版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/aFeiOnePiece/article/details/47624465
皮尔逊相似度是推荐算法中常见的 计算相似度的方法,其公式如下:
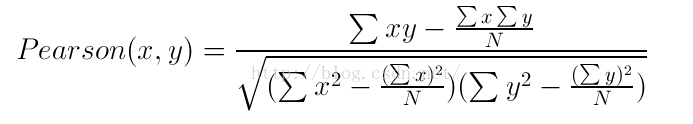
从公式可以看出 该算法有几个缺点:
1,如果用户A对所有item的评分都一样,那么将无法计算别人跟A的相似度(分母为0);所以该算法不适用于 boolean preference类型的推荐
2,如果用户A只对1个item进行了评分,那么也无法计算别人跟A的相似度(分母为0);所以对于数据量较小,或者矩阵非常之稀疏的数据都不太好用
3,如果2个人有200个common item,尽管ratings并不总是一样,但她们的相似度 可能好于2个只有2 commen item的人的相似度(这个我不能直接从公式看出来,哪位大神指点一下)
下面是python实现:
#!/usr/bin/python
import sys
# input 2 vector array
# output pearson correlation score
def PearsonCorrelationSimilarity(vec1, vec2):
value = range(len(vec1))
sum_vec1 = sum([ vec1[i] for i in value])
sum_vec2 = sum([ vec2[i] for i in value])
square_sum_vec1 = sum([ pow(vec1[i],2) for i in value])
square_sum_vec2 = sum([ pow(vec2[i],2) for i in value])
product = sum([ vec1[i]*vec2[i] for i in value])
numerator = product - (sum_vec1 * sum_vec2 / len(vec1))
dominator = ((square_sum_vec1 - pow(sum_vec1, 2) / len(vec1)) * (square_sum_vec2 - pow(sum_vec2, 2) / len(vec2))) ** 0.5
if dominator == 0:
return 0
result = numerator / (dominator * 1.0)
return result
vec1 = [5.0, 3.0, 2.5]
vec2 = [2.0, 2.5, 5.0]
print PearsonCorrelationSimilarity(vec1, vec2)