一、基础语法
SELECT 语句用于从表中选取数据,结果被存储在一个结果表中(称为结果集)。
SQL SELECT 语 法
SELECT 列名称 FROM 表名称
SELECT * FROM 表名称
提示:星号(*)是选取所有列的快捷方式。
二、基本的SELECT语句
1、语法
SELECT *|{[DISTINCT] column|expression [alias],...}
FROM table;- SELECT 标识选择哪些列。
- FROM 标识从哪个表中选择。
2、选择全部列(*)
SELECT *
FROM departments;3、选择特定的列
SELECT department_id, location_id
FROM departments;4、使用细节和注意事项
1) SQL 语言大小写不敏感。
#sql语言不区分大小写
#日期和字符只能在单引号('')中出现
#mysql中字符也不区分大小写。而sql规范中,是区分大小写的。比如:oracle
SELECT employee_id,last_name,department_id
FROM employees
WHERE last_name = 'King'2) SQL 可以写在一行或者多行
3) 行结尾以分号(;)结束
4) 关键字不能被缩写也不能分行
5) 各子句一般要分行写。
6) 使用缩进提高语句的可读性
7) 日期和字符只能在单引号(”)中出现。
8) 数值可以使用引号,也可以不使用引号,建议不要使用引号。在Mysql中单引号是否使用不影响查询数据
5、列的别名:
• 重命名一个列。
• 便于计算。
• 紧跟列名,也可以在列名和别名之间加入关键字‘AS’,别名使用双引号,以便在别名中包含空格或特殊的字符并区分大小写。
• 可以使用双引号(”“),给列起别名
SELECT last_name AS name, commission_pct comm
FROM employees;
SELECT last_name "Name", salary*12 "Annual Salary"
FROM employees;6、字符串
日期和字符只能在单引号中出现。
每当返回一行时,字符串被输出一次。
Mysql中单引号不区分大小写,但是Oracle区分大小写
7、显示表结构
使用 DESCRIBE(DESC) 命令,表示表结构
USE myemployees;
SELECT * # *:查询表中所有的列
FROM employees;
SELECT employee_id,last_name,email
FROM employees;
#列的别名
#as: alias
#可以使用一对"",给列起别名
SELECT employee_id emp_id,last_name AS lname,12 * salary "annual sal",email AS "邮箱"
FROM employees;
#日期和字符只能在单引号('')中出现
#显示表结构
DESC employees;
DESCRIBE departments;三、过滤数据
1、过滤——关键字WHERE
- 使用WHERE 子句,将不满足条件的行过滤掉。
- WHERE 子句紧随 FROM 子句。
- 不能使用别名过滤, 排序
#返回在 90号部门工作的所有员工的信息
SELECT employee_id,last_name,department_id
FROM employees
#过滤语句,声明在from之后
WHERE department_id = 90;
2、比较运算

赋值使用 := 符号
#比较运算符:= >= <= > < <> !=
SELECT employee_id,last_name,department_id
FROM employees
#where department_id > 90;
#WHERE department_id <> 90;
#where department_id != 90;
WHERE last_name > 'King';3、其它比较运算

4、关键字解析:
BETWEEN:
使用 BETWEEN 运算来显示在一个区间内的值
IN
使用 IN运算显示列表中的值。
LIKE (模糊查询)
使用 LIKE 运算选择类似的值
选择条件可以包含字符或数字:
%代表零个或多个字符(任意个字符)。
_代表一个字符。
‘%’和‘-’可以同时使用。
ESCAPE
- 回避特殊符号的:使用转义符。例如:将[%]转为[ _],然后再加上[ESCAPE ‘$’] 即可。
- 如果使用\表示转义,要省略escape。如果不是\,则要加上escape。
NULL
使用 IS (NOT) NULL 判断空值。
#其他比较操作符:
#① between ... and (包含边界!) lowerlimit and upperlimit
SELECT employee_id,last_name,department_id
FROM employees
WHERE department_id BETWEEN 70 AND 90;
#where department_id >= 70 and department_id <= 90;
# 错误的写法。
#where department_id between 90 and 70;
# ② in(..,...,....)
SELECT employee_id,last_name,department_id,salary
FROM employees
#where salary = 6000 or salary = 7000 or salary = 8000;
WHERE salary IN (6000,7000,8000);
# ③ like : 模糊查询
#查询姓名中包含字符'a'的人
# %:表示任意多个字符。包括0个字符
SELECT last_name
FROM employees
WHERE last_name LIKE '%a%';
#查询姓名中最后一个字符是'a'的人:
SELECT last_name
FROM employees
WHERE last_name LIKE '%a';
#查询姓名中第3个字符是'a'的人:
# _:表示一个不确定的字符
SELECT last_name
FROM employees
WHERE last_name LIKE '__a%';
#转义字符:\
#查询姓名中第2个字符是_,且第3个字符是'a'的人:
SELECT last_name
FROM employees
WHERE last_name LIKE '_\_a%'; #"韩老师好\"帅\"啊!"
