Linux对线程的亲和性是有支持的,在Linux内核中,所有线程都有一个相关的数据结构,称为task_count,这个结构中和亲和性有关的是cpus_allowed位掩码,这个位掩码由n位组成,n代码逻辑核心的个数。
Linux内核API提供了一些方法,让用户可以修改位掩码或者查看当前的位掩码。
sched_setaffinity(); //修改位掩码,主要事用来绑定进程
sched_getaffinity(); //查看当前的位掩码,查看进程的亲和性
pthread_setaffinity_np();//主要用来绑定线程
pthread_getaffinity_np();//查看线程的亲和性使用亲和性的原因是将线程和CPU绑定可以提高CPU cache的命中率,从而减少内存访问损耗,提高程序的速度。多核体系的CPU,物理核上的线程来回切换,会导致L1/L2 cache命中率的下降,如果将线程和核心绑定的话,线程会一直在指定的核心上跑,不会被操作系统调度到别的核上,线程之间互相不干扰完成工作,节省了操作系统来回调度的时间。同时NUMA架构下,如果操作系统调度线程的时候,跨越了NUMA节点,将会导致大量的L3 cache的丢失。这样NUMA使用CPU绑定的时候,每个核心可以更专注的处理一件事情,资源被充分的利用了。
DPDK通过把线程绑定到逻辑核的方法来避免跨核任务中的切换开销,但是对于绑定运行的当前逻辑核,仍可能发生线程切换,若进一步减少其他任务对于某个特定任务的影响,在亲和性的基础上更进一步,可以采用把逻辑核从内核调度系统剥离的方法。
DPDK的多线程
DPDK的线程基于pthread接口创建(DPDK线程其实就是普通的pthread),属于抢占式线程模型,受内核调度支配,DPDK通过在多核设备上创建多个线程,每个线程绑定到单独的核上,减少线程调度的开销,以提高性能。
DPDK的线程可以属于控制线程,也可以作为数据线程。在DPDK的一些示例中,控制线程一般当顶到MASTER核(一般用来跑主线程)上,接收用户配置,并传递配置参数给数据线程等;数据线程分布在不同的SLAVE核上处理数据包。
EAL中的lcore
DPDK的lcore指的是EAL线程,本质是基于pthread封装实现的,lcore创建函数为:
rte_eal_remote_launch();在每个EAL pthread中,有一个TLS(Thread Local Storage)称为_lcore_id,当使用DPDk的EAL ‘-c’参数指定核心掩码的时候,EAL pehread生成相应个数lcore并默认是1:1亲和到对应的CPU逻辑核,_lcore_id和CPU ID是一致的。
下面简要介绍DPDK中lcore的初始化及执行任务的注册
初始化
所有DPDK程序中,main()函数执行的第一个DPDK API一定是int rte_eal_init(int argc, char **argv);,这个函数是整个DPDK的初始化函数,在这个函数中会执行lcore的初始化。
初始化的接口为rte_eal_cpu_init(),这个函数读取/sys/devices/system/cpu/cpuX下的相关信息,确定当前系统有哪些CPU核,以及每个核心属于哪个CPU Socket。
接下来是eal_parse_args()函数,解析-c参数,确认可用的CPU核心,并设置第一个核心为MASTER核。
然后主核为每一个SLAVE核创建线程,并调用eal_thread_set_affinity()绑定CPU。线程的执行体是eal_thread_loop()。eal_thread_loop()主体是一个while死循环,调用不同模块注册的回调函数。
注册
不同的注册模块调用rte_eal_mp_remote_launch(),将自己的回调函数注册到lcore_config[].f中,例子(来源于example/distributor)
rte_eal_remote_launch((lcore_function_t *)lcore_distributor, p, lcore_id);lcore的亲和性
