之前机器学习k-近邻算法测试过MNIST手写体识别。
https://blog.csdn.net/xundh/article/details/73734509
本文使用TensorFlow进行MNIST手写体识别。
本文学习资源来自:http://www.tensorfly.cn/tfdoc/tutorials/mnist_beginners.html
MNIST数据集
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片。官网地址:Yann LeCun’s website
下载数据集
代码:
https://github.com/xundh/tensorflow-mnist-handwriting/blob/master/input_data.py
下载后数据集:
下载的数据集分成两部分,60000行的训练数据集(train)和10000行的测试数据集(t10k)。
每一个MNIST数据单元有两部分组成:一张包含手写数字的图片和一个对应的标签。 这里把图片设置“xs”,这些标签设为“ys”。 训练数据集和测试数据集都包含xs和ys,如训练数据集的图片是mnist.train.images,训练数据集的标签是mnist.train.labels。
每一张图片包含28像素*28像素,可以用一个数字数组来表示这张图片:
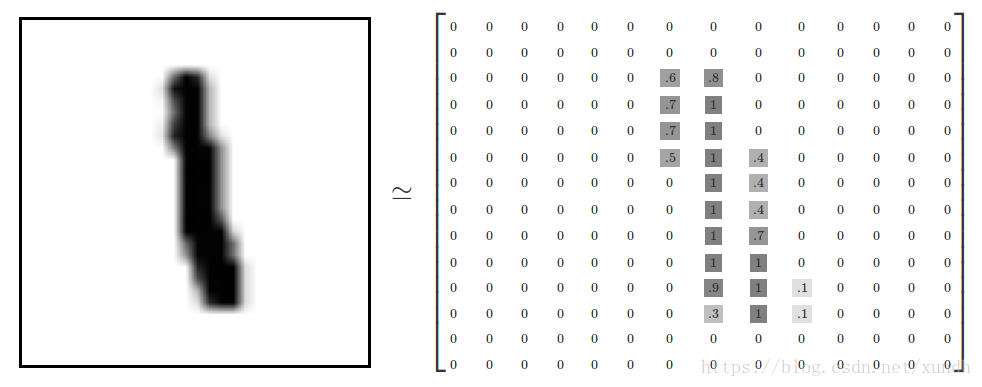
我们把这个数组展开成一个向量,长度是28*28=784。展平图片的数字数组会丢失图片的二维结构信息,这并非最理想的方式,最优秀的计算机视觉方法会挖掘并利用这些信息。 本文暂时忽略这些结构,所介绍的简单数学模型,softmax回归(softmax regression),不会利用这些结构信息。
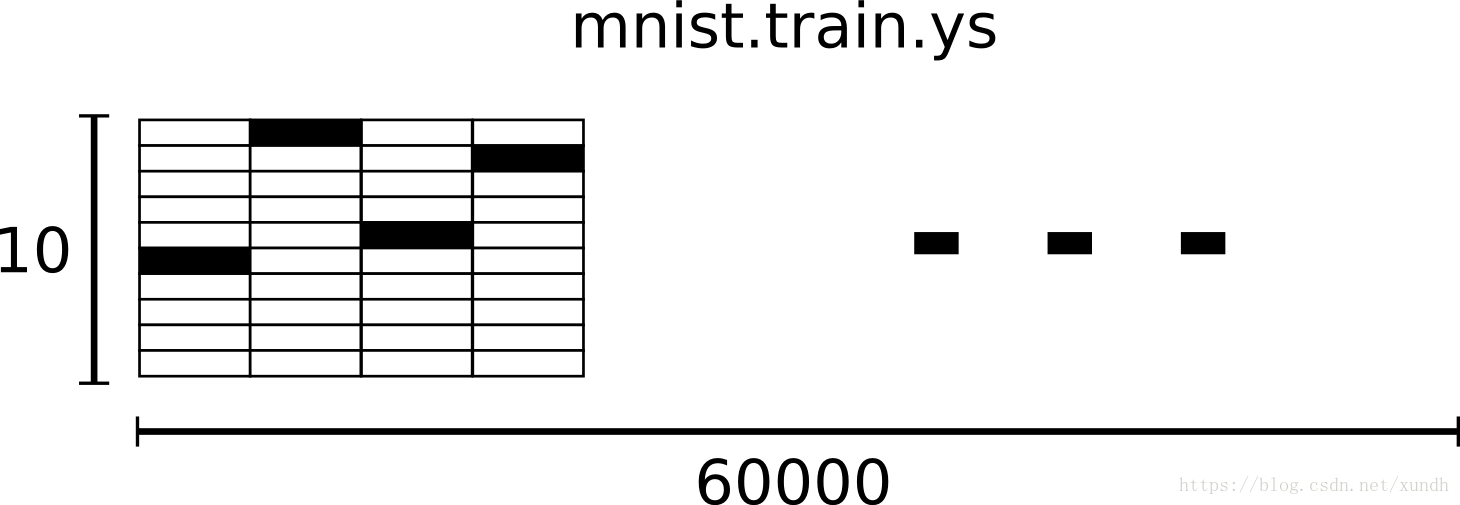
因此,在MNIST训练数据集中,mnist.train.images是一个形状为[60000,784]的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。在此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于0和1之间。