#转义符:ESCAPE
SELECT last_name
FROM employees
WHERE last_name LIKE '_$_a%' ESCAPE '$';
# ④ is null
SELECT employee_id,last_name,commission_pct
FROM employees
WHERE commission_pct IS NULL;
# ⑤is not null
SELECT employee_id,last_name,commission_pct
FROM employees
WHERE commission_pct IS NOT NULL;5、逻辑运算
AND
AND 要求并的关系为真。
OR
OR 要求或关系为真。
NOT
#and
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary >=10000
AND job_id LIKE '%MAN%';
#or
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary >=10000
OR job_id LIKE '%MAN%';
#not
SELECT last_name, job_id
FROM employees
WHERE job_id
NOT IN ('IT_PROG', 'ST_CLERK', 'SA_REP');四、排序
1、ORDER BY子句
使用 ORDER BY 子句排序
ASC(ascend): 升序
DESC(descend): 降序ORDER BY 子句在SELECT语句的结尾。
按别名排序
多个列排序(二级排序)
- 按照ORDER BY 列表的顺序排序。
- 可以使用不在SELECT 列表中的列排序
# 排序数据: order by
# 按照工资从低到高的顺序排序
# asc(ascend):升序
# desc(descend):降序
SELECT employee_id,last_name,salary
FROM employees
ORDER BY salary; #默认为升序排列
SELECT employee_id,last_name,salary
FROM employees
#ORDER BY salary desc;
ORDER BY last_name DESC;
#二级排序
SELECT employee_id,last_name,salary,department_id
FROM employees
ORDER BY department_id ASC,salary DESC;
# 可以使用列的别名进行排序
SELECT employee_id,last_name,salary,department_id dept_id
FROM employees
ORDER BY dept_id;
#注意,不可以使用别名进行数据的过滤!
#如下操作是错误的!
SELECT employee_id,last_name,salary,department_id dept_id
FROM employees
WHERE dept_id = 70;
五、数据去重:DISTINCT
#数据去重
# 员工表中员工所在的部门都有哪些?
SELECT DISTINCT department_id
FROM employees;
六、多表查询
1、笛卡尔集
1) 笛卡尔集会在下面条件下产生:
- 省略连接条件
- 连接条件无效
- 所有表中的所有行互相连接
2)为了避免笛卡尔集, 可以在 WHERE 加入有效的连接条件。
#查询员工的id,name,部门名称
#笛卡尔集的错误:进行多表的查询操作时,没有声明多表的连接条件或多表的连接条件失效。
SELECT employee_id,last_name,department_name
FROM employees,departments; #2889
SELECT 2889 / 107
FROM DUAL;
SELECT *
FROM departments;
2、分类
按照 =划分 : 等值连接 VS 非等值连接
自连接 VS 非自连接
内连接 VS 外连接
#内连接:查询的结果集中只包含两个表中的相关联的数据。
#左外连接:查询的结果集中除了返回两个表中的相关联的数据之外,还返回了左表中不满足关联条件的数据
#右外连接:查询的结果集中除了返回两个表中的相关联的数据之外,还返回了右表中不满足关联条件的数据
#满外连接:查询的结果集中除了返回两个表中的相关联的数据之外,还返回了左表中和右表中不满足关联条件的数据#非等值连接
SELECT *
FROM employees;
SELECT *
FROM job_grades;
