官方网站: https://lucene.apache.org/
Lucene初识
Apache顶级开源项目,Lucene-core是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的框架,提供了完整的查询引擎和索引引擎,部分文本分词引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。现在主流的搜索引擎Solr、ElasticSearch都是以Lucene为底层框架封装的。
适用场景
- 在应用中为数据库中的数据提供全文检索实现
- 开发独立的搜索引擎服务、系统
特性
- 稳定、索引性能高
- 每小时能够索引150GB以上的数据
- 对内存的要求小,只需要1MB的堆内存
- 增量索引和批量索引一样快
- 索引的大小约为索引文本大小的20%~30%
- 高效、准确、高性能的搜索算法
- 良好的搜索排序
- 强大的查询方式支持:短语查询、通配符查询、临近查询、范围查询等
- 支持字段搜索(如标题、作者、内容)
- 可根据任意字段排序
- 支持多个索引查询结果合并
- 支持更新操作和查询操作同时进行
- 支持高亮、join、分组结果功能
- 可扩展排序模块,内置包含向量空间模型、BM25模型可选
- 可配置存储引擎
- 跨平台
- 纯java编写
- 作为Apache开源许可下的开源项目,你可在商业或开源项目中使用
- Lucene有多种语言实现版可选(如C、C++、Python等),不光是Java
Lucene初识
请移步看完这篇文章:
https://blog.csdn.net/chenghui0317/article/details/10052103
一定要看,一定要看,一定要看!重要的事情说三遍!
看完以后绝对会对Lucene有一个全面的认识,Lucene所包含的东西可以归类为如下三项:
- 分词器如何进行分词的
- 索引是如何生成的
- 如何利用分词器与索引进行搜索的
分词器
顾名思义,分词器是用来分词的,比如下面一句话:
上海自来水来自海上
经过分词器后的解析后分为好几个词项,如下:
上海、自来水、来自、海上
那么解析后这么多的此项有什么用呢?如何保存索引才会被搜索到呢?这里就要谈到反向索引,要谈反向索引,先来聊聊正向索引。
正向索引
正向索引,简单理解其实就是我们做传统应用时数据库中保存记录的形式,比如:
| 文章ID | 文章标题 | 文章内容 |
|---|---|---|
| 1 | {上海、自来水} | {来自} |
| 2 | {上海} | {来自、海上} |
其中{}部分是表示内容中包含的一些关键字。我们很容易发现传统的存储形式是:
id --> 词项
面对这种存储形式,我们查询文章标题或者文章内容中是否包含某个词语的时候,一般只能:
SELECT * FROM TABLE WHERE 文章标题 LIKE '%上海%';
SELECT * FROM TABLE WHERE 文章标题 LIKE '%上海%' OR 文章内容 LIKE '%上海%';
可想而知,在面对大数据的时候,这种查询效率是极其低下的,甚至无法满足一些复杂场景,比如:关键字高亮、偏移量、词频等。这时候就要引入反向索引,专业人做专业事!毕竟数据库比较适合结构化数据的精确查询,而不适合半结构化、非结构化数据的模糊查询及灵活搜索(特别是数据量大时),无法提供想要 实时性。
反向索引
顾名思义,反向索引是正向索引反着来的,以词项为主关联文章ID的形式,如下:
| 词项 | 标题包含该词的文章id | 内容包含该词的文章id |
|---|---|---|
| 上海 | {1,2} | {1,2,7} |
| 自来水 | {1,2,3,4} | {1,2,9} |
我们很容易发现这种的存储形式是:
词项 --> id
这种存储的方式可以让我们根据查询的关键字很快的找出对应的文章,甚至还可以满足一些更复杂的场景,比如反向索引还可以记录词项出现的次数、出现的位置,如下:
| 词项 | 标题包含该词的文章id | 内容包含该词的文章id |
|---|---|---|
| 上海 | {{1,1,{0}},{2,2,{0,4}}} | {{7,2,{1,6}} |
| 自来水 | {{3,2,{1,5}},{4,1,{2}}} | {{2,1,{0}},{9,3,{1,5,9}}} |
{{2,1,{0}},{9,3,{1,5,9}}}解析:
9:文章id
3:出现次数
{1,5,9}:出现位置
这里就会提出一个问题,反向索引的数据量会非常大吗?
英文:所有的英文单词加起来应该不算多,十几万?几十万?