相对应的MNIST数据集的标签是介于0到9的数字,用来描述给定图片里的数字。 这个教程使用标签数据是"one-hot vectors"。一个one-hot向量除了某一位的数字是1以外其余各维度数字都是0。比如,标签0将表示成([1,0,0,0,0,0,0,0,0,0,0])。因此, mnist.train.labels 是一个 [60000, 10] 的数字矩阵。
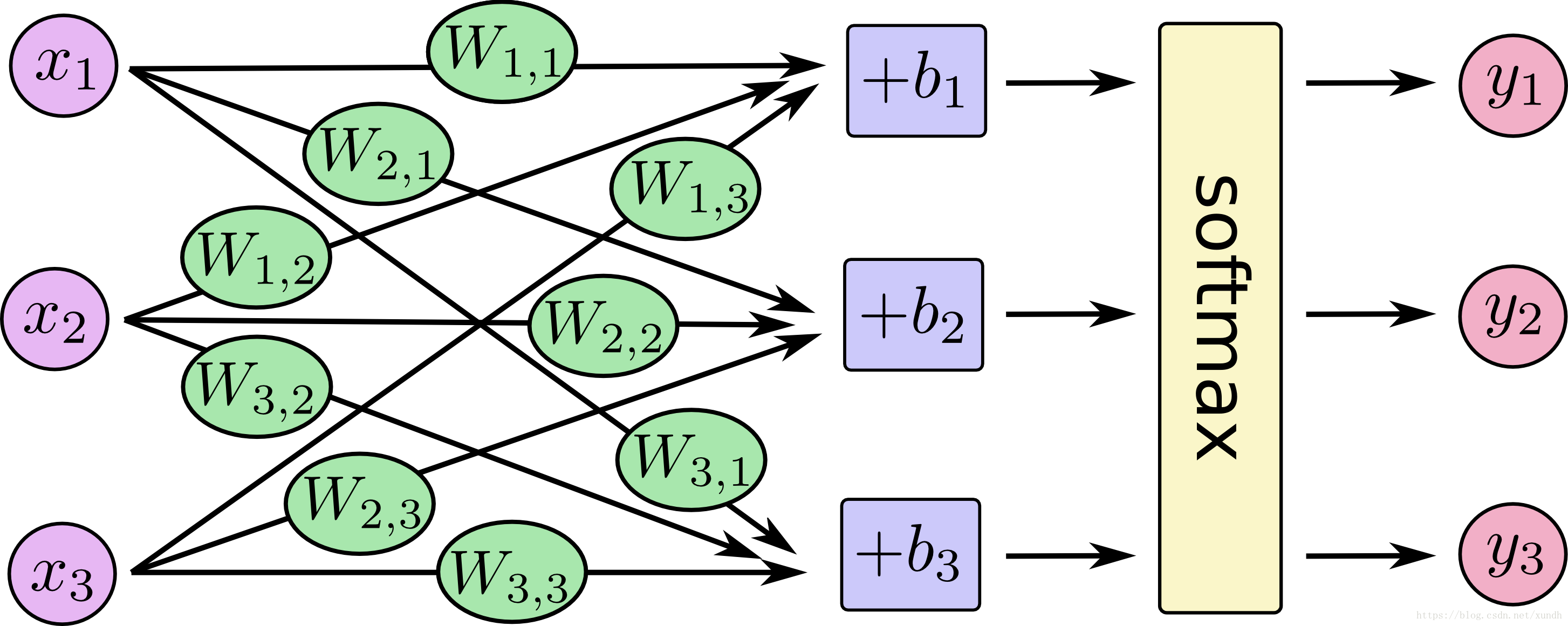
Softmax回归介绍
我们知道MNIST的每一张图片都表示一个数字,从0到9。我们希望得到给定图片代表每个数字的概率。比如说,我们的模型可能推测一张包含9的图片代表数字9的概率是80%但是判断它是8的概率是5%(因为8和9都有上半部分的小圆),然后给予它代表其他数字的概率更小的值。
这是一个使用softmax回归(softmax regression)模型的经典案例。softmax模型可以用来给不同的对象分配概率。即使在之后,我们训练更加精细的模型时,最后一步也需要用softmax来分配概率。
softmax回归模型:
代码示例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import input_data
import tensorflow as tf
# 60000行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test)
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# 每一个MNIST数据单元有两部分组成:一张包含手写数字的图片和一个对应的标签。我们把这些图片设为“xs”,把这些标签设为“ys”。
# 训练数据集和测试数据集都包含xs和ys,比如训练数据集的图片是 mnist.train.images ,训练数据集的标签是 mnist.train.labels。
# 每一张图片包含28像素X28像素。我们可以用一个数字数组来表示这张图片
# 我们赋予tf.Variable不同的初值来创建不同的Variable:在这里,我们都用全为零的张量来初始化W和b。因为我们要学习W和b的值,它们的初值可以随意设置。
x = tf.placeholder("float", [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# 实现softmax模型
y = tf.nn.softmax(tf.matmul(x, W) + b)
