优化方式当然是想方设法使用索引来进行排序,当然必要的时候可以修改或者重新创建一个符合需求的索引。
四、慢查询日志分析
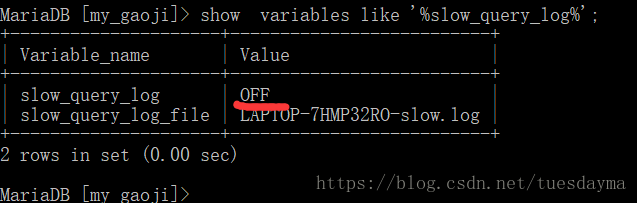
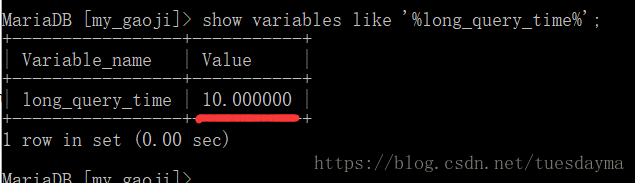
查看是否开启: show variables like ‘%slow_query_log%’; mysql默认是关闭的,需要我们手动去打开。
开启慢查询:
1、本次有效:即重启mysql之后就会失效。set global slow_query_log=1;
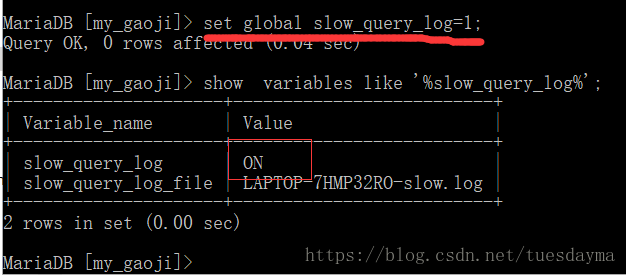
注意:mysql中默认的慢查询时间为10秒,但是生产环境中怎么可能让一条sql执行10秒钟。。。