中文:中华词典上的中文单词总量貌似也就几十万
Lucene自带分词器
分词器有多种,有英文分词器、中文分词器、其他语言的分词器等。其中IKAnalyzer是属于常用的一种中文分词器。
在讲IKAnalyzer之前,先来感受一下Lucene自带的标准分词器的效果,直接上代码。
- maven工程,pom.xml中引入Lucene核心包
<!-- lucene 核心模块 --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>7.3.0</version> </dependency> <!-- Lucene提供的中文分词器模块,lucene-analyzers-smartcn --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-smartcn</artifactId> <version>7.3.0</version> </dependency>
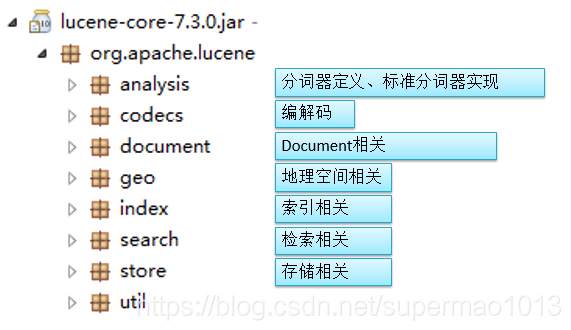
核心包内的各模块功能如下:
- main函数如下
import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.TokenStream; import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; import java.io.IOException; public class AnalizerTestDemo { private static void doToken(TokenStream ts) throws IOException { ts.reset(); CharTermAttribute cta = ts.getAttribute(CharTermAttribute.class); while (ts.incrementToken()) { System.out.print(cta.toString() + "|"); } System.out.println(); ts.end(); ts.close(); } public static void main(String[] args) throws IOException { String etext = "Analysis is one of the main causes of slow indexing. Simply put, the more you analyze the slower analyze the indexing (in most cases)."; String chineseText = "中华人民共和国简称中国。"; //核心包提供的标准分词器 try { Analyzer ana = new StandardAnalyzer(); TokenStream ts = ana.tokenStream("content", etext); System.out.println("标准分词器,英文分词效果:"); doToken(ts); ts = ana.tokenStream("content", chineseText); System.out.println("标准分词器,中文分词效果:"); doToken(ts); } catch (IOException e) { e.printStackTrace(); } // smart中文分词器 try { Analyzer smart = new SmartChineseAnalyzer(); TokenStream ts = smart.tokenStream("content", etext); System.out.println("smart中文分词器,英文分词效果:"); doToken(ts); ts = smart.tokenStream("content", chineseText); System.out.println("smart中文分词器,中文分词效果:"); doToken(ts); } catch (Exception e) { } } } - 运行结果如下
标准分词器,英文分词效果: analysis|one|main|causes|slow|indexing|simply|put|more|you|analyze|slower|analyze|indexing|most|cases| 标准分词器,中文分词效果: 中|华|人|民|共|和|国|简|称|中|国| smart中文分词器,英文分词效果: analysi|is|on|of|the|main|caus|of|slow|index|simpli|put|the|more|you|analyz|the|slower|analyz|the|index|in|most|case| smart中文分词器,中文分词效果: 中华人民共和国|简称|中国|
可以看出,Lucene自带的标准分词器对英文是通过空格进行分词的,对中文大部分是通过单字进行分词的,这种分词效果并不好。
而Lucene自带的smart分词器对中文分词效果很好,但对英文分词效果不好,因为无法过滤掉停用词。
停用词:不需要进行分词的词语,无关紧要的词语,每种语言都有相对应的停用词
中文停用词:你、我、它、的、了
英文停用词:is、the、we、in、of
项目集成IKAnalyzer分词器
IKAnalyzer是作为Lucene上使用而开发的,后面发展为独立的分词组件,只提供到Lucene4.0版本的支持,所以如果使用Lucene4.0以后版本的要简单集成一下IKAnalyzer。
- 第一步:maven工程pom.xml中加入依赖包