SELECT employee_id,salary,grade
FROM employees e,job_grades j
WHERE e.`salary` BETWEEN j.`LOWEST_SAL` AND j.`HIGHEST_SAL`
ORDER BY grade;
#自连接
#查询员工的id,name及其管理者的id和name
SELECT emp.employee_id,emp.last_name,mgr.employee_id,mgr.last_name
FROM employees emp,employees mgr
WHERE emp.`manager_id` = mgr.`employee_id`;
3、使用
注意:凡是出现所有,考虑使用外连接,join on
使用连接在多个表中查询数据。
- 在 WHERE 子句中写入连接条件。
- 在表中有相同列时,在列名之前加上表名前缀
- 在不同表中具有相同列名的列可以用表的别名加以区分。
#正确的:
#查询员工的id,name,部门名称
#如果查询两个表中都存在的字段,则必须指明此字段所属的表。
#sql优化:如果多表查询,则明确指出列所属的表,是一个sql上的优化。
SELECT employees.employee_id,employees.last_name,departments.department_name,employees.department_id
FROM employees,departments
#多表的连接条件
WHERE employees.`department_id` = departments.`department_id`;
4、表的别名
- 使用别名可以简化查询。
- 使用表名前缀可以提高执行效率。
# 可以给表起别名,在select、where中使用表的别名
SELECT e.employee_id,e.last_name,d.department_name,e.department_id
FROM employees e,departments d
WHERE e.department_id = d.department_id
#例子:
SELECT e.last_name,e.job_id,j.job_title
FROM employees e, jobs j
WHERE e.job_id = j.job_id;
5、连接多个表
连接 n个表,至少需要 n-1个连接条件。 例如:连接三个表,至少需要两个连接条件
#例子:查询员工的id,department_name,city
#结论:如果在查询中涉及到n个表,则至少应该有 n - 1 个连接条件。
SELECT employee_id,department_name,city
FROM employees e,departments d,locations l
WHERE e.department_id = d.department_id
AND d.location_id = l.location_id;
6、内连接和外连接
注意:凡是出现所有,考虑使用外连接,join on
1)SQL99:使用ON 子句创建连接
- 自然连接中是以具有相同名字的列为连接条件的。
- 可以使用 ON 子句指定额外的连接条件。
- 这个连接条件是与其它条件分开的。
- ON 子句使语句具有更高的易读性。
#查询公司中所有员工的id,name,部门名称
SELECT employee_id,last_name,department_name
FROM employees e,departments d
WHERE e.`department_id` = d.`department_id`(+); #适合于oracle
#sql 99 语法:left/right outer join ... on
#实现内连接:
#查询员工的id,name,部门名称
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`;
#例子:查询员工的id,department_name,city
SELECT employee_id,department_name,city
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`
JOIN locations l
ON d.`location_id` = l.`location_id`;
# join ... on .... join ... on ....
2)内连接和外连接
- 内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
- 外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行 ,这种连接称为左(或右)
