前言
参考《数据科学实战手册》第2章中汽车燃油效率数据分析的过程,不过原书是用R来进行分析,这里我们通过julia来完成整个分析过程),同时我们也将会进行比原文进行更多的内容拓展, 并在文章中尽可能多地介绍julia进行数据操作的方法,以期达到既走完整个分析流程,又加深了大家对julia的深入了解。
文章中所显示的代码如无特殊说明,均指 julia 代码,且工作环境为JuliaPro编辑器。
数据科学工作流
根据过往的经验,笔者将数据科学工作的完整流程大致总结如下图所示:
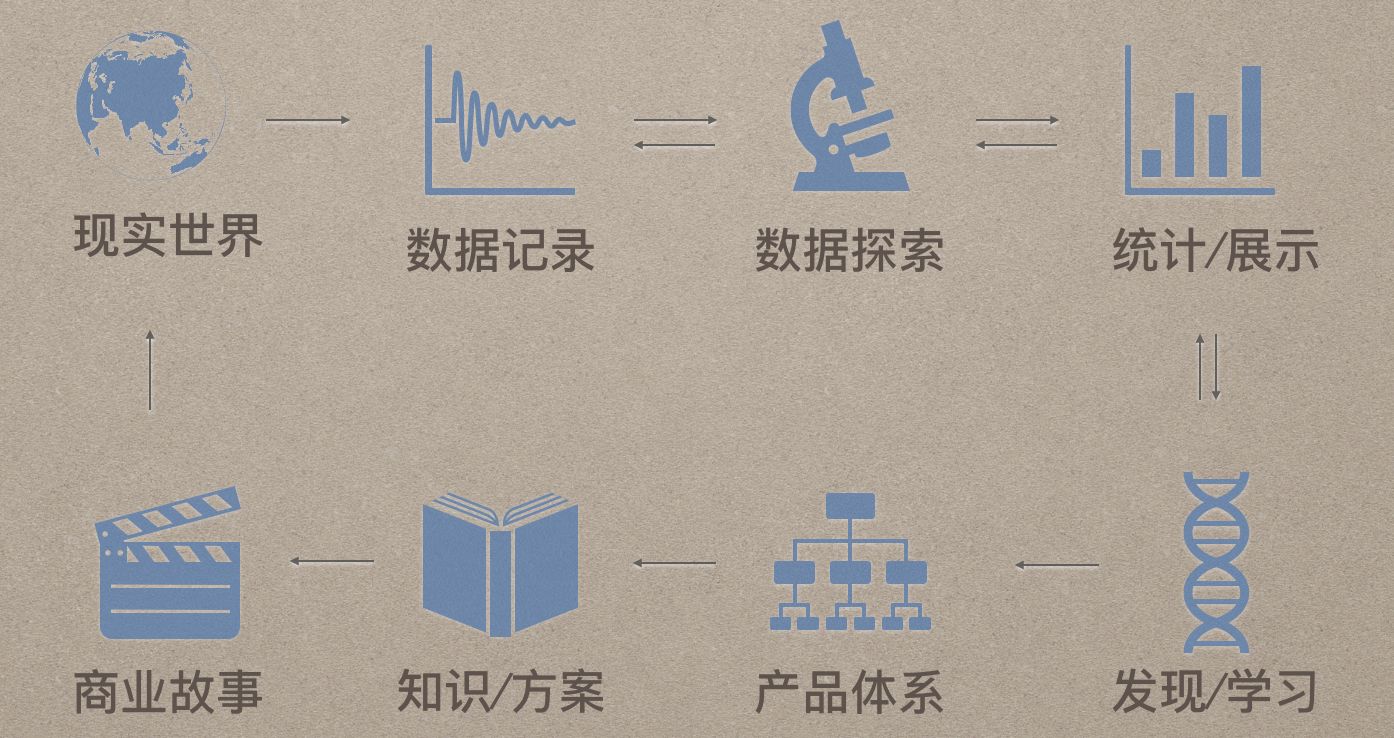
但在日常工作具体的case中,往往可能只涉及其中某几个环节。
业务问题
在进行分析前,首先要明确自己面临的业务问题是什么,通过数据分析想回答一个什么样的问题,或者想证明或证伪一个什么结论。
本文中,我们能拿到的是美国环保部门对汽车燃油经济性的评估数据。我们分析的目标就是找到影响汽车燃油效率的因素有哪些,哪些类型的汽车燃油效率更高。
数据导入
源数据可以从 https://fueleconomy.gov/feg/download.shtml 下载。
在julia中数据操作往往需要引入DataFrames包,这是与R、python中类似的一个数据结构。
using DataFrames
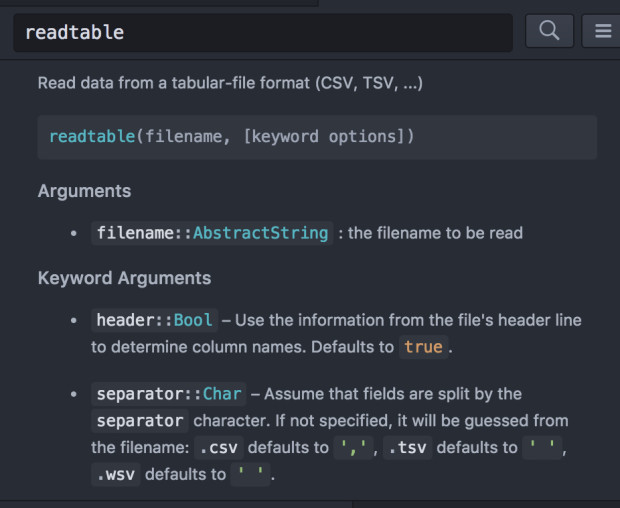
readtable("~/Downloads/vehicles.csv",header=true)readtable这个接口的详细说明如下图所示,其中最常用的就是文件名、是否包含字段名、文件分隔符这三个参数。