DPDK除了-c参数,还有一个–lcore(-l)参数是指定CPU核的亲和性的,这个参数讲一个lcore ID组绑定到一个CPU ID组,这样逻辑核和线程其实不是完全1:1对应的,这是为了满足网络流量潮汐现象时刻,可以更加灵活的处理数据包。
lcore可以亲和到一个CPU或一组CPU集合,使得在运行时调整具体某个CPU承载lcore成为可能。
多个lcore也可以亲和到同个核,这里要注意的是,同一个核上多个可抢占式的任务调度涉及非抢占式的库时,会有一定的限制,例如非抢占式无锁rte_ring:
- 单生产者/单消费者:不受影响,正常使用
- 多生产者/多消费者,且调度策略都是SCHED_OTHER(分时调度策略),可以使用,但是性能稍有影响
- 多生产者/多消费者,且调度策略都是SCHED_FIFO (实时调度策略,先到先服务)或者SCHED_RR(实时调度策略,时间片轮转 ),会死锁。
一个lcore初始化和执行任务分发的流程如下:
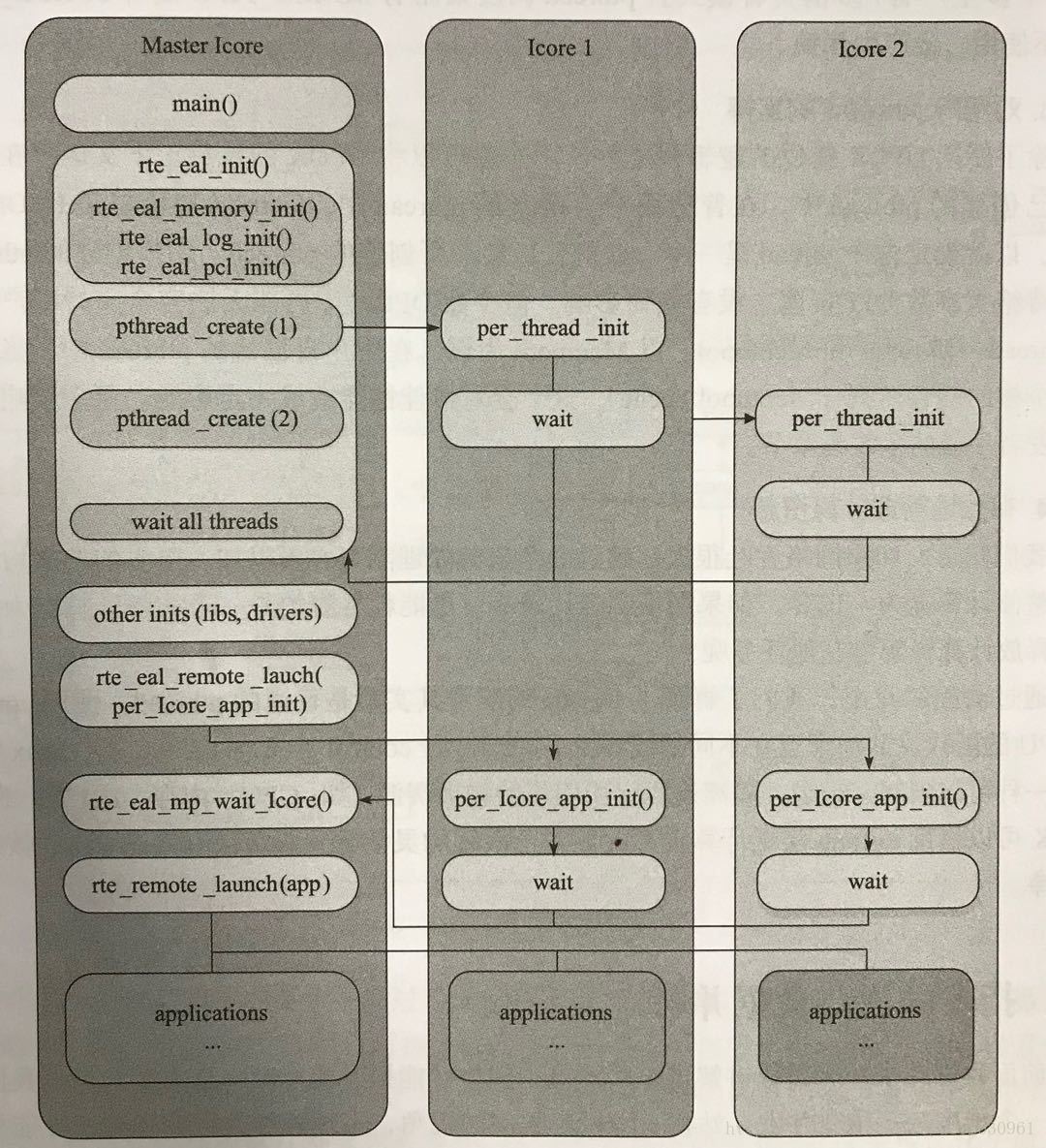
用户态初始化具体的流程如下:
- 主核启动main()
- rte_eal_init()进行初始化,主要包括内存、日志、PCI等方面的初始化工作,同时启动逻辑核线程
- pthread()在逻辑核上进行初始化,并处于等待状态
- 所有逻辑核都完成初始化后,主核进行后续初始化步骤,如初始化lib库和驱动
- 主核远程启动各个逻辑核上的应用实例初始化操作
- 主核启动各个核(主核和逻辑核)上的应用
CPU的绑定
先将主线程绑定在master核上,然后通过主线程创建线程池,通过线程池进行分配副线程到slave核上。在这之前首先要获取CPU的核数量等信息,将这些信息存放到全局的结构体中。
int
rte_eal_init(int argc, char **argv)
{
。。。。。。
thread_id = pthread_self();
if (rte_eal_log_early_init() < 0)
rte_panic("Cannot init early logs\n");
if (rte_eal_cpu_init() < 0)//赋值全局结构struct lcore_config,获取全局配置结构struct rte_config,初始指向全局变量early_mem_config,探索CPU并读取其CPU ID
rte_panic("Cannot detect lcores\n");
。。。。。。。。
eal_thread_init_master(rte_config.master_lcore);//绑定CPU,绑定到master核上
ret = eal_thread_dump_affinity(cpuset, RTE_CPU_AFFINITY_STR_LEN);//查看CPU绑定情况
。。。。。。。。。。
ret = pthread_create(&lcore_config[i].thread_id, NULL,
eal_thread_loop, NULL);//启动线程池中的副线程,为每个lcore创建一个线程,绑定到slave核上
if (ret != 0)
rte_panic("Cannot create thread\n");
}以上可以清楚的看见dpdk在初始化的时候绑定cpu的大致过程。
首先看一下 rte_eal_cpu_init()函数:
/*解析/sys/device /system/cpu以获得机器上的物理和逻辑处理器的数量。该函数将填充cpu_info结构。*/
int
rte_eal_cpu_init(void)
{
/* pointer to global configuration */
struct rte_config *config = rte_eal_get_configuration();//获取全局结构体指针
unsigned lcore_id;
unsigned count = 0;
/*
* 设置逻辑核心的最大集合,检测正在运行的逻辑核心的子集并默认启用它们
*/
for (lcore_id = 0; lcore_id < RTE_MAX_LCORE; lcore_id++) {
/* init cpuset for per lcore config */