外连接。没有匹配的行时, 结果表中相应的列为空(NULL).
#内连接:查询的结果集中只包含两个表中的相关联的数据。
#左外连接:查询的结果集中除了返回两个表中的相关联的数据之外,还返回了左表中不满足关联条件的数据
#右外连接:查询的结果集中除了返回两个表中的相关联的数据之外,还返回了右表中不满足关联条件的数据
#满外连接:查询的结果集中除了返回两个表中的相关联的数据之外,还返回了左表中和右表中不满足关联条件的数据
#实现外连接:
#查询所有员工的id,name,部门名称:左外连接
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`;
#右外连接
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
#满外连接:mysql不支持full join.而oracle支持
SELECT employee_id,last_name,department_name
FROM employees e FULL JOIN departments d
ON e.`department_id` = d.`department_id`;
七、UNION 操作符
UNION 操作符返回两个查询的结果集的并集
UNION ALL 操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
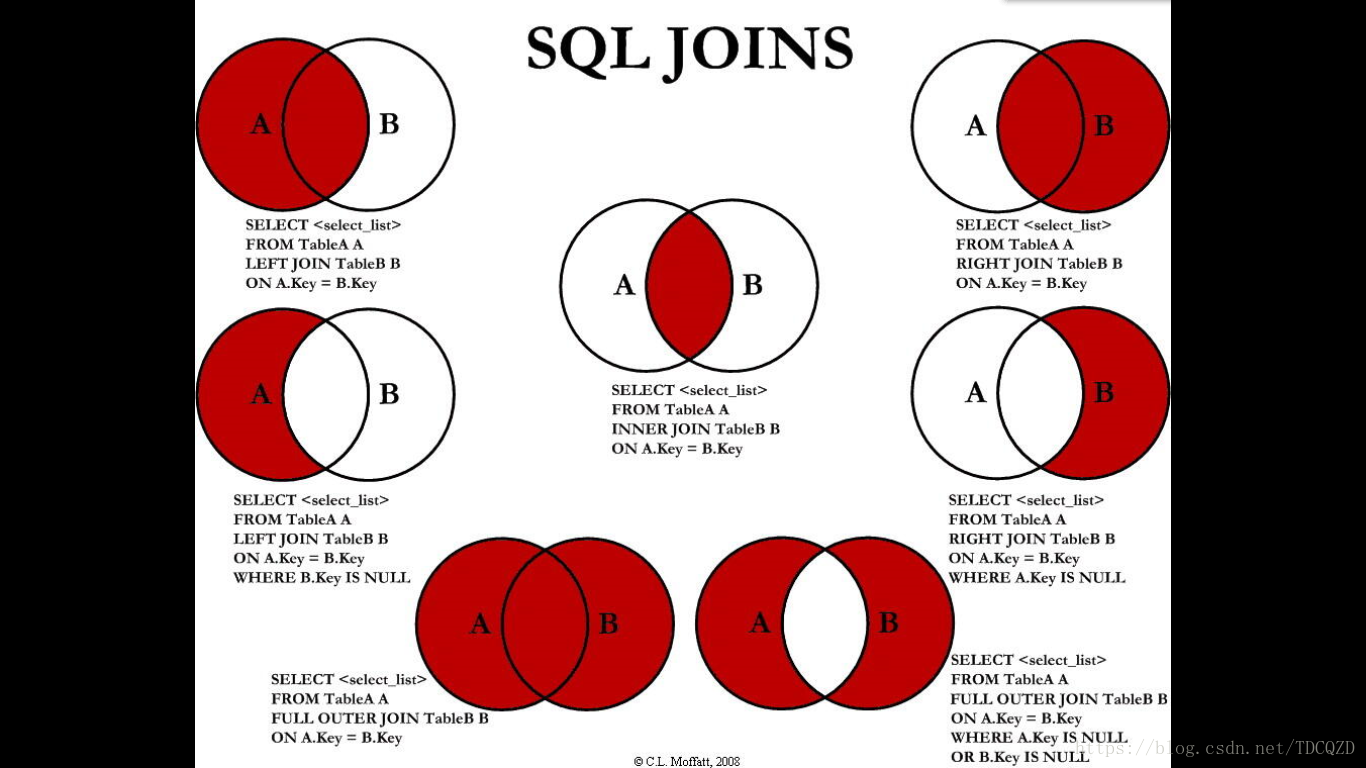
#针对于ppt中join的图表:
#实现 右边中间的图:查询没有人的部门情况
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;
# union:求并集数据
# 实现满外连接
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
UNION ALL
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
#实现左边中间的图:
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL;
#实现下边的右边的图:
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;
八、单行函数
1、单行函数:
function_name [(arg1, arg2,...)]操作数据对象
接受参数返回一个结果
只对一行进行变换
每行返回一个结果
可以嵌套
参数可以是一列或一个值
2、字符函数
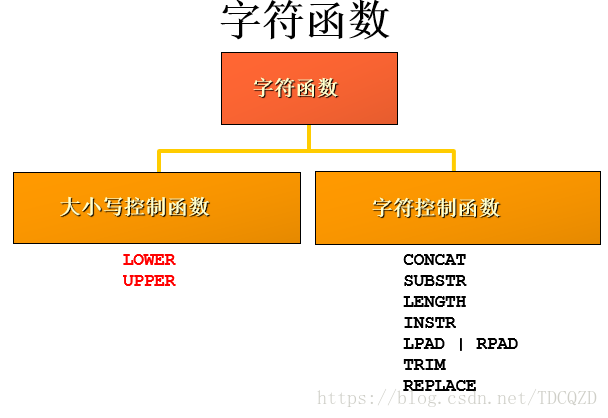
1)大小写控制函数

2)字符控制函数

#字符型函数
SELECT 'helloWorld',LOWER('helloWorld'),UPPER('helloWorld')
FROM DUAL;
SELECT *
FROM employees
WHERE LOWER(last_name) = 'king';
#xxx worked for xxx
SELECT CONCAT(emp.last_name,' worked for ',mgr.last_name) "worker details"
FROM employees emp JOIN employees mgr
ON emp.manager_id = mgr.employee_id;
SELECT INSTR('hewlloworwld','w'),INSTR('hewlloworwld','z')
FROM DUAL;
SELECT employee_id,LPAD(salary,10,' ')
FROM employees;
SELECT TRIM(' ' FROM ' hhhelhlohw orhldhh '),REPLACE('abcabc','a','m')
FROM DUAL;
3、 数字函数
ROUND: 四舍五入
ROUND(45.926, 2) 45.93
TRUNCATE: 截断
TRUNCATE(45.926) 45
MOD: 求余
MOD(1600, 300) 100
# 数值函数
# round():四舍五入
SELECT ROUND(123.556),ROUND(123.556,0),ROUND(123.456,2),ROUND(153.456,-2)
FROM DUAL;
# truncate():截断
SELECT TRUNCATE(123.956,0),TRUNCATE(123.456,2),TRUNCATE(173.456,-2)
FROM DUAL;
