版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/bingningning/article/details/52388974
近期正在学习卷积神经网络,大致的原理在之前参考前辈们经验,转载的两个笔记中已经做了简要梳理,下边就Github中的DeepLearnToolbox中的CNN的代码进行理解和实现讲解
参考代码来源:[CNN卷积神经网络的Matlab实现](https://github.com/rasmusbergpalm/DeepLearnToolbox)
网络结构图:
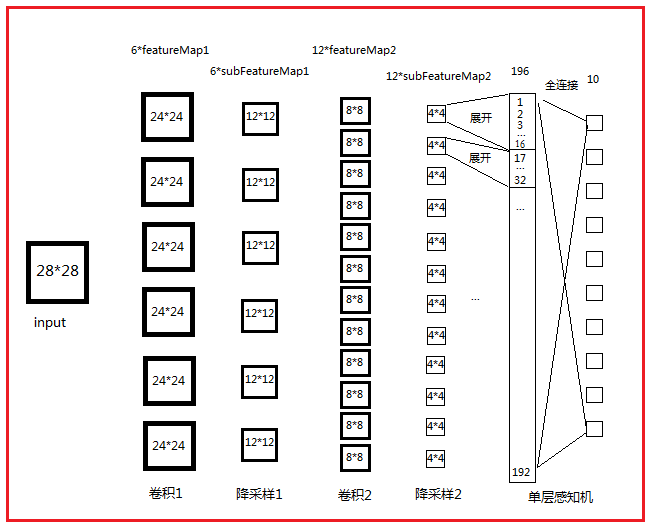
打开路径\tests\test_example_cnn.m
function test_example_CNN
clc,
clear;
addpath D:\matlab文档\DeepLearnToolbox\data\ %按照文档所在路径进行加载
addpath D:\matlab文档\DeepLearnToolbox\CNN\
addpath D:\matlab文档\DeepLearnToolbox\util\
load mnist_uint8; %加载训练、测试数据
train_x = double(reshape(train_x',28,28,60000))/255; % 训练集变成60000张28*28的图片 28*28*60000,像素点归一化到[0,1]
test_x = double(reshape(test_x',28,28,10000))/255; % 测试集 28*28*10000
train_y = double(train_y'); %10*6000
test_y = double(test_y');
%% ex1 Train a 6c-2s-12c-2s Convolutional neural network
%will run 1 epoch in about 200 second and get around 11% error.
%With 100 epochs you'll get around 1.2% error
rand('state',0) %如果指定状态,产生随机结果就相同
cnn.layers = { %%% 设置各层feature maps个数及卷积模板大小等属性
struct('type', 'i') %input layer
struct('type', 'c', 'outputmaps', 6, 'kernelsize', 5) %卷积层有6张特征图,卷积核大小为5*5
struct('type', 's', 'scale', 2) %抽样层,定义2*2的临域相连接
struct('type', 'c', 'outputmaps', 12, 'kernelsize', 5) %同上
struct('type', 's', 'scale', 2) %同上
};
opts.alpha = 1; %迭代下降的速率
opts.batchsize = 50; %每次选择50个样本进行更新
opts.numepochs = 1; %迭代次数
cnn = cnnsetup(cnn, train_x, train_y); %对各层参数进行初始化 包括权重和偏置
cnn = cnntrain(cnn, train_x, train_y, opts); %训练的过程,包括bp算法及迭代过程
[er, bad] = cnntest(cnn, test_x, test_y);
%plot mean squared error
figure; plot(cnn.rL);
assert(er<0.12, 'Too big error');
end\CNN\cnnsetup.m
function net = cnnsetup(net, x, y) %对各层参数进行初始化 包括权重和偏置
assert(~isOctave() || compare_versions(OCTAVE_VERSION, '3.8.0', '>='), ['Octave 3.8.0 or greater is required for CNNs as there is a bug in convolution in previous versions. See http://savannah.gnu.org/bugs/?39314. Your version is ' myOctaveVersion]);
inputmaps = 1; %输入图片数量
mapsize = size(squeeze(x(:, :, 1))); % 图片的大小 squeeze 要不要都行28 28,squeeze的功能是删除矩阵中的单一维
for l = 1 : numel(net.layers) %layer层数
if strcmp(net.layers{l}.type, 's')
mapsize = mapsize / net.layers{l}.scale;%% sumsampling的featuremap长宽都是上一层卷积层featuremap的不重叠平移scale大小
%分别为24/2=12;8/2=4
%%assert:断言函数