<!-- ikanalyzer 中文分词器 --> <dependency> <groupId>com.janeluo</groupId> <artifactId>ikanalyzer</artifactId> <version>2012_u6</version> <exclusions> <exclusion> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> </exclusion> <exclusion> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> </exclusion> <exclusion> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> </exclusion> </exclusions> </dependency> - 第二步:重新定义IKAnalyzer
原因:Lucene中的Analyzer类的抽象方法createComponents入参已经发生改变,而当前IK分词器中继承Analyzer的类IKAnalyzer重写该方法时入参是错误的,如下:
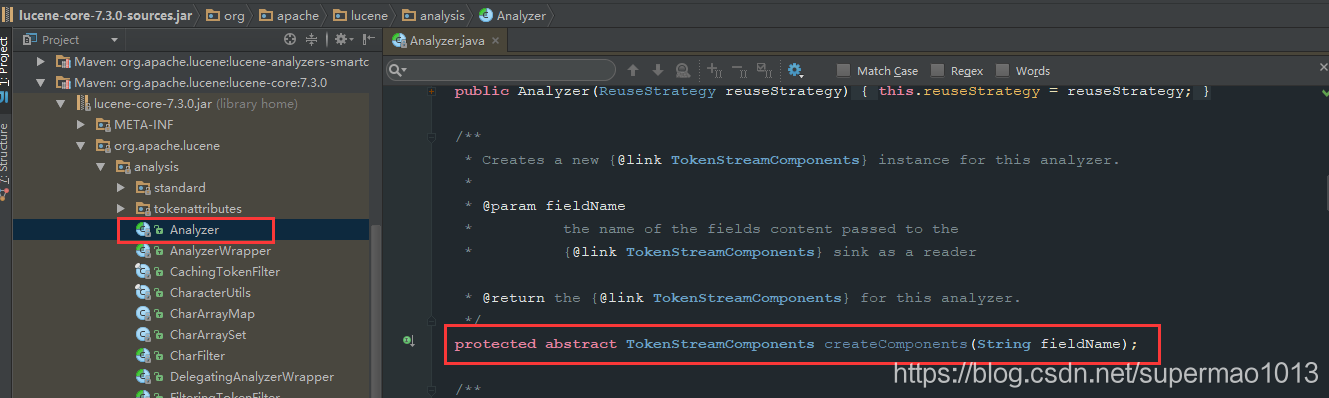

重新定义如下:import org.apache.lucene.analysis.Analyzer; public class IKAnalyzer4Lucene7 extends Analyzer { private boolean useSmart = false; public IKAnalyzer4Lucene7() { this(false); } public IKAnalyzer4Lucene7(boolean useSmart) { super(); this.useSmart = useSmart; } public boolean isUseSmart() { return useSmart; } public void setUseSmart(boolean useSmart) { this.useSmart = useSmart; } @Override protected TokenStreamComponents createComponents(String fieldName) { IKTokenizer4Lucene7 tk = new IKTokenizer4Lucene7(this.useSmart); return new TokenStreamComponents(tk); } }import java.io.IOException; import org.apache.lucene.analysis.Tokenizer; import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; import org.apache.lucene.analysis.tokenattributes.OffsetAttribute; import org.apache.lucene.analysis.tokenattributes.TypeAttribute; import org.wltea.analyzer.core.IKSegmenter; import org.wltea.analyzer.core.Lexeme; public class IKTokenizer4Lucene7 extends Tokenizer { // IK分词器实现 private IKSegmenter _IKImplement; // 词元文本属性 private final CharTermAttribute termAtt; // 词元位移属性 private final OffsetAttribute offsetAtt; // 词元分类属性(该属性分类参考org.wltea.analyzer.core.Lexeme中的分类常量) private final TypeAttribute typeAtt; // 记录最后一个词元的结束位置 private int endPosition; /** * @param useSmart */ public IKTokenizer4Lucene7(boolean useSmart) { super(); offsetAtt = addAttribute(OffsetAttribute.class); termAtt = addAttribute(CharTermAttribute.class); typeAtt = addAttribute(TypeAttribute.class); _IKImplement = new IKSegmenter(input, useSmart); } /* * (non-Javadoc) * * @see org.apache.lucene.analysis.TokenStream#incrementToken() */ @Override public boolean incrementToken() throws IOException { // 清除所有的词元属性 clearAttributes(); Lexeme nextLexeme = _IKImplement.next(); if (nextLexeme != null) { // 将Lexeme转成Attributes // 设置词元文本 termAtt.append(nextLexeme.getLexemeText()); // 设置词元长度 termAtt.setLength(nextLexeme.getLength()); // 设置词元位移 offsetAtt.setOffset(nextLexeme.getBeginPosition(), nextLexeme.getEndPosition()); // 记录分词的最后位置 endPosition = nextLexeme.getEndPosition(); // 记录词元分类 typeAtt.setType(nextLexeme.getLexemeTypeString()); // 返会true告知还有下个词元 return true; } // 返会false告知词元输出完毕 return false; } /* * (non-Javadoc) * * @see org.apache.lucene.analysis.Tokenizer#reset(java.io.Reader) */ @Override public void reset() throws IOException { super.reset(); _IKImplement.reset(input); } @Override public final void end() { // set final offset int finalOffset = correctOffset(this.endPosition); offsetAtt.setOffset(finalOffset, finalOffset); } } - 第三步:测试代码如下