数据中每一行记录的是一个型号汽车的信息,核心的内容有(1)汽车的属性,如发动机类型、空间大小、传动装置等;(2)汽车燃油指标,如每加仑行驶里程数,每英里二氧化碳排放量等。
数据探索&预处理
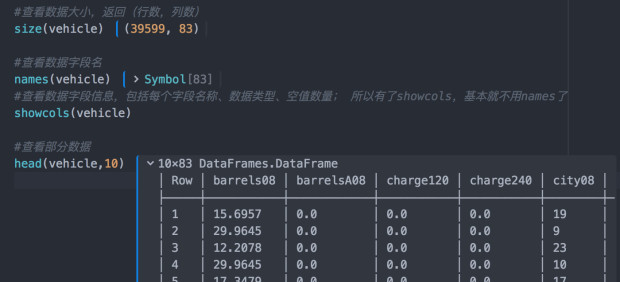
一些初步的数据探索如下图所示,在JuliaPro编辑器中每执行一步都会保留相关信息在命令语句后面(“|”后面即是)。
当我们想进行类似SQL中的group by 汇总时,有两种方法:
by(dataset, colname, aggr)
countmap(dataset[:colname])例如在本文中,我们可以如下统计燃油类型:

在数据预处理环节,往往需要处理下缺失值。让我们看下汽车的传动装置类型分布:
countmap(vehicle[:trany])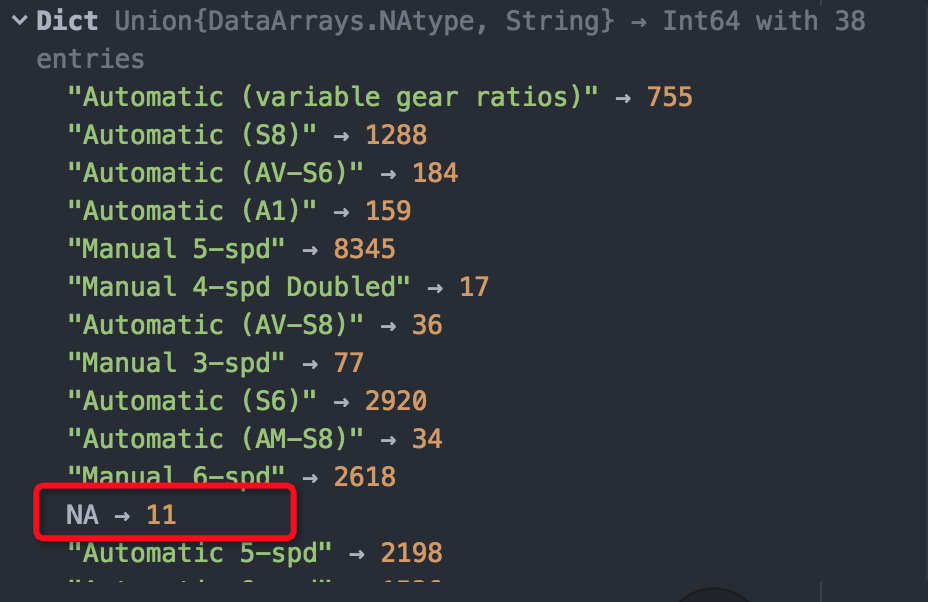
注意到其中空值的记录数为11。本文我们直接用字符串“NA”来填充空值:
vehicle[:trany][isna(vehicle[:trany])] = "NA" 同时,我们注意到trany这个变量离散值非常多,但其实本质上就“自动”与“手动”两种,因此我们可以创建一个新的变量,用来仅区分自动与手动的类型:
vehicle[:trany2] = [ifelse(length(x) >= 4 && x[1:4] .== "Auto", "Auto", "Manual") for x in vehicle[:trany]]