CPU_ZERO(&lcore_config[lcore_id].cpuset);
/* 在1:1映射中,记录相关的cpu检测状态 */
lcore_config[lcore_id].detected = cpu_detected(lcore_id);//检测CPU状态
if (lcore_config[lcore_id].detected == 0) {
config->lcore_role[lcore_id] = ROLE_OFF;
continue;
}
//映射到cpu id
CPU_SET(lcore_id, &lcore_config[lcore_id].cpuset);
/* 检测cpu核启动 */
config->lcore_role[lcore_id] = ROLE_RTE;
lcore_config[lcore_id].core_id = cpu_core_id(lcore_id);
lcore_config[lcore_id].socket_id = eal_cpu_socket_id(lcore_id);
if (lcore_config[lcore_id].socket_id >= RTE_MAX_NUMA_NODES)
#ifdef RTE_EAL_ALLOW_INV_SOCKET_ID
lcore_config[lcore_id].socket_id = 0;
#else
rte_panic("Socket ID (%u) is greater than "
"RTE_MAX_NUMA_NODES (%d)\n",
lcore_config[lcore_id].socket_id, RTE_MAX_NUMA_NODES);
#endif
RTE_LOG(DEBUG, EAL, "Detected lcore %u as core %u on socket %u\n",
lcore_id,
lcore_config[lcore_id].core_id,
lcore_config[lcore_id].socket_id);
count ++;
}
/* 设置EAL配置的启用逻辑核心的计数 */
config->lcore_count = count;
RTE_LOG(DEBUG, EAL, "Support maximum %u logical core(s) by configuration.\n",
RTE_MAX_LCORE);
RTE_LOG(DEBUG, EAL, "Detected %u lcore(s)\n", config->lcore_count);
return 0;
}
在这个函数中,并没有绑定具体线程,只是将cpu中的核给默认启动起来,并且放入到全局结构体中,我们后面会用到这个结构体来进行绑定线程。
eal_thread_init_master()函数:
void eal_thread_init_master(unsigned lcore_id)
{
/* set the lcore ID in per-lcore memory area */
RTE_PER_LCORE(_lcore_id) = lcore_id;
/* set CPU affinity */
if (eal_thread_set_affinity() < 0)
rte_panic("cannot set affinity\n");
}
。。。
int
rte_thread_set_affinity(rte_cpuset_t *cpusetp)
{
int s;
unsigned lcore_id;
pthread_t tid;
tid = pthread_self();
s = pthread_setaffinity_np(tid, sizeof(rte_cpuset_t), cpusetp);
if (s != 0) {
RTE_LOG(ERR, EAL, "pthread_setaffinity_np failed\n");
return -1;
}
/* store socket_id in TLS for quick access */
RTE_PER_LCORE(_socket_id) =