# 用来输入正确值
y_ = tf.placeholder("float", [None, 10])
# 计算交叉熵,这里交叉熵是所有100幅图片的交叉熵总和
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
# 用梯度下降 0.01学习率最小化交叉熵
# TensorFlow在这里实际上所做的是,它会在后台给描述你的计算的那张图里面增加一系列新的计算操作单元用于实现反向传播算法和梯度下降算法。
# 然后,它返回给你的只是一个单一的操作,当运行这个操作时,它用梯度下降算法训练你的模型,微调你的变量,不断减少成本。
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
# 初始化变量
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
# 模型循环训练1000次
for i in range(1000):
# 每步随机抓取训练数据中的100个批处理数据点
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
# tf.argmax给出某个tensor对象在某一维上的其数据最大值所在的索引值
# 由于标签向量是由0,1组成,因此最大值1所在的索引位置就是类别标签,
# 比如tf.argmax(y,1)返回的是模型对于任一输入x预测到的标签值,
# 而 tf.argmax(y_,1) 代表正确的标签,我们可以用 tf.equal 来检测我们的预测是否真实标签匹配(索引位置一样表示匹配)。
# 这行代码会给我们一组布尔值
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
# 把布尔值转换成浮点值,然后取平均值,如[True, False, True, True] 会变成 [1,0,1,1] ,取平均值后得到 0.75.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
# 计算所学习到的模型在测试数据集上面的正确率。
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
计算结果在0.91左右。这个结果是很差的,最好的模型可以超过99.7%的准确率。但这个模型是非常简单的。