检查一下转换后的值与原值的对应关系:
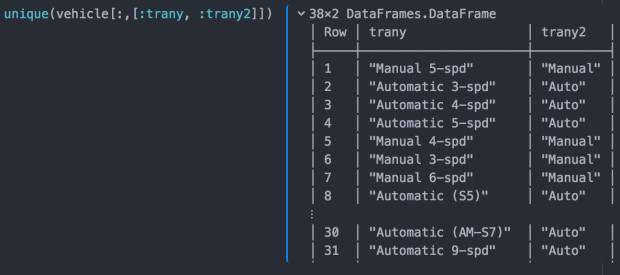
嗯,看上去是靠谱的。
数据分析
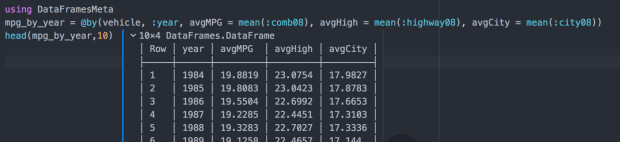
接下来我们想按年份观察一下随着时间发展,汽车燃油经济性的变化,可以通过MPG(每加仑行驶英里数)来刻画,原数据中MPG又分了高速公路情况下MPG(highway08)及城市道路情况下MPG(city08),以及综合情况下MPG(comb8)。这里需要引入一个新的包DataFramesMeta, 以实现类似R中dplyr那样的高效聚合操作:
用时间序列图来展示:
using Gadfly
plot(mpg_by_year, x = :year, y = :avgMPG, Geom.line, Geom.point)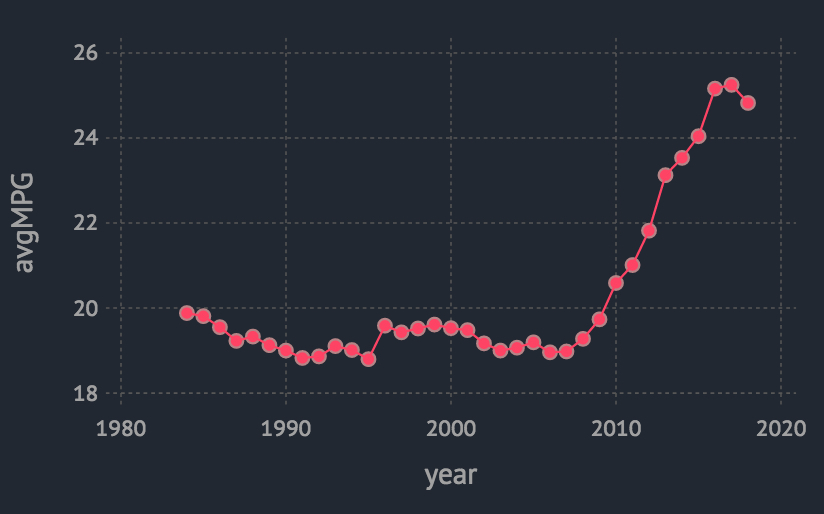
如果整体来看,貌似从2010前后,汽车的燃油经济性在提升(因为每加仑汽油行驶的里程数越来越大了),但是,因为我们并不知道该指标的确切口径,如果它仅仅是所有汽车总里程数除以所有汽车消耗汽油数得到的,那么是否非燃油的汽车是个干扰因素呢,因为分子的行驶里程中包括了这部分汽车的数据,但是分母(燃油量)中却肯定是不包含的。那么就需要把汽车燃油类型拆分开来看下喽(嗯,这里的提示点在于做数据分析时,要注意指标的口径是啥;同时,就像很多同学所说的,数据分析往往需要各种维度上的拆分和合并)。
先看一下燃油类型都有哪些?
