目录
前文列表
OpenStack Nova 高性能虚拟机之 NUMA 架构亲和
进程与线程
进程:是操作系统进行资源分配与资源调度的基本单位,在古早时期面向进程设计的计算机结构中,进程是程序的基本执行实体。但在当代面向线程设计的计算机结构中,进程作为了系统资源和线程的容器,而基本执行单元也由线程代替。程序是指令、数据及其组织形式的描述,而进程则是程序的实体。
线程:是操作系统进行处理器调度和分派的基本单位,是进程中能够并发执行的实体。一个进程至少拥有一个主线程和可以拥有多个子线程,线程间共享进程拥有的所有系统资源,而线程自身却只会拥有一点在执行过程中必不可少的资源(e.g. 程序计数器、寄存器和栈)。因此,创建/撤销线程以及线程间通信的开销都远低于进程,线程带来了更高的并发性能。
进程与线程的比较:

Linux 的进程
Linux 是一种抢占式多任务操作系统,能够同时并发的执行多个进程并由进程调度器来决定什么时候停止一个进程的运行,以便其他进程也能够得到执行的机会。这种强制挂起的动作叫做「抢占」。进程被抢占之前能够运行的时间长度是预先设置好的,称为进程时间片,简单来说,进程时间片就是分配给每个可运行进程的处理器占用时长。
Linux 进程类型
进程可以分为:
I/O 消耗型(I/O 密集型):进程的大部分时间都在提交 I/O 请求或者等待 I/O 请求,会经常处于可运行状态且相比于 I/O 等待时长其运行时长很短。
处理器消耗型(CPU 密集型):进程的时间大多用在执行代码上,没有太多的 I/O 需求,除非被抢占,否则通常都会不停地运行。
Linux 进程调度策略根据「降低进程调度频率,延长进程运行时间」的原则,在进程响应快(CPU 占用时间长进程任务做得快)和最大化系统吞吐量(CPU 占用时间短进程数量做得多)这两个矛盾点间寻找平衡。Linux 会更倾向于优先调度 I/O 密集型进程。
对于线程而言,大同小异。如果想要高吞吐量,那必然想办法让 Processor 的数量更多,让线程的切换更频繁,达到线程装载量的最大化;如果想要提高某些线程运行的效率,那么必然要想办法让特定的线程占用 Processor 的时间片越长,减少线程切换的损耗,尽量让这些线程先处理完。假设拥有 N 个 Processor,可以按照下列常规原则来设置线程池:
- CPU 密集型场景,线程池大小设置为 N+1
- I/O 密集型场景,线程池大小设置为 2N+1
这里还可以将超线程的性能问题串联起来:
在超线程的帮助下,两个被调度到同一个 Core 下不同 Thread 的 Worker,由于 Threads 共享 Cache 和 TLB(Translation Lookaside Buffer,转换检测缓冲区),所以能够大幅降低 Workers 线程切换的开销。另外,在某个 Worker 不忙的时候,超线程允许其它的 Worker 先使用物理计算资源,以此来提升 Core 的整体吞吐量,适合应用到 I/O 密集型场景。