eal_cpuset_socket_id(cpusetp);
/* store cpuset in TLS for quick access */
memmove(&RTE_PER_LCORE(_cpuset), cpusetp,
sizeof(rte_cpuset_t));
lcore_id = rte_lcore_id();
if (lcore_id != (unsigned)LCORE_ID_ANY) {
/* EAL thread will update lcore_config
线程更新,这块代码为何自己覆盖自己,不应该啊*/
lcore_config[lcore_id].socket_id = RTE_PER_LCORE(_socket_id);
memmove(&lcore_config[lcore_id].cpuset, cpusetp,
sizeof(rte_cpuset_t));
}
return 0;
}这个地方我们就清楚的看见将主线程绑定到master核上了,可以看见传的参数就是master核的id,然后绑定master核更新cpu核结构体 信息。
eal_thread_loop()函数:
从上面代码中可以看见是主线程创建了一个副线程来进行的。接下来我们就看看这个线程中eal_thread_loop到底干了些什么。
__attribute__((noreturn)) void *
eal_thread_loop(__attribute__((unused)) void *arg)
{
char c;
int n, ret;
unsigned lcore_id;
pthread_t thread_id;
int m2s, s2m;
char cpuset[RTE_CPU_AFFINITY_STR_LEN];
thread_id = pthread_self();
/* retrieve our lcore_id from the configuration structure */
//循环查找当前线程的id所在的核
RTE_LCORE_FOREACH_SLAVE(lcore_id) {
if (thread_id == lcore_config[lcore_id].thread_id)
break;
}
if (lcore_id == RTE_MAX_LCORE)
rte_panic("cannot retrieve lcore id\n");
m2s = lcore_config[lcore_id].pipe_master2slave[0];
s2m = lcore_config[lcore_id].pipe_slave2master[1];
/* set the lcore ID in per-lcore memory area */
RTE_PER_LCORE(_lcore_id) = lcore_id;
/* set CPU affinity */
//设置当前线程CPU的亲和性
if (eal_thread_set_affinity() < 0)
rte_panic("cannot set affinity\n");
ret = eal_thread_dump_affinity(cpuset, RTE_CPU_AFFINITY_STR_LEN);
RTE_LOG(DEBUG, EAL, "lcore %u is ready (tid=%x;cpuset=[%s%s])\n",
lcore_id, (int)thread_id, cpuset, ret == 0 ? "" : "...");
/* read on our pipe to get commands */
//下面说是等待读取管道上的命令,这个地方其实在等待一个有趣的东西(执行函数)
while (1) {
void *fct_arg;
/* wait command */
do {
n = read(m2s, &c, 1);
} while (n < 0 && errno == EINTR);
if (n <= 0)
rte_panic("cannot read on configuration pipe\n");
