论文:SSH: Single Stage Headless Face Detector
论文链接:https://arxiv.org/abs/1708.03979
代码链接:https://github.com/mahyarnajibi/SSH
这篇ICCV2017关于人脸检测的文章提出SSH(single stage headless)算法有效提高了人脸检测的效果,主要改进点包括多尺度检测、引入更多的上下文信息、损失函数的分组传递等,思想比较简洁,效果也还不错。
SSH的网络结构如Figure2所示,整体设计是在VGG的基础上进行了改进,改进主要考虑2点:1、尺度不变性(scale-invariant)。输入图像中待检测的人脸尺度变化范围是比较大的,SSH需要在一个网络中同时检测不同尺度的人脸。2、引入更多的上下文信息(context)。更多的上下文信息对于人脸检测而言无疑是有帮助的。
尺度不变性是通过不同尺度的检测层实现,类似SSD、FPN等目标检测算法。具体而言一共有3个尺度的检测模块,检测模块(detection module)M1、M2、M3的stride分别是8、16、32,从图中也可以看出M1主要用来检测小尺寸人脸,M2主要用来检测中等尺寸人脸,M3主要用来检测大尺寸人脸。每个检测模块都包括分类和回归两个支路,用来输出人脸检测框。检测模块M2是直接接在VGG的conv5_3层之后,而检测模块M1的输入包含了较多的特征融合操作和维度缩减操作(dim red模块,将输入通道从512缩减为128,从而减少计算量)。
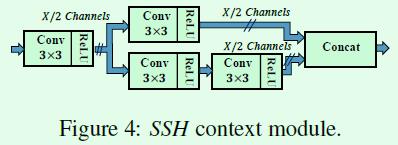
引入更多的上下文信息是通过在检测模块中嵌入context module实现的,context module的结构如Figure4所示,这部分通过扩大感受野达到引入更多上下文信息的目的,有点类似图像分割中常用的dilated convolution。

Figure3是检测模块示意图,分类和回归的特征图是融合了普通卷积层和上下文模块(context module)输出的结果,上下文模块会在后面介绍。分类和回归支路输出的K表示特征图上的每个点都设置了K个anchor,这K个anchor的宽高比例都是1:1(作者有通过实验证明增加宽高比例对于效果的提升帮助不到,但是会增加anchor数量),也就是K个不同大小的anchor。

Figure4是上下文模块(context module)示意图,原本是通过引入卷积核尺寸较大的卷积层(比如55和77)提高感受野,从而引入更多的上下文信息,为了减少计算量,借鉴了GoogleNet中用多个33卷积层代替55和77卷积层的做法,最终得到的上下文模块就如Figure4所示,而且还共享了其中1个33卷积层。
损失函数方面做了一些调整,公式如下所示。分类的损失函数还是采用常用的二分类损失函数,回归部分多了一个针对Ak的求和符号,这个Ak表示属于检测模块Mk的anchor,意思是对于不同尺度的检测模块而言,只回传对应尺度的anchor损失,这就实现了前面提到的M1主要用来检测小尺寸人脸,M2主要用来检测中等尺寸人脸,M3主要用来检测大尺寸人脸的目的。除此之外,在引入OHEM算法时也是针对不同尺度的检测模块分别进行的。
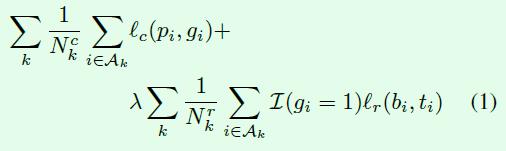
实验结果:
Table1是关于不同人脸检测算法在WIDER FACE数据集上的效果对比。HR算法的输入是图像金字塔,相比之下不采用图像金字塔的SSH算法反而优于相同特征提取网络的HR算法。最后一行的SSH(VGG-16)+Pyramid表示输入是图像金字塔,速度会比较慢。

Table2是关于SSH算法在不同尺寸输入时的速度对比。
