本文从便于理解的角度介绍对偶上升法,略去大部分数学推导,目的是帮助大家看懂论文中的相关部分。
阅读本文前,请先参看这篇博客《共轭函数超简说明》。
对偶函数1
也称为拉格朗日对偶函数(Lagrange dual function)。
拉格朗日量
考虑定义域
有
这个最优化问题的拉格朗日量(Lagrangian)为:
其物理意义参见这篇博客《拉格朗日乘子法超简说明》。
其中
拉格朗日量是关于
x,λ,ν 的函数。
拉格朗日对偶函数
对于定义域
拉格朗日对偶函数是关于对偶变量
λ,ν 的函数
拉格朗日对偶函数可以看做是
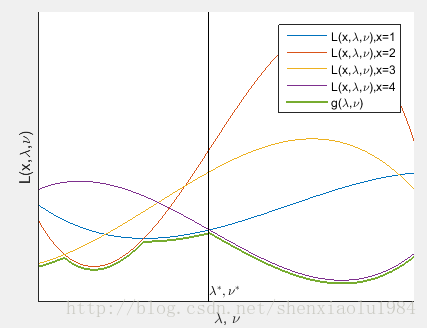
当
于是,该解对应的曲线不超过原问题最优解:
进一步,所有曲线的下界不超过原问题最优解:
换言之
λ>0 时,拉格朗日对偶函数是最优化值的下界。
对偶函数与共轭函数
考虑线性约束下的最优化问题
其对偶函数:
提取和
线性约束下的对偶函数可以用共轭函数表示。
其自变量为拉格朗日乘子的线性组合。
对偶问题2
上图绿线上的最高点,是对于最优化值下界的最好估计:
这个问题称为原优化问题的拉格朗日对偶问题(dual problem)。
如果
- 强对偶条件成立3
- 对偶问题存在最优解
λ¯,ν¯
则:原问题
换言之:
原问题和对偶问题通过拉格朗日量联系了起来。
如果
- 求解
maxg(λ,ν) 得到λ¯,ν¯ - 求解
minL(x,λ¯,ν¯) 得到x¯
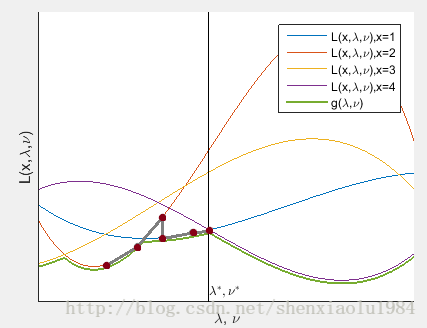
对偶上升法5
利用原问题和对偶问题的上述关系,有如下推论:
设第
- 假设
λk,νk 已经为对偶问题最优解 - 根据上述等价性,最小化
L(x,λk,νk) 能得到原问题最优解xk+1
xk+1=argminxL(x,λk,νk) -
L(x,λk,νk) 是λk,νk 位置上,不同x 对应的L 取值 - 所以,
x=xk+1 的曲线处于所有曲线最下面。即g(λk,νk)=L(xk+1,λk,νk) - 在该位置使用梯度上升法更新对偶问题解
λk+1=λk+α⋅∂L(x,λ,ν)∂λ|x=xk+1,λ=λk,ν=νk
这一方法称为对偶上升法。下图的灰线示出解的变化:
- S. Boyd and L. Vandenberghe, Convex Optimization. Cambridge University Press, 2004.
§ 5.1 ↩ - S. Boyd and L. Vandenberghe, Convex Optimization. Cambridge University Press, 2004.
§ 5.2 ↩ - S. Boyd and L. Vandenberghe, Convex Optimization. Cambridge University Press, 2004.
§ 5.5.5 ↩ - S. Boyd and L. Vandenberghe, Convex Optimization. Cambridge University Press, 2004.
§ 5.5.5 ↩ - S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning, 2011.
§ 2.1 ↩