lcore_config[lcore_id].state = RUNNING;
/* send ack */
n = 0;
while (n == 0 || (n < 0 && errno == EINTR))
n = write(s2m, &c, 1);
if (n < 0)
rte_panic("cannot write on configuration pipe\n");
if (lcore_config[lcore_id].f == NULL)
rte_panic("NULL function pointer\n");
/* call the function and store the return value */
fct_arg = lcore_config[lcore_id].arg;
ret = lcore_config[lcore_id].f(fct_arg);
lcore_config[lcore_id].ret = ret;
rte_wmb();
lcore_config[lcore_id].state = FINISHED;
}
/* never reached */
/* pthread_exit(NULL); */
/* return NULL; */
}这个函数非常的有趣,再绑定的时候还是调用的上面绑定函数,绑定好了之后,让这个线程处于等待状态,等待什么呢?其实这个地方再等待分配执行函数过来,也就是说,这个核需要给他分配一个任务他才去执行。
总结
dapk设置cpu亲和性大大的提高了效率,减少了线程之间的切换。这是一个值得学习的地方。下面就说一下线程迁移问题。
迁移线程
在普通进程的load_balance过程中,如果负载不均衡,当前CPU会试图从最繁忙的run_queue中pull几个进程到自己的run_queue来。
但是如果进程迁移失败呢?当失败达到一定次数的时候,内核会试图让目标CPU主动push几个进程过来,这个过程叫做active_load_balance。这里的“一定次数”也是跟调度域的层次有关的,越低层次,则“一定次数”的值越小,越容易触发active_load_balance。
这里需要先解释一下,为什么load_balance的过程中迁移进程会失败呢?最繁忙run_queue中的进程,如果符合以下限制,则不能迁移:
1、进程的CPU亲和力限制了它不能在当前CPU上运行;
2、进程正在目标CPU上运行(正在运行的进程显然是不能直接迁移的);
(此外,如果进程在目标CPU上前一次运行的时间距离当前时间很小,那么该进程被cache的数据可能还有很多未被淘汰,则称该进程的cache还是热的。对于cache热的进程,也尽量不要迁移它们。但是在满足触发active_load_balance的条件之前,还是会先试图迁移它们。)
对于CPU亲和力有限制的进程(限制1),即使active_load_balance被触发,目标CPU也不能把它push过来。所以,实际上,触发active_load_balance的目的是要尝试把当时正在目标CPU上运行的那个进程弄过来(针对限制2)。
在每个CPU上都会运行一个迁移线程,active_load_balance要做的事情就是唤醒目标CPU上的迁移线程,让它执行active_load_balance的回调函数。在这个回调函数中尝试把原先因为正在运行而未能迁移的那个进程push过来。为什么load_balance的时候不能迁移,active_load_balance的回调函数中就可以了呢?因为这个回调函数是运行在目标CPU的迁移线程上的。一个CPU在同一时刻只能运行一个进程,既然这个迁移线程正在运行,那么期望被迁移的那个进程肯定不是正在被执行的,限制2被打破。
当然,在active_load_balance被触发,到回调函数在目标CPU上被执行之间,目标CPU上的TASK_RUNNING状态的进程可能发生一些变化,所以回调函数发起迁移的进程未必就只有之前因为限制2而未能被迁移的那一个,可能更多,也可能一个没有。
部分参考:https://blog.csdn.net/u012630961/article/details/80918682