版权声明:欢迎转载,若有不当之处请在评论中指出,共同交流。 https://blog.csdn.net/qq_33290787/article/details/51942750
我们都知道,SQL查询时若产生了临时表,一般要消耗更多的内存,降低查询的效率。因此,当查询时产生了临时表,要进行优化,使引擎在查询时不用创建临时表就能完成查询。
示例使用的是MySQL示例数据库sakila。actor表中有一个主键actor_id,演员的first_name与last_name。film_actor表中外键列actor_id,与actor表进行连接,其中actor_id有很多重复的值,同时actor_id也是主键列(不自增)。
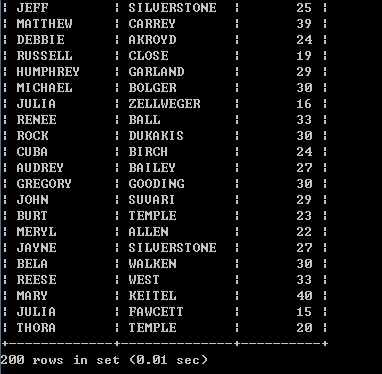
执行语句:SELECT first_name,last_name,COUNT(*) FROM film_actor INNER JOIN actor USING(actor_id) GROUP BY film_actor.actor_id;
结果(返回了很多演员的名字与演过的电影数量):
执行计划:
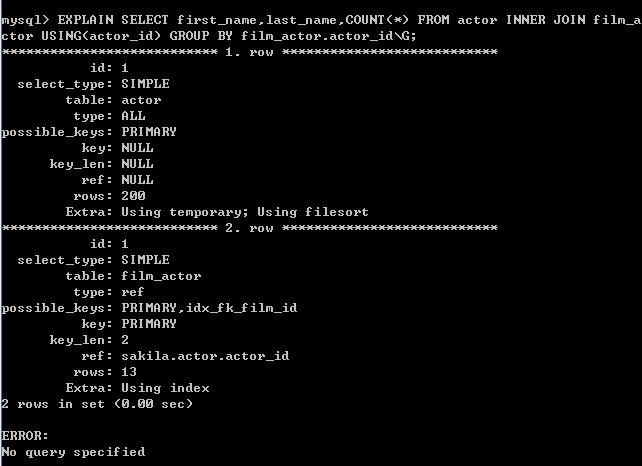
由于在检索actor表时产生了临时表(文件排序一般也伴随出现)。该SQL效率与性能有待提高。
产生临时表的原因有很多,一般有五种情况:
- 如果GROUP BY 的列没有索引,产生临时表.
- 如果GROUP BY时,SELECT的列不止GROUP BY列一个,并且GROUP BY的列不是主键 ,产生临时表.
- 如果GROUP BY的列有索引,ORDER BY的列没索引.产生临时表.
- 如果GROUP BY的列和ORDER BY的列不一样,即使都有索引也会产生临时表.
- 如果GROUP BY或ORDER BY的列不是来自JOIN语句第一个表.会产生临时表.
下面就来优化SQL语句使临时表不再产生就能完成查询,准则就是尽量把大查询分开为小查询:
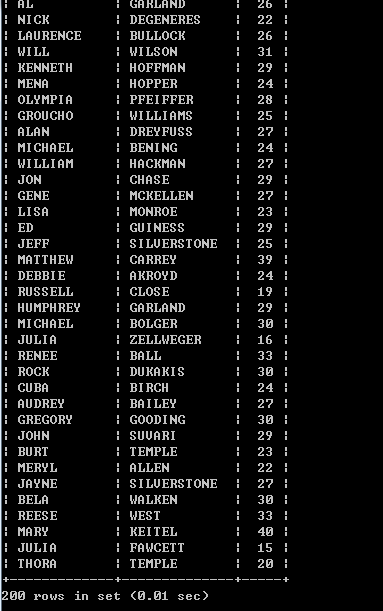
调优后的执行语句:SELECT first_name,last_name,c.cnt FROM actor INNER JOIN (SELECT actor_id,COUNT(*) AS cnt FROM film_actor GROUP BY actor_id) AS c USING(actor_id);
执行结果(同上):
执行计划:
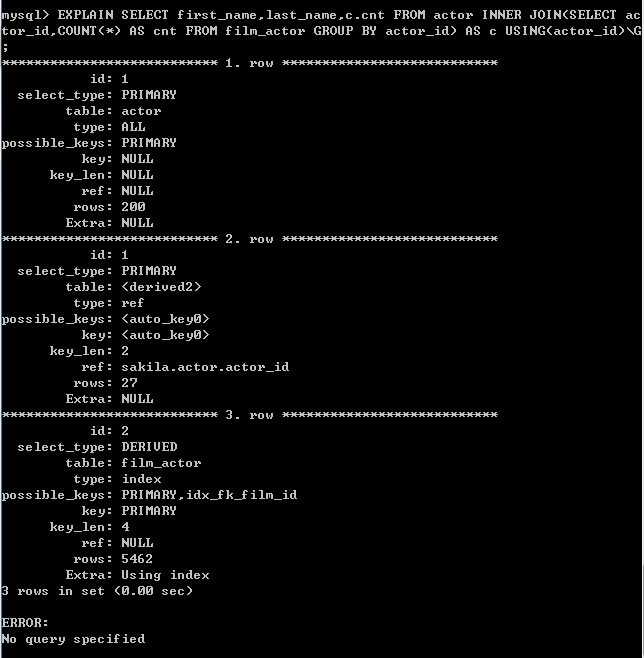
可见不再有临时表的产生以及文件排序。
两次慢查询日志的比较:
# Time: 160718 15:28:05
# User@Host: root[root] @ localhost [127.0.0.1] Id: 37
# Query_time: 0.013001 Lock_time: 0.000000 Rows_sent: 200 Rows_examined: 6062
SET timestamp=1468826885;
SELECT first_name,last_name,COUNT(*) FROM film_actor INNER JOIN actor USING(actor_id) GROUP BY film_actor.actor_id;
# Time: 160718 15:37:19
# User@Host: root[root] @ localhost [127.0.0.1] Id: 37
# Query_time: 0.006000 Lock_time: 0.000000 Rows_sent: 200 Rows_examined: 5862
SET timestamp=1468827439;
SELECT first_name,last_name,c.cnt FROM actor INNER JOIN(SELECT actor_id,COUNT(*) AS cnt FROM film_actor GROUP BY actor_id) AS c USING(actor_id);
优化后的查询没有临时表的产生,时间效率更高,性能更好。