概述
Inception module中突出强调了卷积单元特征提取能力的强化对最后的分类效果有着很大的帮助,但是GoogLenet中的Inception module面临一个问题就是卷积模块太多,造成的计算量很大,特别是对于5x5这种大的卷积核,GoogLenet不得不采用1x1的卷积核先进行降维,然后再进行5x5的卷积。
但是,除了使用1x1卷积核进行降维,其实还有别的方式降低大的卷积核的计算量,这就是论文《Rethinking the Inception Architecture for Computer Vision》里提到的对卷积核进行Factorizing。
Factorizing Convolutions with Large Filter Size
先上一个直观的图,
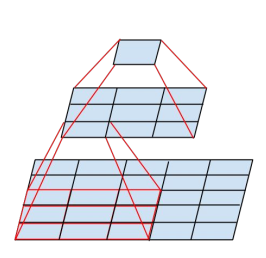
对于一个5x5卷积核卷积的区域,可以先使用一个3x3对5x5的区域进行卷积,然后再使用一个3x3核对刚刚的卷积结果再进行一次卷积,最终也是得出一个数据,在效果上和5x5卷积是等效的。这样就减少了一次卷积计算的次数,原来5x5卷积需要做25次乘加,现在两次3x3只需要做9+9=18次乘加,如果卷积核更大,减小的计算量也更大。
是基于什么考虑才做这种分解呢
我们可以看到分解导致卷积核的参数变小,这就说明原来5x5卷积核其实是有部分参数冗余的,即我们其实并不需要25个参数提取特征,而可能需要18个参数就可以了,这时因为由于提取区域像素都是紧邻的,像素之间的关联性很强,这都到时5x5卷积核各个参数之间其实也是有很强关联的,即参数存在冗余可以进一步压缩;进一步想,其实这是一种紧密网络到稀疏网络的转换。
上面所说的是大的卷积核分解成小的卷积核,论文中还提出了另一种分解方式,先上图,
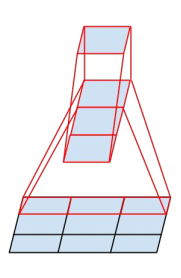
从图中可以看出,3x3的卷积,可以先用一个1x3的卷积,紧接着跟着一个3x1的卷积也是可以实现相同的输出的,同样对于5x5和7x7也是可以处理的,这样也可以明显降低卷积核参数和计算量。
这样想起来,其实VGG中每一打层卷积都有几个子层的3x3卷积,是不是也是出于这样考虑。利用3x3的卷积核实现更大的卷积核功能。
Utility of Auxiliary Classifiers
GoogLenet中就做过相似的工作,常规网络都是在最后一层计算loss,然后进行梯度方向传播,但是如果网络层很多,这就导致梯度消失的现象,使用Auxiliary Classifiers,在网络中间层加上分类器,计算辅助失真和梯度,然后把这个梯度加到常规网络的梯度上,有效解决了梯度消失的现象,其实这样做的方式,呼应了ResNet中解决梯度消失的问题得方法,虽然ResNet表面上看起来loss是在最后一层计算的,但是其实本质上最后一层的loss其实在ResNet的子网络中都有计算,也就相当于GoogLenet中把loss层加上网络中间层的方式。
Efficient Grid Size Reduction
以前的网络都是在卷积层后面加上一个pooling层来降低特征图的尺寸,但是这种降低尺寸的方式不可避免地有信息的损失,在《Rethinking Inception》论文中提出了另一种降低特征图尺寸的方式,先上图,
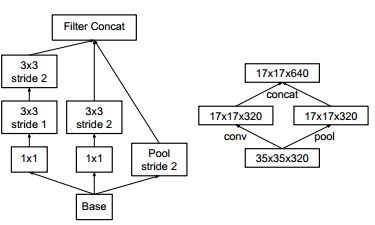
从图中可以看出降低尺寸是用过卷积加上合适的stride实现的,当然也有一个支路是通过pooling的方式实现,这种方式可以有效避免信息的损失,就像论文中所说:avoid the representation bottleneck
结论
《Rethinking Inception》提出了Inception-v3结构就是根据以上三个方面进行构建的,Top-1错误率18.77%,Top-5的错误率4.2%。效果是非常好的。但是其实我自己感觉感觉《Rethinking Inception》给我的思考更重要的是在文章开头的General Design Principles,这在以后对CNN有更深理解中再进行总结。