但由于 Threads 之间会争抢 Core 的物理执行资源,导致单个 Thread 的执行时延也会相应增加,响应速度不如当初。对于 CPU 密集型任务而言,当存在超线程竞争时,超线程计算能力大概是物理核的 60% 左右。
Linux 进程的优先级调度策略
Linux 的进程优先级调度策略是一种根据进程价值和进程对处理器时间需求来对进程分级的思想。进程调度器总是优先调度时间片未用尽且优先级高的进程。
在多任务环境中,优先级调度策略自不可少,Linux 的进程分为实时进程和非实时的普通进程。「实时进程」的实现,使得 Linux 正式加入到实时操作系统的队列,从此 Linux 才得到了工业领域应用场景的认可。简单来说,实时操作系统需要保证实时进程能够在较短的时间内得到响应,不具有长时延性,并且要求最小的中断延时和进程切换延时。
对于这样的需求,一般的进程调度算法,无论是 O1 还是 CFS 都无法满足。所以在设计 Linux 内核的时候,就将进程优先级划分为了普通进程优先级和实时进程优先级,并以 MAX_PRIO 宏来进行划分。
- 实时优先级具有 100 个级别对应 MAX_PRIO 的范围 [0, 99]
- 普通优先级具有 40 个级别对应 MAX_PRIO 的范围 [100, 139]
所以实时优先级和普通优先级从逻辑上被分为了两个层面,它们之间并无交叉。实时进程永远优先于普通进程被调度进 CPU 执行,而且实时进程的调度算法采用了更为简单的实现来减少调度开销。
- 如果存在需要执行的实时进程,则优先执行实时进程
- 直到实时进程退出或者主动让出 CPU 后,才会调度执行普通进程
PS:O1 和 CFS 都是 Linux Kernal 实现的进程调度算法,这里不展开,可参考 https://blog.csdn.net/gatieme/article/details/51701149。
手动设定 Linux 进程优先级
配置进程优先级权重对改善 Linux 多任务环境的系统性能非常受用,除此之外,还可以通过把进程绑定到指定的 CPU 上允许来改善系统的整体性能。例如:将优先级低的进程(s)安排到某个 CPU,让优先级高的进程能享有更充分的资源。
查看 Linux 所有进程及优先级:
root@devstack-all-in:~# ps -le
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 1 0 0 80 0 - 19522 ep_pol ? 00:00:03 systemd
1 S 0 2 0 0 80 0 - 0 kthrea ? 00:00:00 kthreadd
1 I 0 4 2 0 60 -20 - 0 worker ? 00:00:00 kworker/0:0H
1 I 0 6 2 0 60 -20 - 0 rescue ? 00:00:00 mm_percpu_wq