assert(all(floor(mapsize)==mapsize), ['Layer ' num2str(l) ' size must be integer. Actual: ' num2str(mapsize)]);
for j = 1 : inputmaps % 就是上一层有多少张特征图,通过初始化为1然后依层更新得到
net.layers{l}.b{j} = 0;
% 将偏置初始化0, 权重weight,这段代码subsampling层将weight设为1/4 而偏置参数设为0,故subsampling阶段无需参数
end
end
if strcmp(net.layers{l}.type, 'c')
mapsize = mapsize - net.layers{l}.kernelsize + 1; % 得到当前层feature map的大小,卷积平移,默认步长为1
fan_out = net.layers{l}.outputmaps * net.layers{l}.kernelsize ^ 2;% 隐藏层的大小,是一个(后层特征图数量)*(用来卷积的kernel的大小)
for j = 1 : net.layers{l}.outputmaps %当前层feature maps的个数
fan_in = inputmaps * net.layers{l}.kernelsize ^ 2; %对于每一个后层特征图,有多少个参数链到前层,包含权重的总数分别为1*25;6*25
for i = 1 : inputmaps % 共享权值,故kernel参数个数为inputmaps*outputmaps个数,每一个大小都是5*5
net.layers{l}.k{i}{j} = (rand(net.layers{l}.kernelsize) - 0.5) * 2 * sqrt(6 / (fan_in + fan_out));
% 初始化每个feature map对应的kernel参数 -0.5 再乘2归一化到[-1,1]
% 最终归一化到[-sqrt(6 / (fan_in + fan_out)),+sqrt(6 / (fan_in + fan_out))] why??
end
net.layers{l}.b{j} = 0; % 初始话feture map对应的偏置参数 初始化为0
end
inputmaps = net.layers{l}.outputmaps;% 修改输入feature maps的个数以便下次使用
end
end
% 'onum' is the number of labels, that's why it is calculated using size(y, 1). If you have 20 labels so the output of the network will be 20 neurons.
% onum 是标签数,也就是最后输出层神经元的个数。你要分多少个类,自然就有多少个输出神经元;
% 'fvnum' is the number of output neurons at the last layer, the layer just before the output layer.
% fvnum是最后输出层的前面一层的神经元个数,这一层的上一层是经过pooling后的层,
%包含有inputmaps个特征map。每个特征map的大小是mapsize。所以,该层的神经元个数是 inputmaps * (每个特征map的大小);
% 'ffb' is the biases of the output neurons.
% ffb 是输出层每个神经元对应的基biases
% 'ffW' is the weights between the last layer and the output neurons. Note that the last layer is fully connected to the output layer, that's why the size of the weights is (onum * fvnum)
% ffW 输出层前一层 与 输出层 连接的权值,这两层之间是全连接的
fvnum = prod(mapsize) * inputmaps;% prod函数用于求数组元素的乘积,fvnum=4*4*12=192,是全连接层的输入数量
onum = size(y, 1);%最终分类的个数 10类 ,最终输出节点的数量
% 这里是最后一层神经网络的设定
net.ffb = zeros(onum, 1);%softmat回归的偏置参数个数
net.ffW = (rand(onum, fvnum) - 0.5) * 2 * sqrt(6 / (onum + fvnum)); %% softmaxt回归的权值参数 为10*192个 全连接
end\CNN\cnnff.m
function net = cnntrain(net, x, y, opts) %%训练的过程,包括bp算法及迭代过程
m = size(x, 3); %% m为样本照片的数量,size(x)=[28*28*6000]
numbatches = m / opts.batchsize;% 循环的次数 共1200次,每次使用50个样本进行
if rem(numbatches, 1) ~= 0
error('numbatches not integer');
end
net.rL = [];%rL是最小均方误差的平滑序列,绘图要用