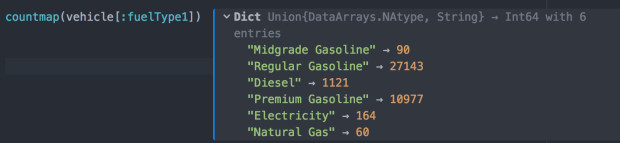
其中Gasoline类型的肯定是汽油燃油车,共有3种。
gasCars = vehicle[findin(vehicle[:fuelType1],("Midgrade Gasoline","Regular Gasoline","Premium Gasoline")),:]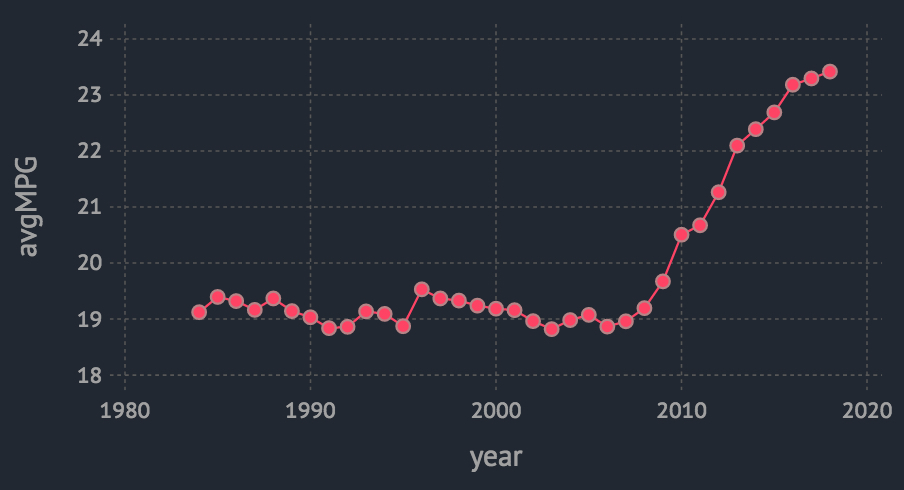
同时看一下非汽油车的销量占比趋势:
vehicle[:gasFlag] = [ifelse(contains(x, "Gasoline"), "Gas", "nonGas") for x in vehicle[:fuelType1] ]
#countmap(vehicle[:gasFlag])
nonGasCarNumStat = by(vehicle[vehicle[:gasFlag] .!= "Gas",:],:year, nrow)
totalCarNumStat = by(vehicle,:year, nrow)
#join two dataset
nonGasCarNumStat2 = join(nonGasCarNumStat,totalCarNumStat,on = :year)
nonGasCarNumStat2[:nonGasRatio] = [nonGasCarNumStat2[x,:x1]/nonGasCarNumStat2[x,:x1_1] for x in 1:length(nonGasCarNumStat2[:x1])]