...- UID:进程执行者
- PID:进程代号
- PPID:父进程代号
- PRI:进程优先级,值越小优先级越高
- NI:进程的 nice 值
Linux 引入来 nice 值来作为普通进行优先级调整入口,nice 值的范围为 [-20, 19],对应 MAX_PRIO 的 [100, 139]。nice 值默认为 0,值越小,优先级越高。
查看更多进程信息:
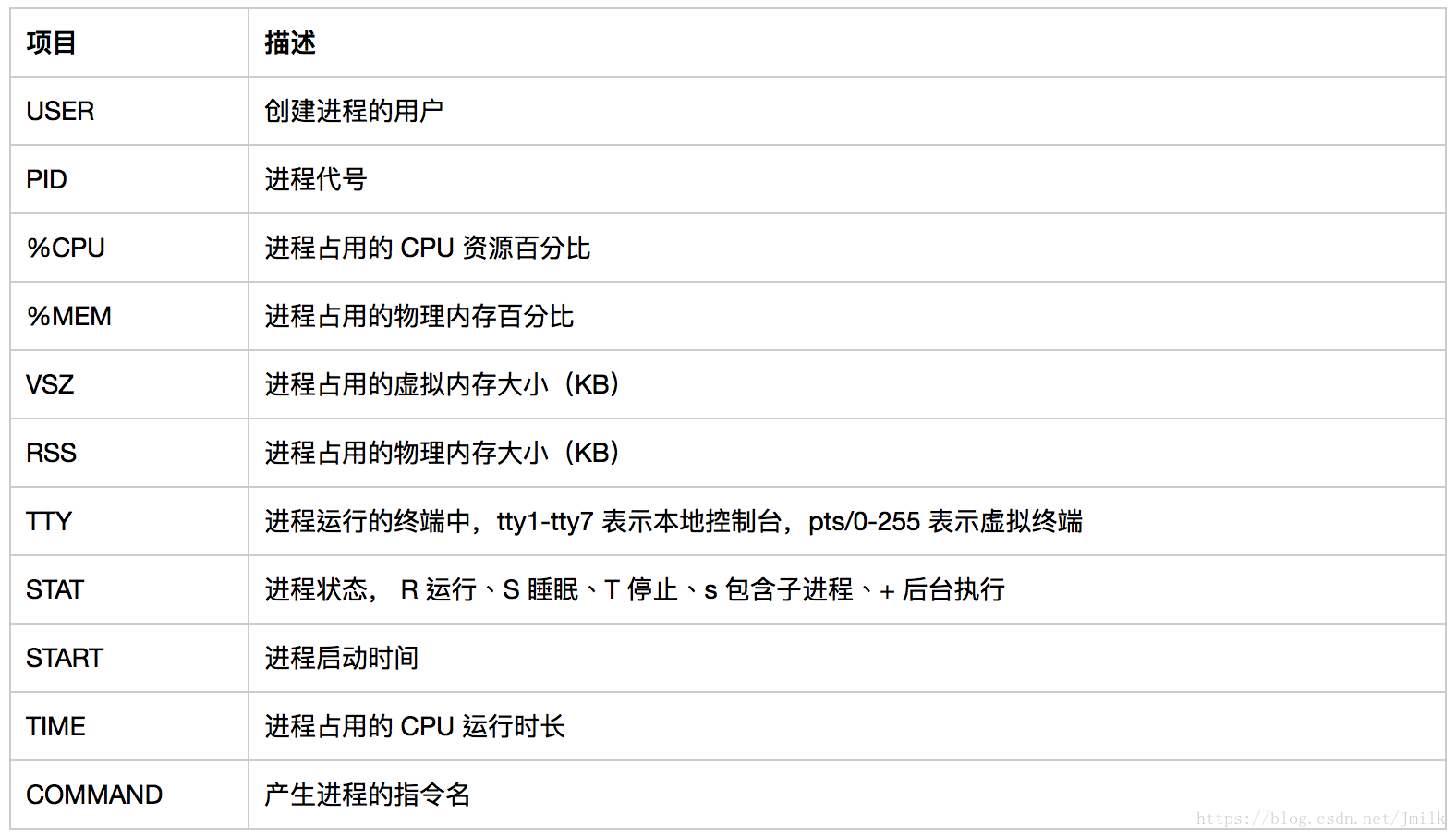
root@devstack-all-in:~# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.1 0.0 78088 9188 ? Ss 04:26 0:03 /sbin/init maybe-ubiquity
...
stack 2152 0.1 0.8 304004 138160 ? S 04:27 0:04 nova-apiuWSGI worker 1
stack 2153 0.1 0.8 304004 138212 ? S 04:27 0:04 nova-apiuWSGI worker 2
...
修改普通进程优先级
需要注意的是,nice 值作为调整普通进程优先级的入口,实际上是通过公式 PRI(最终) = PRI(原始) + nice 来决定进程优先级的。用户只能修改 NI 值,不能直接修改 PRI 值,但却可以通过 NI 值来影响 PRI 值。这样,当 nice 值为负值时,那么该进程的 PRI 值会变小,优先级会变高,越快会被执行。
nice 指令:为新执行的命令赋予 NI 值,但是不能修改已存在进程的 NI 值。e.g.
$ nice -n -5 service httpd startrenice 指令:修改已经存进程的 NI 值。e.g.
$ renice -10 <PID>
修改实时进程优先级
- chrt 指令:查看、设置进程(包含实时与普通)的优先级状态。e.g.
root@devstack-all-in:~# chrt 10 bash
root@devstack-all-in:~# chrt -p $$
pid 6271's current scheduling policy: SCHED_RR # RR 时间片轮转调度算法,时间片长为 100ms
pid 6271's current scheduling priority: 10由于公式 PRI(最终) = PRI(原始) - priority,所以 priority 值越大,则 PRI 的值越小,优先级越高。
chrt 指令支持操作 6 种调度策略:
root@devstack-all-in:~# chrt --help
Show or change the real-time scheduling attributes of a process.
