基础概念
大数据的本质
一、数据的存储:分布式文件系统(分布式存储)
二、数据的计算:分部署计算
基础知识
学习大数据需要具备Java知识基础及Linux知识基础
学习路线
大数据学习群142973723
(1)Java基础和Linux基础
(2)Hadoop的学习:体系结构、原理、编程
第一阶段:HDFS、MapReduce、HBase(NoSQL数据库)
第二阶段:数据分析引擎 -> Hive、Pig
数据采集引擎 -> Sqoop、Flume
第三阶段:HUE:Web管理工具
ZooKeeper:实现Hadoop的HA
Oozie:工作流引擎
(3)Spark的学习
第一阶段:Scala编程语言
第二阶段:Spark Core -> 基于内存、数据的计算
第三阶段:Spark SQL -> 类似于mysql 的sql语句
第四阶段:Spark Streaming ->进行流式计算:比如:自来水厂
(4)Apache Storm 类似:Spark Streaming ->进行流式计算
NoSQL:Redis基于内存的数据库
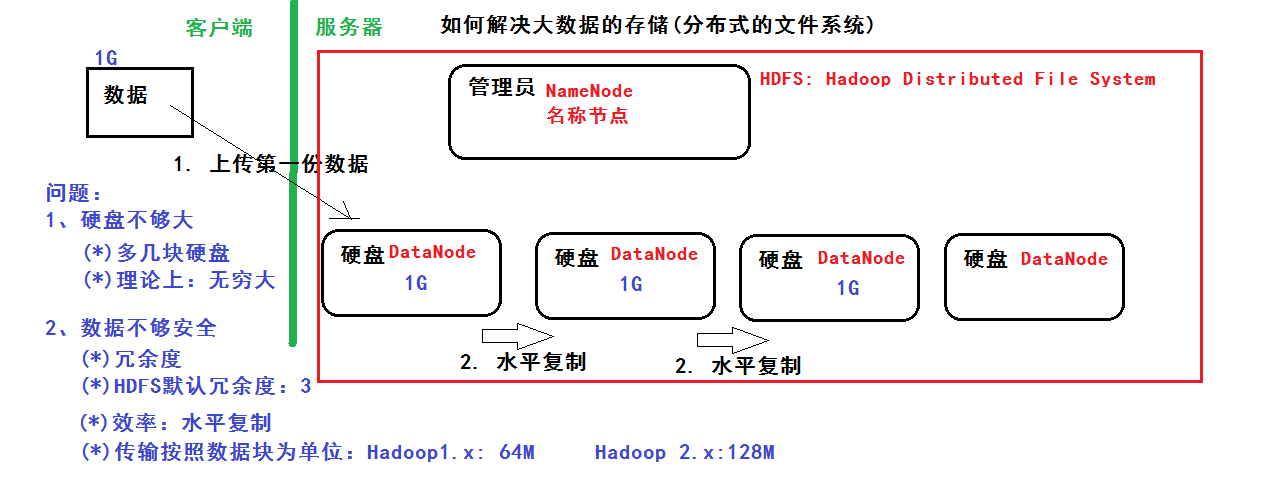
HDFS
分布式文件系统 解决以下问题:
• 硬盘不够大:多几块硬盘,理论上可以无限大
• 数据不够安全:冗余度,hdfs默认冗余为3 ,用水平复制提高效率,传输按照数据库为单位:Hadoop1.x 64M,Hadoop2.x 128M
• 管理员:NameNode 硬盘:DataNode
MapReduce
基础编程模型:把一个大任务拆分成小任务,再进行汇总
• MR任务:Job = Map + Reduce
Map的输出是Reduce的输入、MR的输入和输出都是在HDFS
MapReduce数据流程分析:
• Map的输出是Reduce的输入,Reduce的输入是Map的集合
HBase


什么是BigTable?: 把所有的数据保存到一张表中,采用冗余 —> 好处:提高效率
• 因为有了bigtable的思想:NoSQL:HBase数据库
• HBase基于Hadoop的HDFS的
• 描述HBase的表结构
核心思想是:利用空间换效率.大数据学习群142973723