for i = 1 : opts.numepochs %迭代次数
disp(['epoch ' num2str(i) '/' num2str(opts.numepochs)]);
tic;
kk = randperm(m); %% 随机产生m以内的不重复的m个数
for l = 1 : numbatches %% 循环1200次,每次选取50个不重复样本进行更新
batch_x = x(:,:, kk((l - 1) * opts.batchsize + 1 : l * opts.batchsize));%50个样本的训练数据
batch_y = y(:, kk((l - 1) * opts.batchsize + 1 : l * opts.batchsize));%50个样本所对应的标签
net = cnnff(net, batch_x);%计算前向传导过程
net = cnnbp(net, batch_y);%计算误差并反向传导,计算梯度
net = cnnapplygrads(net, opts); %% 应用梯度迭代更新模型
%net.L为模型的costFunction,即最小均方误差mse
%rL是最小均方误差的平滑序列
if isempty(net.rL)%为空
net.rL(1) = net.L; %loss function的值
end
net.rL(end + 1) = 0.99 * net.rL(end) + 0.01 * net.L;
%相当于对每一个batch的误差进行累积(加权平均)
end
toc;
end
end
\CNN\cnnff.m
back propagation 计算gradient
function net = cnnff(net, x)%完成训练的前向过程,
n = numel(net.layers);
net.layers{1}.a{1} = x; % a是输入map,是一个【28,28,50】的矩阵
inputmaps = 1;
for l = 2 : n %针对每一个卷积层
if strcmp(net.layers{l}.type, 'c')
for j = 1 : net.layers{l}.outputmaps % 针对该层的每一个feture map
% create temp output map
z = zeros(size(net.layers{l - 1}.a{1}) - [net.layers{l}.kernelsize - 1 net.layers{l}.kernelsize - 1 0]);
%z=zeros([28,28,50]-[5-1,5-1,0])=([24,24,50])
% 该层feture map的大小,最后一位是样本图片个数 初始化为0
for i = 1 : inputmaps %针对每一个输入feature map
z = z + convn(net.layers{l - 1}.a{i}, net.layers{l}.k{i}{j}, 'valid');
%做卷积操作 k{i}{j} 是5*5的double类型,其中a{i}是输入图片的feature map 大小为28*28*50 50为图像数量
%卷积操作这里的k已经旋转了180度,z保存的就是该层中所有的特征
end
% 通过非线性加偏值
net.layers{l}.a{j} = sigm(z + net.layers{l}.b{j});%%获取sigmoid function的值
end
inputmaps = net.layers{l}.outputmaps; %% 设置新的输入feature maps的个数
elseif strcmp(net.layers{l}.type, 's')% 下采样采用的方法是,2*2相加乘以权值1/4, 没有取偏置和取sigmoid
% downsample
for j = 1 : inputmaps
%这里做的是mean-pooling
z = convn(net.layers{l - 1}.a{j}, ones(net.layers{l}.scale) / (net.layers{l}.scale ^ 2), 'valid');
%先卷积后各行各列取结果
net.layers{l}.a{j} = z(1 : net.layers{l}.scale : end, 1 : net.layers{l}.scale : end, :);
%得到的结果是上一层卷积层行列的一半 a=z
end
end
end
% 收纳到一个vector里面,方便后面用~~
% concatenate all end layer feature maps into vector
net.fv = []; %%用来保存最后一个隐藏层所对应的特征 将feature maps变成全连接的形式
%%net.fv: 最后一层隐藏层的特征矩阵,采用的是全连接方式
for j = 1 : numel(net.layers{n}.a) % fv每次拼合入subFeaturemap2[j],[包含50个样本]
sa = size(net.layers{n}.a{j}); % 每一个featureMap的大小为a=sa=4*4*50,得到sfm2的一个输入图的大小
%rashape(A,m,n)
%把矩阵A改变形状,变为m行n列(元素个数不变,原矩阵按列排成一队,再按行排成若干队)