# mod():取模.
# 结论:运算结果与被模数的符号相同
SELECT MOD(17,5),MOD(17,-5),MOD(-17,5),MOD(-17,-5)
FROM DUAL;
4、日期函数
函数NOW() 返回:
- 日期
- 时间
# 日期函数:now(),返回日期+时间
SELECT NOW()
FROM DUAL;
5、通用函数
#通用函数:ifnull
# 结论1:凡是参与运算的列的值为null的话,参与运算的结果都为null。
# 结论2:null值不等同于0,'','null'
SELECT employee_id,last_name,salary,salary*(1 + commission_pct),commission_pct,salary*(1 + IFNULL(commission_pct,0))
FROM employees;
6、条件表达式
在 SQL 语句中使用IF-THEN-ELSE 逻辑
使用方法:
CASE 表达式
# 条件表达式: case ... when ...then... when ... then ... else ... end
练习1:查询各个部门的员工信息,
若部门号为 10, 则打印其工资的 1.1 倍,
20 号部门, 则打印其工资的 1.2 倍,
30 号部门打印其工资的 1.3 倍数,
其他部门,打印其工资的1.4倍数。
SELECT employee_id,last_name,salary,department_id,CASE department_id WHEN 10 THEN salary * 1.1
WHEN 20 THEN salary * 1.2
WHEN 30 THEN salary * 1.3
ELSE salary * 1.4 END "new sal"
FROM employees;
练习3:查询部门号为 10, 20, 30 的员工信息,
若部门号为 10, 则打印其工资的 1.1 倍,
20 号部门, 则打印其工资的 1.2 倍,
30 号部门打印其工资的 1.3 倍数
SELECT employee_id,last_name,salary,department_id,CASE department_id WHEN 10 THEN salary * 1.1
WHEN 20 THEN salary * 1.2
WHEN 30 THEN salary * 1.3
END "new sal"
FROM employees
WHERE department_id IN (10,20,30);
SELECT last_name, job_id, salary,
CASE job_id WHEN 'IT_PROG' THEN 1.10*salary
WHEN 'ST_CLERK' THEN 1.15*salary
WHEN 'SA_REP' THEN 1.20*salary
ELSE salary END "REVISED_SALARY"
FROM employees;
九、分组函数——GROUP BY
1、什么是分组函数
分组函数作用于一组数据,并对一组数据返回一个值。
2、分组函数类型
AVG()
SUM()
MAX()
MIN()
COUNT()
3、AVG(平均值)和 SUM (合计)函数:可以对数值型数据使用AVG 和 SUM 函数。
# 分组函数
# sum() / avg() : 只适用于数值型的变量
SELECT AVG(salary),SUM(salary)
FROM employees;
SELECT AVG(salary),SUM(salary)
FROM employees
WHERE department_id IN (60,70,80);
#在mysql中执行不报错,输出0.没有实际意义。
#在oracle中执行报错
SELECT SUM(last_name),AVG(last_name) #sum(hire_date),avg(hire_date)
FROM employees;
4、MIN(最小值)和 MAX(最大值)函数:可以对任意数据类型的数据使用 MIN 和 MAX 函数。
# max() / min():适合于数值型、字符型、日期型变量
SELECT MAX(salary),MIN(salary),MAX(last_name),MIN(last_name) #max(hire_date),min(hire_date)
FROM employees;
5、COUNT(计数)函数:
- COUNT(*) 返回表中记录总数,适用于任意数据类型。
- COUNT(expr) 返回expr不为空的记录总数。
# count(): 适合于数值型、字符型、日期型变量
# 计算count对应的字段中非空数据的个数
SELECT COUNT(employee_id),COUNT(last_name),COUNT(commission_pct)
FROM employees;
SELECT commission_pct
FROM employees
WHERE commission_pct IS NOT NULL;
SELECT COUNT(employee_id),COUNT(last_name),COUNT(commission_pct)
FROM employees
WHERE department_id IN (60,70,80);
SELECT COUNT(salary),COUNT(2 * salary),COUNT(1),COUNT(2),COUNT(NULL)
FROM employees;
SELECT COUNT(commission_pct),COUNT(IFNULL(commission_pct,0))
FROM employees;
SELECT COUNT(*)
FROM employees;
#结论: avg = sum / count
SELECT AVG(salary),SUM(salary) / COUNT(salary)
FROM employees;
SELECT AVG(commission_pct) , SUM(commission_pct) / COUNT(commission_pct),
SUM(commission_pct) / 107,SUM(commission_pct) / COUNT(IFNULL(commission_pct,0))
FROM employees;
6、组函数类型
SELECT [column,] group_function(column), ...