plot(nonGasCarNumStat2,x= :year,y=:nonGasRatio,Geom.point,Geom.smooth)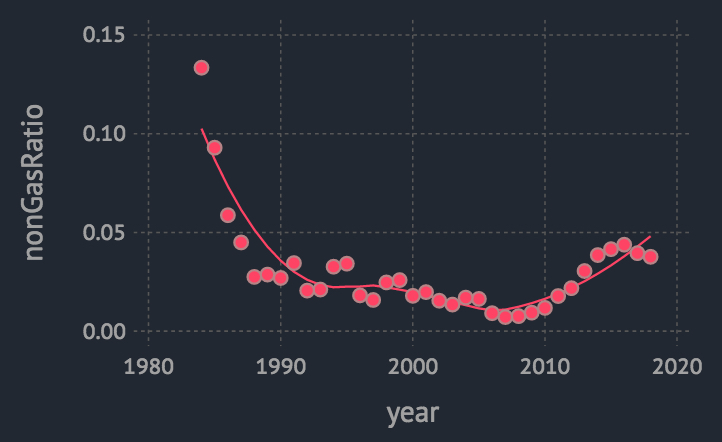
可见2010前后,非汽油车占比开始提升。不过1980-1990那段高比例是什么鬼? 我们把非汽油类再拆分类型来看下:
nonGasCarNumStat3 = by(vehicle[vehicle[:gasFlag] .!= "Gas",:],[:year,:fuelType1], nrow)
plot(nonGasCarNumStat3,x =:year, y = :x1, color = :fuelType1,Geom.line)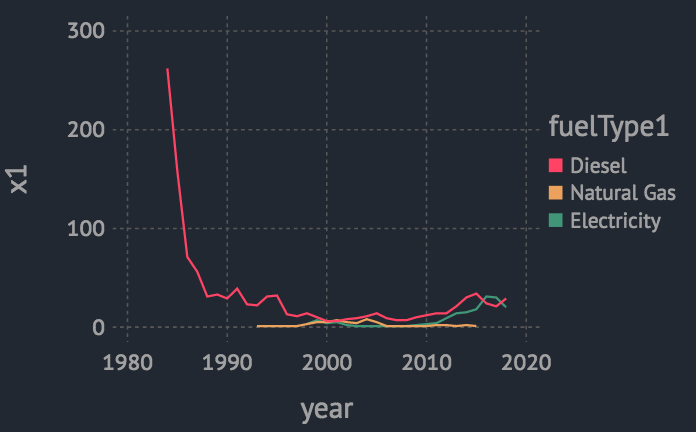
可见1980-1990期间,柴油车量级大幅下降。2010之后,电动汽车量级上升。
嗯哼,仅筛选汽油车后,MPG仍然是上升的,看来确实在整体上所有汽油车的燃油效率提升了。那么一定是发生了什么。比如,本身燃油更高效的汽车销量占比提升,油老虎类型的汽车销量在降低?(数据分析,往往是伴随着各种假设来进行的,先从业务经验和商业sense出发提出一些假设,然后从数据上寻找正面或负面的佐证。)
先来观察一下燃油效率与哪些因素存在相关性。注意到数据中有一个特征是汽车的引擎排量,看下该特征与燃油效率的相关性吧:
plot(gasCars[! isna(gasCars[:displ]),:], x = :displ, y = :comb08, Geom.point,Geom.smooth) 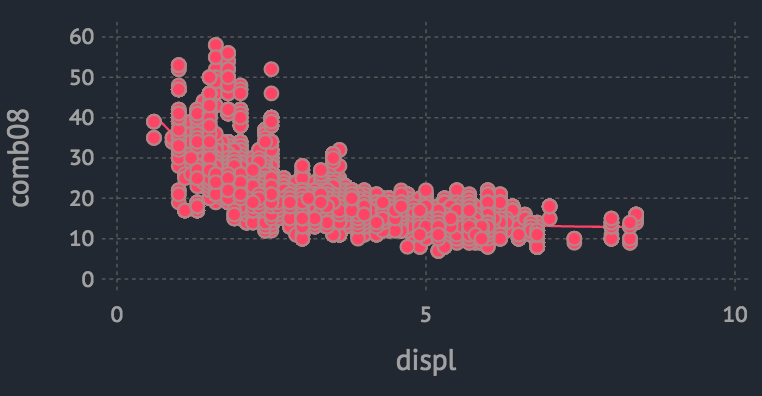