Set policy:
chrt [options] <priority> <command> [<arg>...]
chrt [options] --pid <priority> <pid>
Get policy:
chrt [options] -p <pid>
Policy options:
-b, --batch set policy to SCHED_BATCH
-d, --deadline set policy to SCHED_DEADLINE
-f, --fifo set policy to SCHED_FIFO
-i, --idle set policy to SCHED_IDLE
-o, --other set policy to SCHED_OTHER
-r, --rr set policy to SCHED_RR (default)其中 SCHED_FIFO、SCHED_RR、SCHED_DEADLINE 是实时进程可以使用的调度策略,其余为普通进程可用。如果要修改实时进程的调度策略,则要使用 Policy options。e.g.
root@devstack-all-in:~# chrt -f 10 bash
root@devstack-all-in:~# chrt -p $$
pid 6344's current scheduling policy: SCHED_FIFO # 先到先服务调度算法
pid 6344's current scheduling priority: 10vCPU 与 pCPU
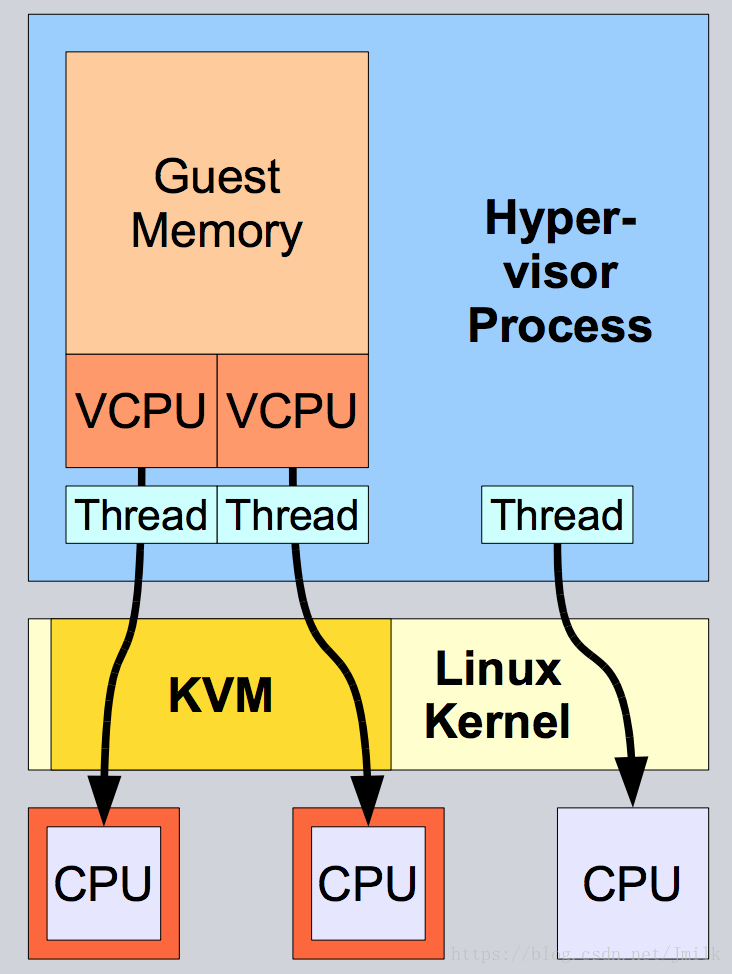
可见,虚拟机的 vCPU 实际上被作为一个 Thread 在 pCPU 上运行。
计算 vCPU 的总数
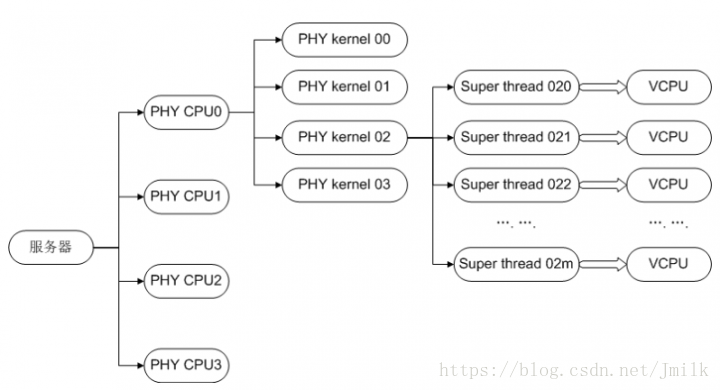
通常的,系统可用的 vCPU 总数 = Sockets * Cores * Threads。简单来说就是:vCPU 的数量等于宿主机的 Processor 数量。例如:一台具有 2 颗 16 物理核心 2 超线程 CPU 的宿主机,可用的 vCPU 数量就是 64 个。如果启动了 CPU 超配比的话,那么 vCPU 的数量还需要在原始数量基础上再乘以超配比的比率得到。例如:设置了 CPU 超配比为 4:0,那么 vCPU 的数量就等于 64*4 = 256 颗。
VMM 对 vCPU 的分配与调度
由 GuestOS 和 VMM 共同构成了虚拟机系统的两级调度架构:
- 1 级调度:由 VMM 完成,即 vCPU 在物理处理单元(Socket、Core、Thread)上的调度
- 2 级调度:由 GuestOS 完成,即虚拟机内部进程或线程在 vCPU 上的调度(将核心线程映射到相应的 vCPU 上)
