表象和场景
最近小伙伴在凌晨0点40分左右会收到某台服务器报警,cpu使用率过高(达到95%),但是不到10分钟使用率降到45%,在之后5分钟内降到10%以内,服务恢复。
背景:公司是用微服务架构,某个产品大约有30多个微服务,前端用阿里云的SLB,架了nginx集群;
为了节省机器成本,某些机器上部署了多个服务,单个服务也部署在多个机器上,互为备份
通过consul来做服务注册与发现
分析
某个机器出现报警cpu过高,过几分钟就不会出现了,有时效性
排查思路:
思路一:根据监控内容查看;(包括这个机器的性能数据,应用服务日志等)
思路二:蹲点出现立马去服务器看现场信息;
思路三:时间节点比较特殊,按照经验,可能会出现的地方思考:半夜出问题周期这么奇怪,很有可能定时任务类没有处理好导致;
根据分析思路找问题
思路一:
根据监控查看机器性能数据,发现这个机器的B服务cpu使用率达到了80%,基本确认是该服务问题;
查看该服务日志,没有任何错误信息,看到接口调用情况中有异样,在接口监控中看到某个对外的接口被调用次数暴增,是平时的100倍+,而且都是A服务调用的,都集中在报警的这段时间内。确认是A服务发起的调用引起的问题;
查看A服务调用的地方,去排查业务,确认最终问题。
思路二:
蹲点出现立马去看现场信息:查看cpu使用情况,查看哪个进程使用率高,查看线程,数量和dump线程内容,具体干的事情,找到结果是B服务的某个对外接口执行线程多,查看日志或根据业务排查场景,得到是A服务调用引起的问题。
思路三:
通过定时任务出发,根据任务调度中心查看配置的定时任务时间,在这个周期之内的任务有哪些,针对具体的任务业务场景去分析,结合日志 和 代码 很快也可以找到问题了。
具体问题说明
A服务的部分代码说明:
分页从数据源中获取List<BillPlanPO>,调用如下process方法
@Async
public void process(List<BillPlanPO> billPlanPOs) {
if (CollectionUtils.isEmpty(billPlanPOs)) {
return;
}
billPlanPOs.forEach(item -> {
calLateFee(item);
});
}
calLateFee 方法内部调用B服务的接口。
1.分页从数据源获取数据速度很快
2.通过异步调用process方法(异步调用线程池没有自己配置,使用springboot框架自带的)
3.每一个billPlanPO去调用B服务的接口;而B服务处理一个的速度较慢。
结论:导致B服务瞬间压力很大,因为A服务获取List<BillPlanPO>速度很快,又是异步线程调用。
找到问题,解决过程就简单多了。
简单介绍下springboot中异步线程池
默认配置:
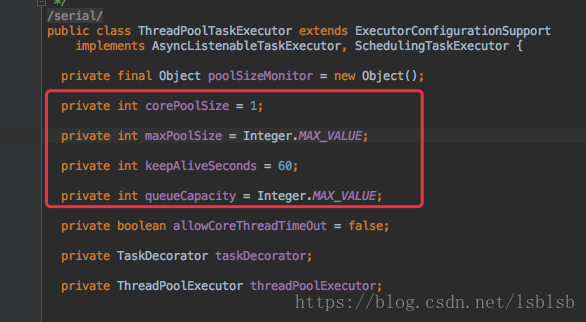
corePoolSize:表示线程池核心线程,正常情况下开启的线程数量。
queueCapacity:当核心线程都在跑任务,还有多余的任务会存到此处。
maxPoolSize:如果queueCapacity存满了,还有任务就会启动更多的线程,直到线程数达到maxPoolSize。如果还有任务,则根据拒绝策略进行处理。
针对如上问题,添加了下面代码:
import java.util.concurrent.ThreadPoolExecutor;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.task.AsyncTaskExecutor;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
/**
* 配置线程池
*/
@EnableAsync
@Configuration
public class ThreadPoolsConfig {
/**
* 线程相关参数
*/
@Value("${pay.threadNamePrefix}")
private String threadNamePrefix; // 配置线程池中的线程名称前缀
@Value("${pay.corePoolSize}")
private Integer corePoolSize; // 配置线程池中的核心线程数
@Value("${pay.maxPoolSize}")
private Integer maxPoolSize; // 配置最大线程数
@Value("${pay.queueCapacity}")
private Integer queueCapacity; // 配置队列大小
/**
* 线程池配置
*/
@Bean
public AsyncTaskExecutor paymentTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setThreadNamePrefix(threadNamePrefix);
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
/**
* 当任务数量超过MaxPoolSize和QueueCapacity时使用的策略,该策略是调用任务的线程执行
*/
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
return executor;
}
}另外几个细节注意点:
a.corePoolSize数量配置
/**
* IO密集型任务 = 一般为2*CPU核心数(常出现于线程中:数据库数据交互、文件上传下载、网络数据传输等等)
* CPU密集型任务 = 一般为CPU核心数+1(常出现于线程中:复杂算法)
* 混合型任务 = 视机器配置和复杂度自测而定
*/
private static int corePoolSize = Runtime.getRuntime().availableProcessors();
b.当队列满了之后的处理,setRejectedExecutionHandler,根据场景看需要怎么样的拒绝策略
ThreadPoolExecutor自身提供了4种策略
1.CallerRunsPolicy :这个策略重试添加当前的任务,他会自动重复调用 execute() 方法,直到成功。
2.AbortPolicy :对拒绝任务抛弃处理,并且抛出异常。
3.DiscardPolicy :对拒绝任务直接无声抛弃,没有异常信息。
4.DiscardOldestPolicy :对拒绝任务不抛弃,而是抛弃队列里面等待最久的一个线程,然后把拒绝任务加到队列。
扯远了,打住,根据调整,测试环境走一波。
验证与观察
通过各种工具压一波,问题已解决,根据资源情况配置合适的线程池参数。
发布后,线上验证通过,晚上可以安静的睡觉了~
其他建议
大部分线上问题,都是一个很小的点引起的,排查是一个反向推导的过程,这个过程往往比理解原因或者解决问题复杂。
问题排查是复杂的,不可控的,所以不要把排查和解决混在一起,尽量先解决、再排查。解决的方式基本上都是那么几板斧:重启、回滚、扩容、降级、迁移等。
系统要尽可能的对外暴露内部状态和干预手段,比如说少打了一句日志,没把变量输出出来,那么出现问题的时候很不但要用某些复杂的工具去查询变量,而且很有可能要多绕一个大圈。
系统是不稳定的,所以对于高可用架构设计来说,隔离是必须的,不管是何种依赖方式,都需要考虑“实在不行了”的情况。
问题的原因、传播路径和现象不是一一对应的。同一个问题,这次的表现是多打了一行WARN日志,下次可能就是一次系统雪崩。墨菲定律,如果有可能出问题,那一定会出问题。
提前准备
a.监控
b.日志(分维度过滤和查询),集中检索
c.保存现场
d.报警机制,(机器与服务,业务层数据)
这个4点可以单独写很多内容,这里只是备注下,出了问题才会想到这些内容何其重要,所以平时要更加积累去处理。
排查问题不是一个人的事情,最好拉个消防群,把各个岗位的人员一起处理(开发,运维,DBA,系统,硬件等),大家工作的细分也是有道理的,专业的人干专业的事情。问题一定要先解决再排查,问题一定要先解决再排查,问题一定要先解决再排查~