确实排量更大的汽车MPG值更低(每加仑行驶里程更短)。那么我们可以统计引擎平均排量的变化趋势:
avgCarSize = @by(gasCars, :year, avgDis = mean(:displ))
plot(avgCarSize, x = :year, y = :avgDis, Geom.point, Geom.smooth)
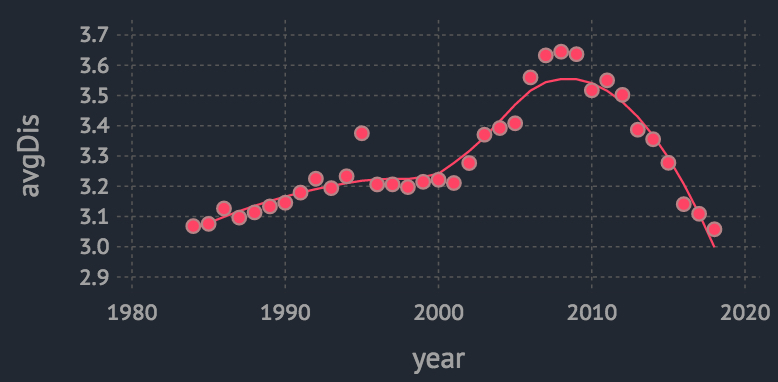
还真的在2010年前后出现拐点开始下降了。
我们再从手动档与自动档的区别上来。
autoCompareManu = @by(gasCars, [:year, :trany2], avgMPG = mean(:comb08), avgDisl = mean(:displ))
plot(autoCompareManu, x = :year, y = :avgMPG, group = :trany2,color = :trany2, Geom.line)
plot(autoCompareManu, x = :year, y = :avgDisl, group = :trany2,color = :trany2, Geom.line)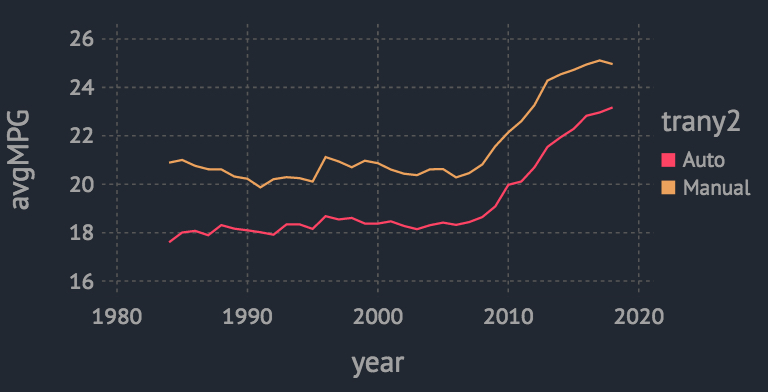
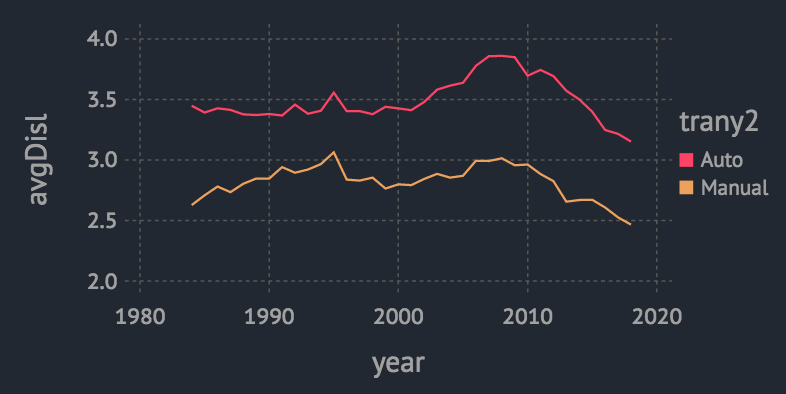
可见无论是自动档还是手动档,2010年前后都是一个明显的拐点,平均引擎排量出现下降,MPG上升。
截至目前我们能看到(1)电动汽车销量上升;(2)汽油车平均引擎排量在2010前后开始出现下降。那么2010年前后到底发生了啥,环保政策变化?技术创新?留作大家继续分析的小课题吧~