%把net.layers{numLayers}.a[j](一个sfm2)排列成为[4*4行,1列]的一个向量
%把所有的sfm2拼合成为一个列向量fv
net.fv = [net.fv; reshape(net.layers{n}.a{j}, sa(1) * sa(2), sa(3))];
% 最后得到192*50的矩阵,每一列对应一个样本图像的特征
end
%feedforward into output perceptrons
%net.ffW是【10,192】的权重矩阵
%net.ffW*net.fv是一个【10,50】的矩阵
%repat(net.ffb,1,size(net.fv,2))把bias复制成50份排开
net.o = sigm(net.ffW * net.fv + repmat(net.ffb, 1, size(net.fv, 2)));
%结果为10*50的矩阵,每一列表示一个样本图像的标签结果 取了sigmoid function表明是k个二分类器,各类之间不互斥,当然也可以换成softmax回归
end
\CNN\cnnbp.m
function net = cnnbp(net, y)%计算并传递神经网络的error,并计算梯度(权重的修改量)
n = numel(net.layers); %layers层个数
% error
net.e = net.o - y; % 10*50 每一列表示一个样本图像
% loss function,均方误差
net.L = 1/2* sum(net.e(:) .^ 2) / size(net.e, 2);%没有加入参数构成贝叶斯学派的观点
%% backprop deltas
%计算尾部单层感知机的误差
net.od = net.e .* (net.o .* (1 - net.o)); % 输出层的误差 sigmoid误差
%fvd,feature vector delta,特征向量误差,上一层收集下层误差,size=[192*50]
net.fvd = (net.ffW' * net.od);
%如果MLP的前一层(特征抽取最后一层)是卷基层,卷基层的输出经过sigmoid函数处理,error需要求导
%在数字识别这个网络中不需要用到
if strcmp(net.layers{n}.type, 'c') % only conv layers has sigm function
%对于卷基层,它的特征向量误差 再求导
net.fvd = net.fvd .* (net.fv .* (1 - net.fv)); %% 如果最后一个隐藏层是卷积层,直接用该公式就能得到误差
end
% reshape feature vector deltas into output map style
%把单层感知机的输入层featureVector 的误差矩阵,恢复为subFeatureMap2的4*4二位矩阵形式
sa = size(net.layers{n}.a{1}); %size(a{1})=[4*4*50],一共有a{1}~a{12}}
fvnum = sa(1) * sa(2);%fvnum 一个图所含有的特征向量数量,4*4
for j = 1 : numel(net.layers{n}.a) %subFeatureMap的数量,1:12
%net最后一层的delta,由特征向量delta,依次取一个featureMap大小,然后组合成为一个featureMap的形状
%在fvd里面保存的是所有样本的特征向量(在cnnff.m函数中用特征map拉成的),这里需要重新变换回来特征map的形式
net.layers{n}.d{j} = reshape(net.fvd(((j - 1) * fvnum + 1) : j * fvnum, :), sa(1), sa(2), sa(3));
%size(net.layers{numLayers}.d{j})=【4*4*50】
%size(net.fvd)=[192*50]
end
for l = (n - 1) : -1 : 1 %实际是到2终止了,1是输入层,没有误差要求
%l层是卷积层,误差从下层(降采样层传来),采用从后往前均摊的方式传播误差,上层误差内摊2倍,再除以4
if strcmp(net.layers{l}.type, 'c') %卷积层的计算方式
for j = 1 : numel(net.layers{l}.a) %第n-1层具有的feature maps的个数,进行遍历 每个d{j}是8*8*50的形式, 由于下一层为下采样层,故后一层d{j}扩展为8*8的(每个点复制成2*2的),按照bp求误差公式就可以得出,这里权重就为1/4,
%net.layers{l}.a{j}.*(1-net.layers{l}.a{j})为sigmoid的倒数
%(expand(net.layers{l+1}.d{j},[net.layers{j+1}.scale net.layers{l+1}.scale 1]))
%expand多项式展开相乘
%net.layers{l+1}.scale^2