两级调度的调度策略与机制不存在依赖关系。vCPU 调度器负责物理处理单元资源在各个虚拟机之间的分配和调度,本质上是把各个虚拟机中的 vCPU 按照一定的策略和机制调度在物理处理单元上,可以采用任意的策略来分配物理资源,满足虚拟机的不同需求。
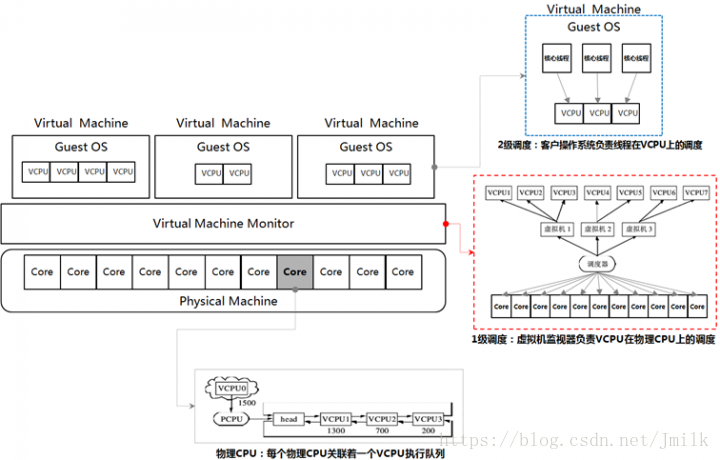
vCPU 可以调度在一个或多个物理处理单元上执行(分时复用或空间复用物理处理单元),也可以与物理处理单元建立一对一固定的映射关系(限制 vCPU 访问的物理处理单元)。
VMware vSphere vCPU 的状态机
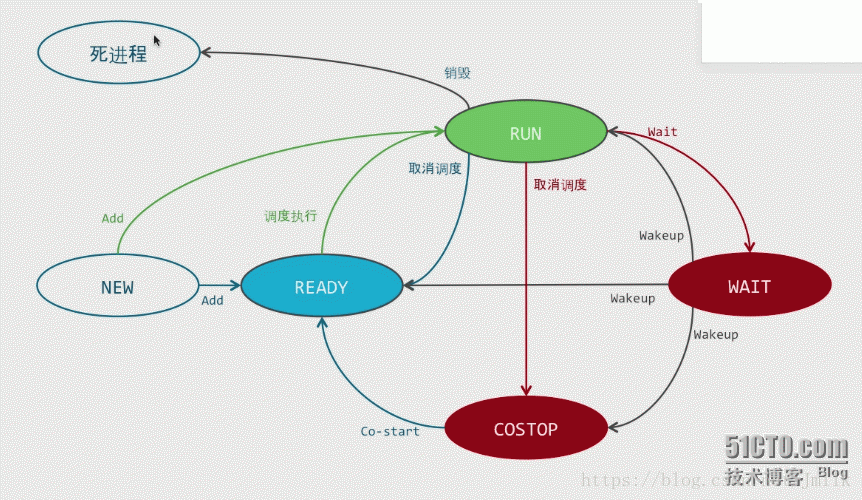
vSphere 中的 vCPU 存在 4 种状态:
- Ready:vCPU 等待 pCPU 的调度,在 esxtop 下表示为 %RDY
- Run:vCPU 正常运行,在 esxtop 下表示为 %RUN
- Wait:当虚拟机不需要进行 vCPU 调度的状态,典型表现为虚拟机挂起,在 esxtop 下表示为 %WAIT
- CoStop:虚拟机的 vCPU 彼此等待,在 esxtop 下表示为 %CSTP
当启动新的虚拟机时,如果虚拟机的 vCPU 能够加载到空闲的宿主机 Processor,那么 vCPU 就会直接进入 Run 状态,否则进入 Ready 状态,直至 vCPU 找到空闲的 Processor。
vcpu_pin_set 配置项
vcpu_pin_set 是计算节点上 nova.conf 的一个配置项,是 OpenStack 最早设计用于限定虚拟机可以使用计算节点上的 pCPUs 范围的配置方式,解决了下述问题:
currently the instances can use all of the pcpu of compute node, the host may become slowly when vcpus of instances are busy, so we need to pin vcpus to the specific pcpus of host instead of all pcpus. the vcpu xml conf of libvirt will change to like this:
<vcpu cpuset="4-12,^8,15">1</vcpu>
简单来说,就是为了防止虚拟机争抢宿主机进程的 CPU 资源,给宿主机适当的留下若干 CPU 以保证性能。e.g.
vcpu_pin_set = 4-$NOTE:如果指定的 CPU 范围超出了宿主机原有的 CPU 范围则会触发异常。
Nova 的 CPU 绑定
vCPU 的指令集与性能
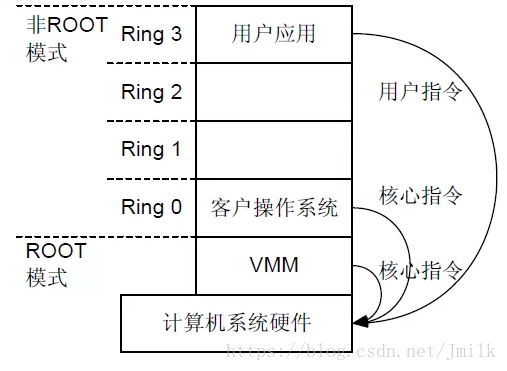