FROM table
[WHERE condition]
[GROUP BY column]
[ORDER BY column];
7、分组数据: GROUP BY 子句语法
1)可以使用GROUP BY子句将表中的数据分成若干组
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];
注意:WHERE一定放在FROM后面
Where :Mysql从左至右,Oracle从右至左
2)在SELECT 列表中所有未包含在组函数中的列都应该包含
在 GROUP BY 子句中。

3)包含在 GROUP BY 子句中的列不必包含在SELECT 列表中

4)在GROUP BY子句中包含多个列
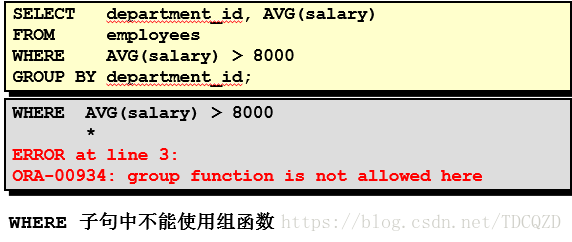
5)非法使用组函数
- 不能在 WHERE 子句中使用组函数。
- 可以在 HAVING 子句中使用组函数。
8、过滤分组
使用 HAVING 过滤分组:
1. 行已经被分组。
2. 使用了组函数。
3. 满足HAVING 子句中条件的分组将被显示。


代码示例:
#求出EMPLOYEES表中各部门的平均工资
SELECT department_id,AVG(salary)
FROM employees
GROUP BY department_id;
SELECT job_id,AVG(salary),MAX(salary)
FROM employees
GROUP BY job_id;
# 无分组条件mysql中如下的操作不报错,但是结果不正确!
# oracle中如下的操作报错。
SELECT department_id,AVG(salary)
FROM employees;
#不同部门,不同job_id的员工的平均工资
# 技巧:查询语句中有组函数和非组函数的列,则非组函数的列一定要声明在group by中。
# 表明,要按照非组函数的列进行分组。
SELECT department_id,job_id,AVG(salary)
FROM employees
GROUP BY department_id,job_id;
# 与上一个sql查询操作,解决的问题相同,结果一样
SELECT job_id,department_id,AVG(salary)
FROM employees
GROUP BY job_id,department_id;
#如下的操作是正确的。group by中的字段可以不出现在select中。
SELECT department_id,AVG(salary)
FROM employees
GROUP BY department_id,job_id;
#部门最高工资比 10000 高的部门
# where过滤条件中不能出现组函数的。需要使用having替换
SELECT department_id,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000;# mysql中要求having要声明在group by后面! oracle中没有此要求。
#在20,30,40,50这4个部门中,部门最高工资比 10000 高的部门
#写法一:
SELECT department_id,MAX(salary)
FROM employees
WHERE department_id IN (20,30,40,50) # where声明在from的后面
GROUP BY department_id
HAVING MAX(salary) > 10000;
#写法二:相较于写法一,效率较低
SELECT department_id,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000 AND department_id IN (20,30,40,50);
#结论1:如果过滤条件中没有组函数,则此过滤条件可声明在having或where中,
#但是建议此过滤条件声明在where中。因为执行效率高。
#结论2:如果过滤条件中有组函数,则必须将此过滤条件声明在having中。
#总结:
SELECT ....,....,.... (可能包含组函数)
FROM ...,...,....
WHERE 多表的连接条件
AND 非组函数的过滤条件
GROUP BY 要分组的字段
HAVING 组函数的过滤条件
ORDER BY 排序的字段 ASC/DESC,...
LIMIT ...,...
或者
SELECT ....,....,.... (可能包含组函数)
FROM ... (LEFT / RIGHT)JOIN ...
ON 多表的连接条件
JOIN ... ON ...
WHERE 非组函数的过滤条件1
AND 非组函数的过滤条件2
GROUP BY 要分组的字段
HAVING 组函数的过滤条件
ORDER BY 排序的字段 ASC/DESC,...
LIMIT ...,...