IntelliJ IDEA 2018.2.3 (Ultimate Edition)+Maven
VMware中CentOS6.5
Hadoop2.7.1
上课的时候老师使用的是Eclipse编译器,使用了 eclipse-hadoop的插件。可以直接在eclipse里运行,省去了先生成jar再发送的虚拟机中执行的过程。
由于编译器IDEA没有这种插件所以自己在网上找了一些帖子,对编译器进行配置,达到的效果是可以直接在IDEA中运行MapperReducer等代码并查看代码报错,但是不可以看到hdfs上的文件夹结构(可以在里浏览器使用虚拟机ip50070端口查看),也不可以查看文件内容,只是免去了一直生成jar包的繁琐过程如果大家有可以在idea中可视化文件结构的方法或者其他补充欢迎在下面留言
下面介绍一下操作流程和我遇到的错误:
操作流程
下载对应的Hadoop包
在win10环境变量中添加hadoop包所在的路径(winutils.exe一定要在,其他不确定必不必要)
环境变量怎么找?打开windows的设置然后搜索环境变量,之后在高级设置中打开就可以看到了。

找到之后,在用户或者系统环境变量中添加HOME_HADOOP(名字可以自己起)
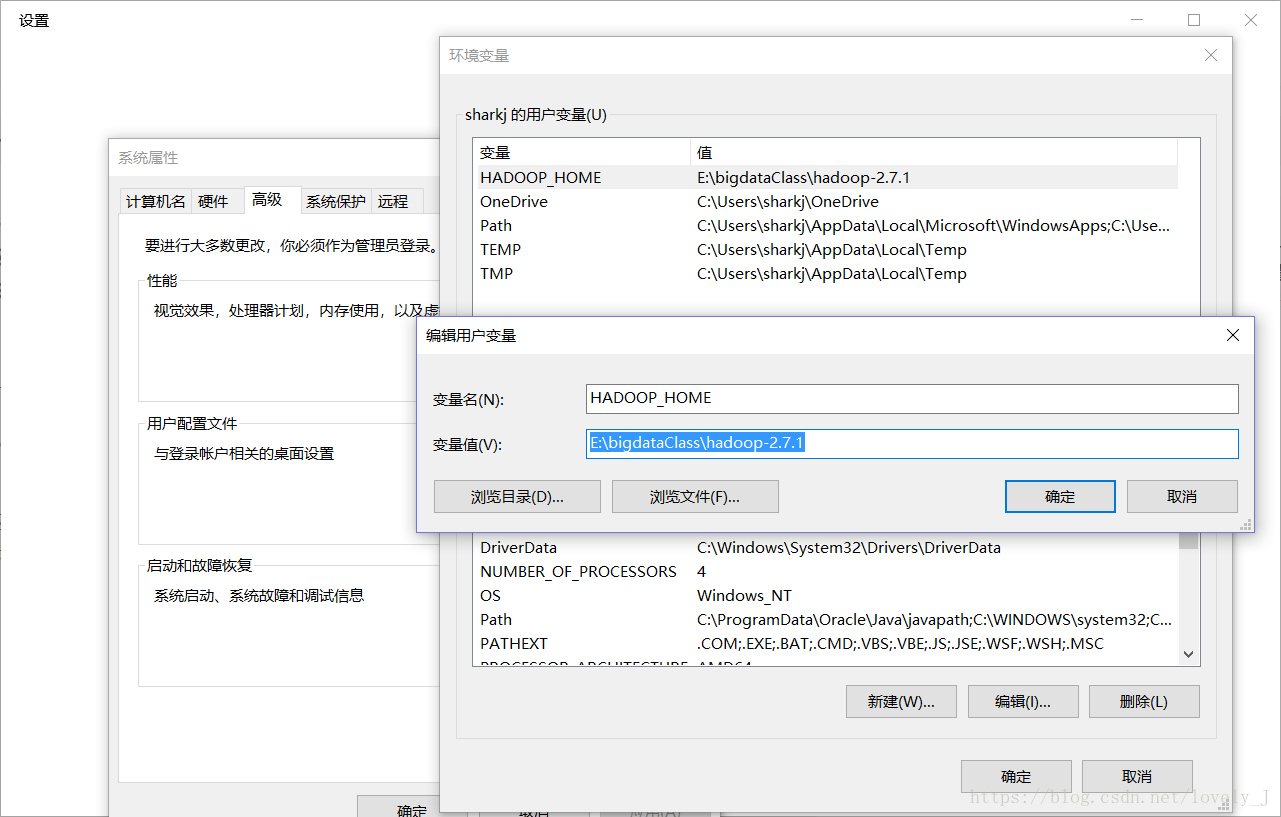
然后在Path中添加%HADOOP_HOME%\bin
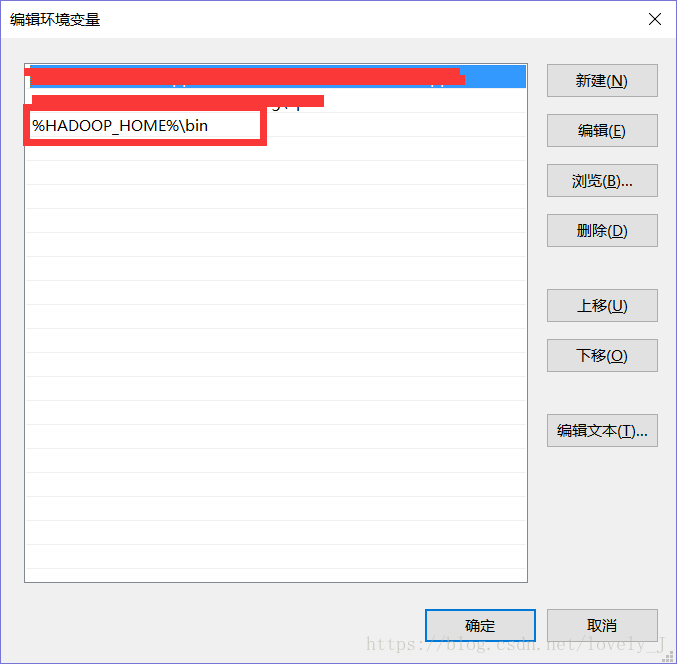
注意这里\bin是因为我的winutils.exe和hadoop.dll文件在hadoop所在路径的\bin目录下。这个路径要能找到winutils.exe和hadoop.dll文件就可以了。
然后把hadoop.dll文件复制到C:\Windows\System32下(需要管理员权限),然后重启电脑,因为修改了环境变量要给系统一个重新认识自己的过程。
在Maven项目的POM文件中添加hadoop和junit的dependencies如下
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.7.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.7.1</version>
</dependency>
</dependencies>之后直接在IDEA运行Driver里的main方法就可以啦。
这是我的一个简单例子。
个人理解是需要为IDEA指明hadoop调用的地方,它只要找得到就可以在win下运行hadoop,再在代码中指明虚拟机中hadoop的ip地址就可以正常操作了。
常见错误
1.没有打印日志文件直接结束运行
方法:在项目properties包下添加log4j.properties
下面是我的log4j.properties里的内容
###\u8BBE\u7F6E ###
log4j.rootLogger = info,stdout
###\u8F93\u51FA\u4FE1\u606F\u5230\u63A7\u5236\u62AC ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
2.空指针异常
估计是环境变量或者系统里的hadoop.dll没有被识别到。确认hadoop.dll在C:\Windows\System32下并且环境变量里的路径可以找到windows本机hadoop的路径之后重启电脑