对于虚拟机而言,它是不会直接感知 pCPU 的,虚拟机能感知到 VMM(Virtual Machine Monitor)为其分配的 vCPU。在 VMM 中,每一个 vCPU 都对应着一个 VMCS(Virtual Machine Control Structure,虚拟机控制结构),用于保存 vCPU 运行切换时的上下文数据。当 vCPU 从 pCPU 上切换下来时,vCPU 运行的上下文数据会被保存到对应的 VMCS 中;当 vCPU 重新切换到 pCPU 上运行时,其运行的上下文也会从 VMCS 中加载到 pCPU 上。这看起来有点像线程切换的动作,实际上 vCPU 对于宿主机而言就是一个线程。
通常情况下,虚拟机上运行的 GuestOS 的核心指令可以由计算机系统硬件直接执行,而不需要经过 VMM。当 GuestOS 执行特殊指令时,执行系统会切换为 VMM,让 VMM 来处理特殊指令。
简而言之,GuestOS 的指令集越多性能就越高,如果 GuestOS 拥有完全的 HostOS 指令集,GuestOS 性能就最高。
vCPU 的型号与热迁移
CPU 架构(型号)决定了 CPU 的性能及其应用特性,例如:Intel E5 系列的 CPU,主频相同的 Hasewell 架构就比 IvyBridge 架构的性能要高。在规模较大的 OpenStack 环境中,可能会存在多种不同 CPU 架构的服务器。从而导致 ComputeNode 计算能力与特性的不同,带来的问题是:
- 不同 CPU 架构的服务器之间无法进行虚拟机热迁移
- 无法统一虚拟机性能
Libvirt 主要支持三种 CPU mode:
- Host-passthrough:Libvirt 令 KVM 把宿主机的 CPU 指令集全部透传给虚拟机。因此虚拟机能够最大限度的使用宿主机 CPU 指令集,故性能是最好的。但是在热迁移时,它要求目的计算节点的 CPU 和源计算节点的完全一致。
- Host-model:Libvirt 根据当前宿主机 CPU 指令集从配置文件 /usr/share/libvirt/cpu_map.xml 中选择一种最相配的 CPU 型号。在这种模式下,虚拟机的指令集往往比宿主机少,性能相对 host-passthrough 要差一点,但是热迁移时,它允许目的计算节点的 CPU 和源计算节点的存在一定的差异。
- Custom:这种模式下虚拟机 CPU 指令集数最少,故性能相对最差,但是它在热迁移时跨不同型号 CPU 的能力最强。此外,Custom 模式下支持用户添加额外的指令集。
三种模式的性能排序是:host-passthrough > host-model > custom
三种模式的热迁移通用性是:custom > host-model > host-passthrough
大多数情况下,可以通过计算节点的配置文件 nova.conf 来指定 GuestOS 的 CPU 架构:
libvirt_cpu_mode:(字符串)用于设置虚拟机使用的 CPU 模式。如果 Libvirt virt_type 为 kvm|qume,那么默认值为 host-model,否则默认值为 None。
- host-model:克隆宿主机的 CPU 功能标志(Flags)
- host-passthrough:克隆主机的 CPU 架构
- custom:使用 named models 的 CPU 模型
- none:不设置任何 CPU 模型
libvirt_cpu_model:(字符串)设置虚拟机使用的 CPU 模型的名称,只能使用 /usr/share/libvirt/cpu_map.xml 文件中的一个 named models(此配置项仅在 libvirt_cpu_mode = custom 时有效)
NOTE:只有虚拟机化类型为 kvm 和 qemu 需要使用该配置项
NOTE:当 cpu_mode 设置为 custom 时,才能使用该配置,否则将导致错误,虚拟机也无法启动。
需要注意的是,实际环境中多采用 Intel E5 系列的 CPU,但是该系列的 CPU 也有多种型号,常见的有 Xeon,Haswell,IvyBridge,SandyBridge 等等。即使 Libvirt 使用了 host-model,在这些不同型号的 CPU 之间进行虚拟机热迁移也有可能失败。所以从热迁移的角度,在选择 host-mode 时应该注意:
- 需要充分考虑既有宿主机的 CPU 类型,以后采购扩容时,也需要考虑类型相同的问题
- 存在热迁移的场景,应用选择 host-passthrough
- host-model 下,不同型号的 CPU 最好能以 Host Aggregate 划分,在迁移时可以使用 HostAggregate Filter 来匹配具有相同 CPU 型号的计算节点,e.g.
openstack aggregate create Broadwell
openstack aggregate create Haswell
openstack aggregate set --property cpu=broadwell Broadwell
openstack aggregate set --property cpu=haswell Haswell
openstack aggregate add host <host1> Haswell
openstack flavor set --property aggregate_instance_extra_specs:cpu=broadwell <flavor1>
openstack flavor set --property aggregate_instance_extra_specs:cpu=haswell <flavor2>
- 如果 CPU 型号过多,而且不便于使用 HostAggregate 来做划分,建议使用 custom mode