目录
Structured Streaming是Spark新提出的一种实时流的框架,以前是Spark Streaming。那么这两者有什么区别呢,为什么有了Spark Streaming,还要提出Structured Streaming呢?且听我娓娓道来~
一、为何要有StructuredStreaming
Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。
支持从多种数据源获取数据,包括Kafk、Flume、以及TCP socket等,从数据源获取数据之后,可以使用诸如map、reduce和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统和数据库等
Spark Streaming处理的数据流图:

Spark Streaming的处理机制如下图:

Spark Streaming接收流数据,并根据一定的时间间隔拆分成一批批batch数据,用抽象接口DStream表示(DStream可以看成是一组RDD序列,每个batch对应一个RDD),然后通过Spark Engine处理这些batch数据,最终得到处理后的一批批结果数据。
Structured Streaming是Spark2.0版本提出的新的实时流框架(2.0和2.1是实验版本,从Spark2.2开始为稳定版本),相比于Spark Streaming,优点如下:
- 同样能支持多种数据源的输入和输出,参考如上的数据流图
- 以结构化的方式操作流式数据,能够像使用Spark SQL处理离线的批处理一样,处理流数据,代码更简洁,写法更简单
- 基于Event-Time,相比于Spark Streaming的Processing-Time更精确,更符合业务场景
- 解决了Spark Streaming存在的代码升级,DAG图变化引起的任务失败,无法断点续传的问题(Spark Streaming的硬伤!!!)
二、StructuredStreaming的特性
1、结构化流式处理
a、如下图。Structured Streaming将实时流抽象成一张无边界的表,输入的每一条数据当成输入表的一个新行,同时将流式计算的结果映射为另外一张表,完全以结构化的方式去操作流式数据。
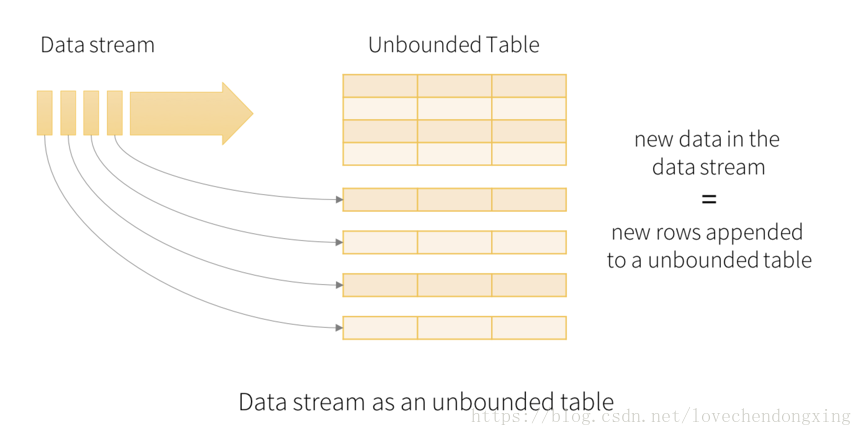
b、输入的流数据是以batch为单位被处理,每个batch会触发一次流式计算,计算结果被更新到Result Table。
如下图,设定batch长度为1s,每一秒从输入源读取数据到Input Table,然后触发Query计算,将结果写入Result Table.
