什么是系统调用
- Linux内核中设置了很多可以实现各种系统功能的子程序,这些子程序就叫系统调用。而系统调用和普通函数调用的区别主要是在系统调用是系统提供的,函数一般是函数库或者自己提供的。
为什么要用系统调用
- 其实很多我们平时用的C语言标准函数,在Linux上都是通过系统调用完成的。随着深入学习,有时候发现系统调用是完成某些功能最简单最有效的途径。在很多情况下对编程有意想不到的帮助。
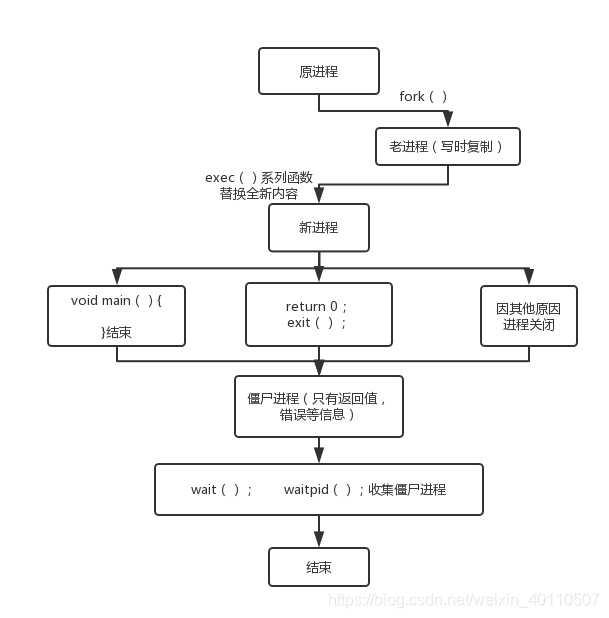
进程的一生
1. 进程通过fork()复制产生新进程
一个进程调用fork()之后,系统会给新进程分配资源。并且把原来进程的所有内容复制(应用到了写时复制技术,在下面会讲到)到新进程当中,相当于复制了一个一模一样的自己。
ptd_t fork(void) //pid_t是fork返回值类型 可用int替换
fork()函数将会有两次返回;其中父进程将会返回子进程的PID(进程ID),而子进程返回值为0。发生错误时将会返回一个负值。
2. 子进程调用exec()以注入灵魂
通过fork()产生的子进程和父进程几乎完全一样,但产生新进程一般就是为了让ta执行新的程序啦,所以要调用exec来为新进程注入灵魂。
exec其实指的是一组函数,一共六个。
#include <unistd.h>
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);
exec函数族的作用是根据指定的路径或者文件名找到可执行文件,并用它来取代原本进程的内容。换句话说,就是把调用进程内部替换为另一个可执行文件。
这些里面只有execve是真正的系统调用,其他的都是基于他包装的库函数。exec函数族的函数执行成功后不会返回,因为调用进程的实体,包括代码段,数据段和堆栈等都已经被新的内容取代,只留下进程ID等一些表面上的信息。只有调用失败了,才会返回一个-1。
Linux当要执行新程序的时候,如果有进程认为自己不能为系统和用户做出任何贡献了,他就可以发挥最后一点余热,调用任何一个exec,让自己以金蝉脱壳;或者,更普遍的情况其实是,如果一个进程想执行另一个程序,它就可以fork()出一个新进程,然后调用任何一个exec,这样看起来就好像通过执行应用程序而产生了一个新进程一样。
3.进程的结束
之后进程就要执行ta的任务啦。而进程结束有三种可能性,一个是主函数结束,或者主函数返回值,再或者是因为其他原因最终进程关闭。
在进程结束后,并不是直接消失,而是会产生一个僵尸进程。
$ ps -ax
1511 pts/0 Z 0:00 [zombie <defunct>]
其中中间的"Z"标识就是僵尸进程的标志了。僵尸进程虽然对其他进程几乎没有什么影响,不占CPU资源,消耗的内存也几乎可以忽略不计,但就这样一个僵尸住在系统里,还是让人觉得不爽。而且Linux系统中进程数目是有限制的,在一些特殊的情况下,如果存在太多的僵尸进程,也会影响产生新进程。
而为什么要有一个僵尸进程呐?僵尸进程中保存着很多非常重要的信息,首先,这个进程是怎么死的?是正常退出呢,还是出现了错误,还是被其它进程强迫退出的?其次,这个进程占用的总系统CPU时间和总用户CPU时间分别是多少?发生页错误的数目和收到信号的数目。这些信息都被存储在僵尸进程中,如果没有僵尸进程,进程一退出,所有这个进程存在过的痕迹都灰飞烟灭,而此如果还要用到进程信息,那就没辙了。
