Redis单线程
redis一次只会执行一条命令,单线程还快的原因
1. redis是纯内存的,内存的响应时间特别快
2. 非阻塞IO
3. 单线程避免了线程切换和竞态消耗
个人感觉主要还是因为内存,响应时间100纳秒。
拒绝长/慢命令 keys,flushall.flushdb,slow lua script ,mutil/exec, operate big value
其实redis也不是完全的单线程,如fysnc file descriptor.
API的理解与使用
通用命令
keys命令 遍历所有key
一般生产环境不用,因为实际情况key太多了。
使用
1. 热备从节点,主节点有从节点都有,可以在从节点使用keys。
2. scan命令
dbsize 看key-value的个数,内置的计数器,不是遍历的,时间复杂度O(1)
exists 是否存在
del 删除指定key-value
expire 过期时间
ttl 查看剩余的过期时间
persist 去掉过期时间
type 返回key类型
数据结构
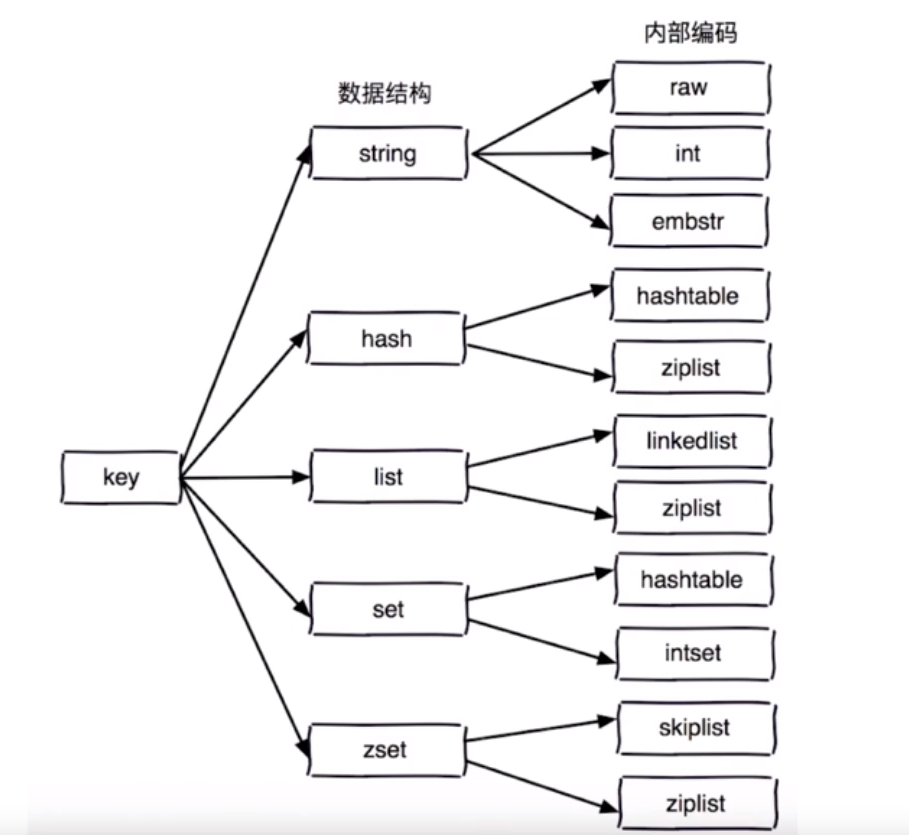
因为内存还是比较贵的,所以使用了很多的压缩数据结构。比如list,redis3.2提出了quicklist,解决了ziplist,linkedlist在某些场景下的性能缺陷,用户不用去关心它的实际情况,只要知道list数据结构的使用方法就可以了。
1. 字符串
字符串value 上限512M,并发和流量的时候不会特别大。
字符串常用在缓存,计数器,分布式锁等等。
操作API get, set, del。
incr,decr,incrby , decrby命令
实战
1. 记录网站每个用户个人主页的访问量? incr userid:pageview
2. 缓存视频的基本信息,数据源在MySQL中
public VideoInfo get(long id) { String redisKey = redisPrefix + id; VideoInfo vidoInfo = redis.get(redisKey); #redis只能取二进制,字符串,不能取对象,这里只是抽象 if(videoInfo == null ) { videoInfo == mysql.get(id); if(videoInfo != null) { redis.set(redisKey, serialize(videoInfo)); } } }
3. 分布式id生成器 原子单线程,incr id
set key value 不管是否存在都设置,
setnx key value不存在才设置 ,
setxx key value存在才设置.
mget 批量获取key,原子操作
mset 批量设置key-value
append key value 将value追加到旧的value
strlen 返回字符串的长度
2. hash
key ---> field value
hash的API都是以 h 开头 hget, hset, hdel, hmget, hmset , hexists, hlen, hgetall(返回hash key 对应所有的field和value) , hvals (返回hash key对应所有field的value),hkeys(返回hash key对应所有field)
例子 hset user:1:info age 23 设置user 1 的info中age 为23
实战 1. 记录网站每个用户个人网页访问量
hincrby user:1:info pageview count
2. 缓存视频信息
Hash就是个小Redis。
3. list
key ----> elements 与Python中类似, 有序,可以重复,可以左右弹出
列表的api
增 rpush 右插入 lpush 左插入 linsert key before| after value newvalue 在某值之前或之后插入新值
删 lpop 左弹出 rpop 右弹出 lrem key count value count > 0 从左到右 删除最多count个value相等的值
count < 0 从右到左,删除最多 -count个value相等的值
count = 0, 删除所有value相等的项
ltrim 按照索引范围修剪列表
查 lrange lrange key start end(包含end)
lindex key index 获得指定索引的item
llen key 获取列表长度
改 lset lset key index newValue 复杂度 O(n)
实战 TimeLine rpush, lpush 很相似,微博页面分页,可以用lrange,每条微博的信息是个实体,微博序列号。
关注的人更新了微博,lpush,
blpop,brpop bloop key timeout # lpop的阻塞版本,timeout为阻塞超时时间
集合set
集合是无序,无重复,支持集合间操作
两集合的关系运算 sinter,sdiff,sunion 交,差,并
实战,我关注的人也关注她,共同关注
集合api以 s开头
sadd ,srem,scard(计算集合大小),sismember(判断是否在集合中),srandmember(睡觉挑一个),spop(随机弹出一个元素)
smembers(获取集合所有元素) 集合较大时,要慎重使用,也是有 sscan
实战: 抽奖, srandmember,
点赞,踩,可以存在集合中
标签,给用户添加标签
有序集合 zset
有序集合相比于集合是有序的,无序中只存element,有序中存element + score
API以z开头
zadd key score element #添加 score和element O(logn)
zrem key element O(1) #删除
zscore key element #返回元素分数
zincrby key increScore element #增加或减少元素的分数 O(1)
zcard key #返回元素的个数 O(1) 有计数器,会自动计数。
zrange 和 lrange相似 zrange key start end [withscores] #返回索引范围的升序元素
zrangebyscore zrangebyscore key minScore maxScore #返回指定分数范围内的升序元素
zcount zcount key minscore maxScore #返回有序集合内在指定分数范围内的个数
zremrangebyrank # 删除指定排名内的升序元素
实战 排行榜(音乐,书籍,赞数最多的文章 等等)