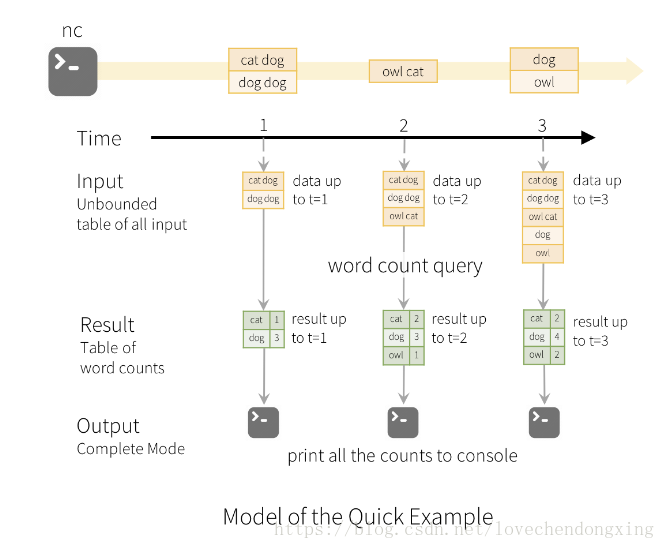
c、最后,Result Table的结果写出到外部存储介质(如Kafka)。
一共有三种Output模式:
-
Append模式:只有自上次触发后在Result Table表中附加的新行将被写入外部存储器。重点模式,一般使用它。
-
Complete模式: 将整个更新表写入到外部存储。每次batch触发计算,整张Result Table的结果都会被写出到外部存储介质。
-
Update模式:只有自上次触发后在Result Table表中更新的行将被写入外部存储器。注意,这与完全模式不同,因为此模式不输出未更改的行。
2、基于Event-Time聚合&延迟数据处理
StructedStreaming相比于SparkStreaming的另一个优点是基于Event time(事件时间)聚合
a、基于Event time聚合,更准确
首先,介绍下两种时间的概念:
- Event time 事件时间: 就是数据真正发生的时间,比如用户浏览了一个页面可能会产生一条用户的该时间点的浏览日志。
- Process time 处理时间: 则是这条日志数据真正到达计算框架中被处理的时间点,简单的说,就是你的Spark程序是什么时候读到这条日志的。
事件时间是嵌入在数据本身中的时间。对于许多应用程序,用户可能希望在此事件时间操作。例如,如果要获取IoT设备每分钟生成的事件数,则可能需要使用生成数据的时间(即数据中的事件时间),而不是Spark接收他们的时间。事件时间在此模型中非常自然地表示 - 来自设备的每个事件都是表中的一行,事件时间是该行中的一个列值。这允许基于窗口的聚合(例如每分钟的事件数)仅仅是时间列上的特殊类型的分组和聚合 - 每个时间窗口是一个组,并且每一行可以属于多个窗口/组。因此,可以在静态数据集(例如,来自收集的设备事件日志)以及数据流上一致地定义这种基于事件时间窗的聚合查询,操作起来更方便。
b、延迟数据处理Watermark
Structured Streaming基于Event time能自然地处理延迟到达的数据,保留或者丢弃。
由于Spark正在更新Result Table,因此当存在延迟数据时,它可以完全控制更新旧聚合,以及清除旧聚合以限制中间状态数据的大小。
使用Watermark,允许用户指定数据的延期阈值,并允许引擎相应地清除旧的状态。
基于Event-Time聚合&延迟数据处理的详细实例参考 《StructuredStreaming + Kafka程序怎么写》
3、容错性
a、容错语义
流式数据处理系统的可靠性语义通常是通过系统可以处理每个记录的次数来定义的。系统可以在所有可能的操作情形下提供三种类型的保证(无论出现何种故障):
- At most once:每个记录将被处理一次或不处理。
- At least once: 每个记录将被处理一次或多次。 这比“最多一次”更强,因为它确保不会丢失任何数据。但可能有重复处理。
-
Exactly once:每个记录将被精确处理一次 - 不会丢失数据,并且不会多次处理数据。 这显然是三者中最强的保证。
Structured Streaming能保证At least once的语义,目标是Exactly once。
b、容错机制
在故障或故意关闭的情况下,用户可以恢复先前进度和状态,并继续在其停止的地方,简称断点续传。这是通过使用检查点checkpoint和预写日志write ahead logs来完成的。
用户可以指定checkpoint的位置,Spark将保存所有进度信息(如每个触发器中处理的offset偏移范围)和正在运行的聚合到checkpoint中。任务重启后,使用这些信息继续执行。
注:checkpoint的目录地址必须是HDFS兼容文件系统中的路径。