2、永久有效:即修改配置文件。这里我们配置慢查询的时间为3秒(超过三秒中的查询都会别记录到慢查询日志中)
slow_query_log=TRUE
slow_query_log_file="D:/mariaDB/mariadb-10.0.17-winx64/slow_query_log.txt"
long_query_time=3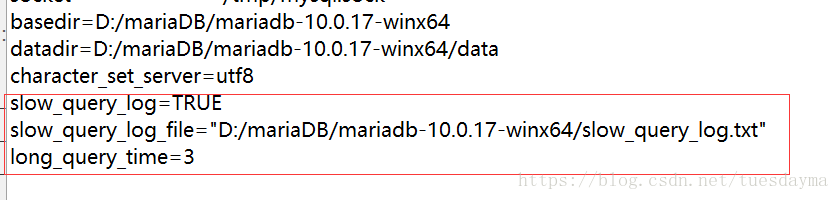
测试: 我们可以写几句sql测试一下。
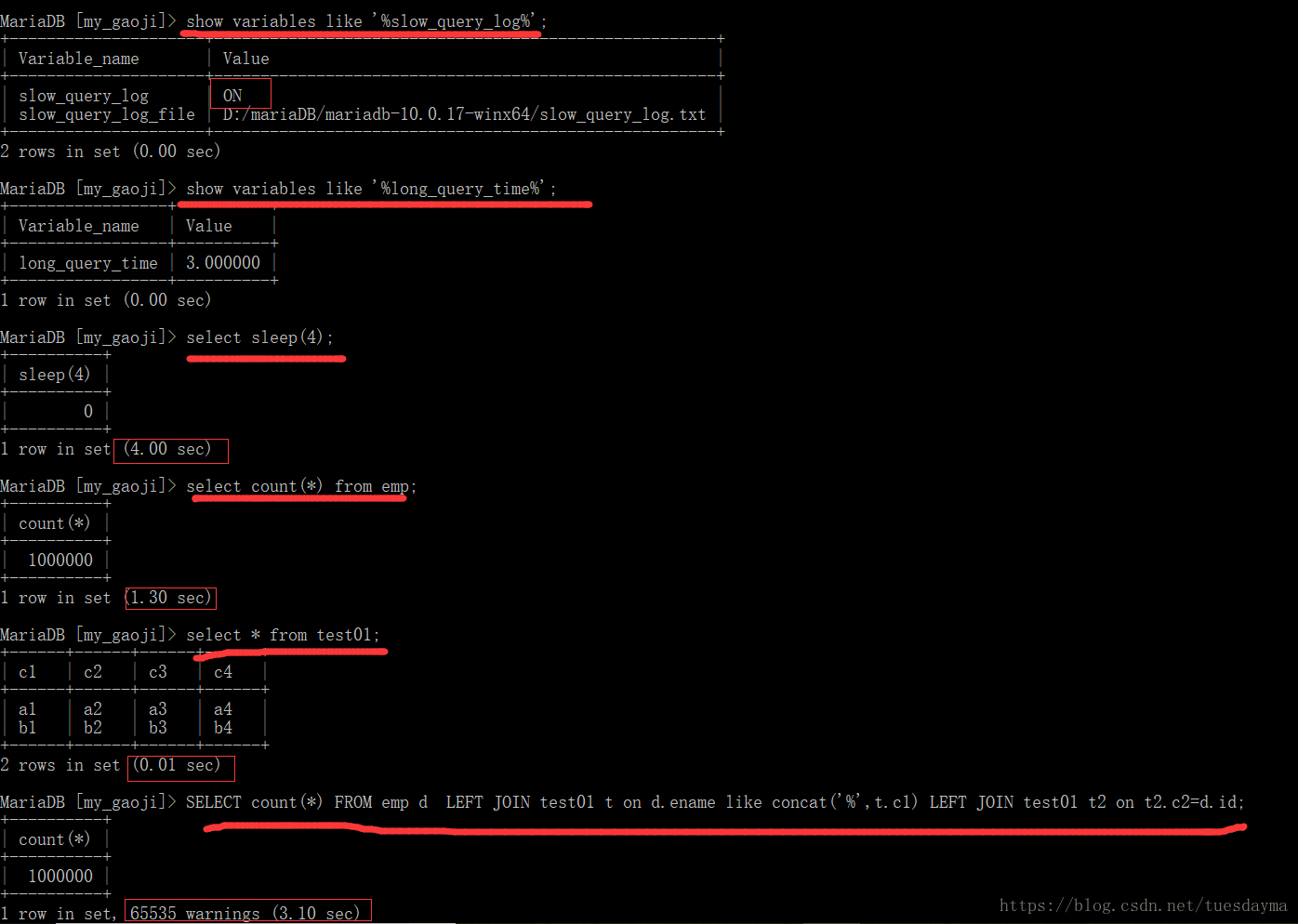
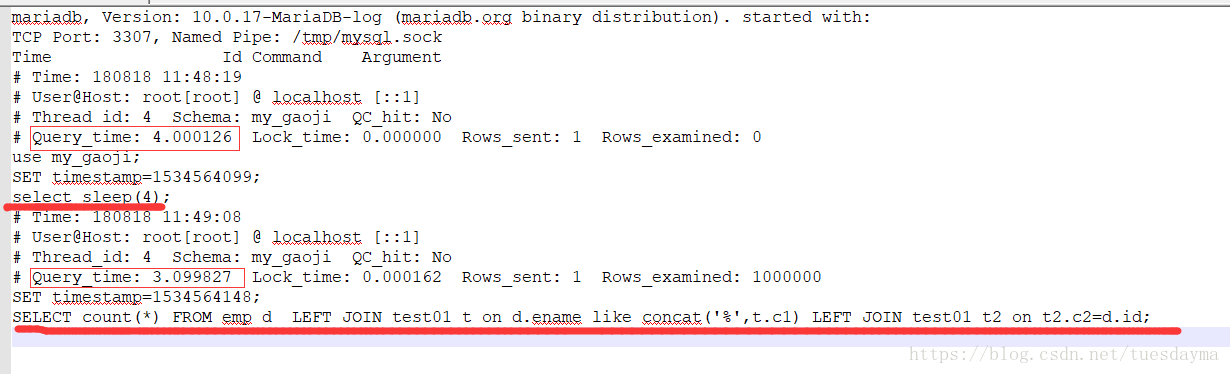
捕获慢查询: select sleep(4) 的意思就是睡眠4秒钟。我们打开慢查询日志文件(slow_query_log.txt),我们可以看到超过3秒钟的sql都被记录了下来。