那么,何收集这些信息,并干掉这些僵尸进程呢?就要靠下面要说的waitpid()和wait()了。这两个都是收集僵尸进程留下的信息,同时彻底杀掉这个进程的。下面就对这两个调用分别作详细介绍。
4.wait()与waitpid()
wait():
#include <sys/types.h> /* 提供类型pid_t的定义 */
#include <sys/wait.h>
pid_t wait(int *status)/* pid_t同int*/
某个进程一旦调用了wait(),就立即阻塞自己,由wait()自动分析是否当前进程的某个子进程已经退出,如果让它找到了这样一个已经变成僵尸的子进程,wait就会收集这个子进程的信息,并把它彻底销毁后返回。如果没有找到这样一个子进程,wait就会一直等待僵尸进程的出现。
pid = wait(NULL);
-如果收集到僵尸进程,wait()会返回被收集的进程的进程ID,如果调用进程没有子进程,调用就会失败,此时wait()返回-1。
waitpid():
#include <sys/types.h> /* 提供类型pid_t的定义 */
#include <sys/wait.h>
pid_t waitpid(pid_t pid,int *status,int options)
从本质上讲,系统调用waitpid()和wait()的作用是完全相同的,但waitpid()多出了两参数pid和options,从而为提供了另一种更灵活的使用方式。
- pid
从参数的名字pid和类型pid_t中就可以看出,这里需要的是一个进程ID。但当pid取不同的值时,在这里有不同的意义。
- pid>0时,只等待进程ID等于pid的子进程,不管其它已经有多少子进程运行结束退出了,只要指定的子进程还没有结束,waitpid就会一直等下去。
- pid=-1时,等待任何一个子进程退出,没有任何限制,此时waitpid和wait的作用一模一样。
- pid=0时,等待同一个进程组中的任何子进程,如果子进程已经加入了别的进程组,waitpid不会对它做任何理睬。
- pid<-1时,等待一个指定进程组中的任何子进程,这个进程组的ID等于pid的绝对值。
options
- options
options提供了一些额外的选项来控制waitpid(),目前在Linux中只支持WNOHANG和WUNTRACED两个选项,这是两个常数,可以用"|"运算符把它们连接起来使用,比如:
ret=waitpid(-1,NULL,WNOHANG | WUNTRACED);
如果我们不想使用它们,也可以把options设为0,如:
ret=waitpid(-1,NULL,0);
如果使用了WNOHANG参数调用waitpid,即使没有子进程退出,它也会立即返回,不会像wait那样永远等下去。
看到这里,相信已经有人发现了,wait()不就是经过包装的waitpi()d吗?没错,在<内核源码目录>/include/unistd.h文件里能发现这些:
static inline pid_t wait(int * wait_stat)
{
return waitpid(-1,wait_stat,0);
}
【完】
- 如果有错误的地方请多指出
相关主题:
系统调用跟我学(3)–进程管理相关的系统调用之二 雷镇,2002
Linux man pages
Advanced Programming in the UNIX Environment by W. Richard Stevens, 1993
Linux核心源代码分析 彭晓明,王强,2000