import java.io.IOException; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.TokenStream; import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; import com.dongnao.lucene.demo.analizer.ik.IKAnalyzer4Lucene7; public class IkAnalyzerTestDemo { private static void doToken(TokenStream ts) throws IOException { ts.reset(); CharTermAttribute cta = ts.getAttribute(CharTermAttribute.class); while (ts.incrementToken()) { System.out.print(cta.toString() + "|"); } System.out.println(); System.out.println(); ts.end(); ts.close(); } public static void main(String[] args) throws IOException { String etext = "Analysis is one of the main causes of slow indexing. Simply put, "; String chineseText = "厉害了我的国一经播出,受到各方好评,强烈激发了国人的爱国之情、自豪感!"; try { // IKAnalyzer 细粒度切分 Analyzer ik = new IKAnalyzer4Lucene7(); TokenStream ts = ik.tokenStream("content", etext); System.out.println("IKAnalyzer中文分词器 细粒度切分,英文分词效果:"); doToken(ts); ts = ik.tokenStream("content", chineseText); System.out.println("IKAnalyzer中文分词器 细粒度切分,中文分词效果:"); doToken(ts); } catch (Exception e) { } try { // IKAnalyzer 智能切分 Analyzer ik = new IKAnalyzer4Lucene7(true); TokenStream ts = ik.tokenStream("content", etext); System.out.println("IKAnalyzer中文分词器 智能切分,英文分词效果:"); doToken(ts); ts = ik.tokenStream("content", chineseText); System.out.println("IKAnalyzer中文分词器 智能切分,中文分词效果:"); doToken(ts); } catch (Exception e) { } } } - 测试结果如下
IKAnalyzer中文分词器 细粒度切分,英文分词效果: analysis|is|one|of|the|main|causes|of|slow|indexing.|indexing|simply|put| IKAnalyzer中文分词器 细粒度切分,中文分词效果: 厉害|害了|我|的|国一|一经|一|经|播出|受到|各方|好评|强烈|激发|发了|国人|的|爱国|之情|自豪感|自豪|感| IKAnalyzer中文分词器 智能切分,英文分词效果: analysis|is|one|of|the|main|causes|of|slow|indexing.|simply|put| IKAnalyzer中文分词器 智能切分,中文分词效果: 厉|害了|我|的|国|一经|播出|受到|各方|好评|强烈|激|发了|国人|的|爱国|之情|自豪感|
IKAnalyze扩展
-
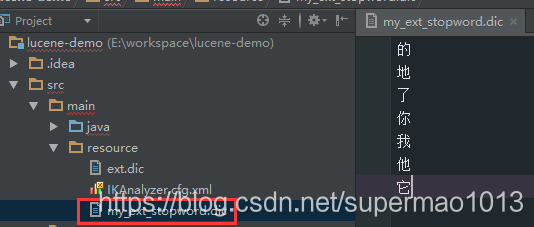
停用词扩展
IK中默认的停用词很少,需要扩展它,从https://github.com/cseryp/stopwords下载一份比较全的停用词。- 停用词文件中一行一个词,且文件必须是UTF-8编码,文件命名为my_ext_stopword.dic
- 文件存放于src/main/resource中
-
新词扩展
每年都会产生很多新词,比如网络用语等,因此需要维护一份新词词典- 新词文件中多个词语间用;隔开,且文件必须是UTF-8编码,文件命名为ext.dic
- 文件存放于src/main/resource中
-
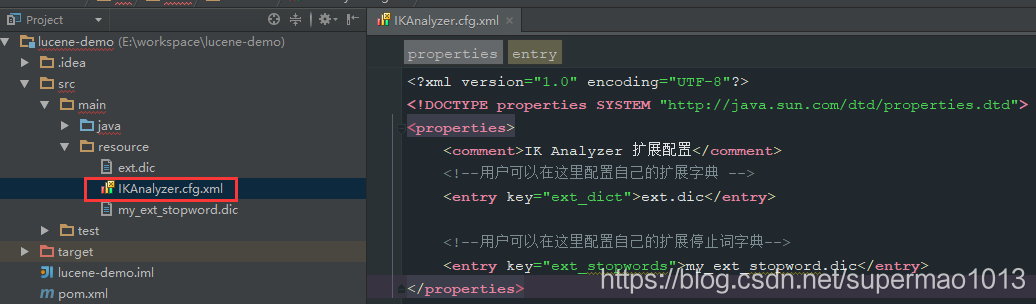
配置文件
上述两个文件中需要加入一个配置文件中才能生效- 新增一个配置文件,文件名为IKAnalyzer.cfg.xml
- 文件存放于src/main/resource中*
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">ext.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">my_ext_stopword.dic</entry> </properties>