net.layers{l}.d{j} = net.layers{l}.a{j} .* (1 - net.layers{l}.a{j}) .* (expand(net.layers{l + 1}.d{j}, [net.layers{l + 1}.scale net.layers{l + 1}.scale 1]) / net.layers{l + 1}.scale ^ 2);%克罗内克积进行扩充,求采样曾的卷基层的残差,d表示残差,a表示输出值
end
%l层是降采样层,误差从下层(卷积层传来),采用卷积的方式得到
elseif strcmp(net.layers{l}.type, 's')
for i = 1 : numel(net.layers{l}.a) %l层输出层的数量
z = zeros(size(net.layers{l}.a{1})); %z得到一个feature map的大小的零矩阵
for j = 1 : numel(net.layers{l + 1}.a) %从l+1层收集错误
%net.layers{l+1}.d{j}下一层(卷积层)的灵敏度
%net.layers{l+1}.k{i}{j},下一层(卷积层)的卷积核
z = z + convn(net.layers{l + 1}.d{j}, rot180(net.layers{l + 1}.k{i}{j}), 'full');
end
net.layers{l}.d{i} = z; %% 因为是下采样层,所以a=z,就f(z)=z,导数就等于1,所以误差就是所连接结点权值与后一层误差和
end
end
end
%% calc gradients
%计算特征抽取层(卷积+降采样)的梯度
for l = 2 : n
if strcmp(net.layers{l}.type, 'c')%卷积层
for j = 1 : numel(net.layers{l}.a)%l层的featureMap的数量
for i = 1 : numel(net.layers{l - 1}.a)
%卷积核的修改量=输入图像*输出图像的delta
net.layers{l}.dk{i}{j} = convn(flipall(net.layers{l - 1}.a{i}), net.layers{l}.d{j}, 'valid') / size(net.layers{l}.d{j}, 3);% 可以看论文中的推导!与论文中先将k rot180,然后再rot整体效果是一样的。
end
%net.layers{l}.d{j}(:)是一个24*24*50的矩阵,db仅除以50
net.layers{l}.db{j} = sum(net.layers{l}.d{j}(:)) / size(net.layers{l}.d{j}, 3); %% 对偏置参数b的导数
end
end
end
%计算尾部单层感知机的梯度
%sizeof(net.od)=[10,50]
%修改量,求和除以50(batch大小)
net.dffW = net.od * (net.fv)' / size(net.od, 2); %softmax回归中参数所对应的导数
net.dffb = mean(net.od, 2);%% 第二维取均值
function X = rot180(X)
X = flipdim(flipdim(X, 1), 2);% flipdim(X, 1) 行互换 flipdim(X, 2) 列互换
end
end
在这里插入一张图片便于大家理解:
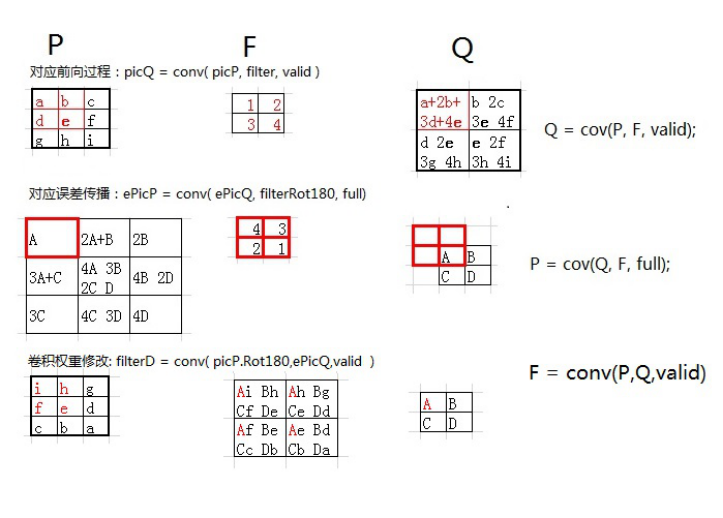
\CNN\cnnapplygrads.m
该函数完成权重修改,更新模型的功能
1更新特征抽取层的权重 weight+bias
2 更新末尾单层感知机的权重 weight+bias
function net = cnnapplygrads(net, opts)%% 把计算出来的梯度加到原始模型上去
%特征抽取层(卷积降采样)的权重更新
for l = 2 : numel(net.layers)%从第二层开始
if strcmp(net.layers{l}.type, 'c')%对于每个卷积层
for j = 1 : numel(net.layers{l}.a)%美剧该层的每个输出
for ii = 1 : numel(net.layers{l - 1}.a)
net.layers{l}.k{ii}{j} = net.layers{l}.k{ii}{j} - opts.alpha * net.layers{l}.dk{ii}{j};
% 梯度下降求更新后的参数
end
%修改bias
net.layers{l}.b{j} = net.layers{l}.b{j} - opts.alpha * net.layers{l}.db{j};
end
end
end
%单层感知机的权重更新
net.ffW = net.ffW - opts.alpha * net.dffW;%更新权重
net.ffb = net.ffb - opts.alpha * net.dffb;%更新偏置
end
\CNN\cnntest.m
验证测试样本的准确率
function [er, bad] = cnntest(net, x, y)%测试当前模型的准确率
% feedforward
net = cnnff(net, x);
[~, h] = max(net.o);
[~, a] = max(y);
bad = find(h ~= a);%计算预测错误的样本数量
er = numel(bad) / size(y, 2);%计算错误率
end