基于Ubuntu的Hadoop集群安装与配置
实验的主要内容有如下几点:
1、Jdk安装:Hadoop是用Java编写的程序,Hadoop的编译及MapReduce的运行都需要JDK,因此在安装Hadoop之前,必须安装JDK1.6或更高版本。
2、SSH免密登录安装设置:Hadoop需要通过ssh(安全外壳协议)远程无密码登录,来启动Slave列表中各台机器的守护进程,因此ssh也是必须安装的。
3、Hadoop完全分布式集群的安装配置和启动验证。
4、为方便阐述,本实验只搭建一个有三台主机的小集群。
5、三台机器的具体分工命名如下:
实验环境构建
运行环境:
处理器:Intel(R) Core(TM) i7-4710MQ CPU @ 2.50GHz 3.50GHz 1155PGA 32nm L132KB L232KB L36144KB
已安装内存(RAM): 8.00GB LPDDR3L SDRAM 1600MHz
TOSHIBA SSD 0128G 4096KB HGST 1.0TB 7200rpm SATA3
Windows版本: Windows 10专业版
MMX SSE SSE2 SSE3 SSSE3 EM64T AVX SSE4.1 SSE4.2 BMI vT-x AES FMA3 AVX2
nVIDIA GeForce GTX850M 2GB GDDR3
VMware Workstation 12 Pro的安装
准备条件
安装包:vmwareworkstationrj12.0.0.64202.1442972430.exe
官网下载链接
密钥生成器:VM12密钥生成器
VM12密钥生成器下载链接
具体安装过程请自行百度,这里就不再赘述
基于Ubuntu14.04.5的Hadoop集群安装与配置
说明:
1、Hadoop部署前提仅是完成修改机器名、添加域名映射、关闭防火墙和安装JDK这四个操作,其他的都不需要。对于ssh实际上是完全不相关的操作或设置。
2、SSH实际的作用只是给sbin/start-yarn.sh等几个start-x.sh与stop-x.sh脚本使用,Hadoop本身是Java写成的,而Java代码本身并不依赖与ssh,也完全不应该依赖于ssh,只是运维时为了方便启动或关闭整个集群,才需打通ssh,所以为了以后维护的方便,ssh是有必要装的。
3、在虚拟机里面安装Ubuntu14.04.5的过程很简单这里就不一一介绍了!下面将直接从安装好的Ubuntu14.04.5里边开始安装JDK:
4、Jdk安装:Hadoop是用Java编写的程序,Hadoop的编译及MapReduce的运行都需要 JDK,因此在安装Hadoop之前,必须安装JDK1.6或更高版本。
5、SSH免密登录安装设置:Hadoop需要通过ssh(安全外壳协议)远程无密码登录,来启动Slaver列表中各台机器的守护进程,因此ssh也是必须安装的。
6、Hadoop完全分布式集群的安装配置和启动验证。
安装与配置JDK
开启root用户:
# sudo passwd root
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully使用apt-get install vim 命令安装vim;
将下载好的jdk-8u77-linux-x64.tar.gz解压开放到自己定的一个文件夹下面笔者这里将它放在了/opt/java/目录下,下一步配置JDK的环境变量, 使用vim /etc/environment ,添加/opt/java/jdk1.8.0_77/bin:
root@ubuntu:~# ls /opt/java/jdk1.8.0_77/
bin include lib README.html THIRDPARTYLICENSEREADME-JAVAFX.txt
COPYRIGHT javafx-src.zip LICENSE release THIRDPARTYLICENSEREADME.txt
db jre man src.zip在/etc/profile文件末尾添加java用户环境变量如下
export JAVA_HOME=/opt/java/jdk1.8.0_77
export JRE_HOME=/opt/java/jdk1.8.0_77/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH在/etc/environment中添加环境变量,如下所示
PATH="/opt/java/jdk1.8.0_77/bin:/opt/java/jdk1.8.0_77/sbin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games"输入source /etc/environment和source /etc/profile使环境变量生效,重启Ubuntu系统!
安装SSH免密登录
由于内容较多,请参考笔者在百度文库上传的文档“ssh免密登录”,下边是访问链接:
ssh免密登录配置教程
配置完ssh记得重启集群。
进行Hadoop集群完全分布式的安装配置
在安装和配置好JDK和SSH的Ubuntu14.04.5系统中进行Hadoop的配置:从官网上下载最新的Hadoop安装包(见参考文献),解压到/root目录下需要配置以下文件中某些文件,我们只需配置一份完整的Hadoop,直接将配置好的复制到另外两台机器即可!
安装Hadoop的重要配置文件有七个,分别是:
(1)hadoop-env.sh;(2)yarn-env.sh;(3)slaves;(4)core-site.xml;(5)hdfs-site.xml;(6)mapred-site.xml;(7)yarn-site.xml
以上文件都在hadoop-2.6.5/etc/hadoop目录下
(1)配置文件1:hadoop-env.sh 修改如下:
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/opt/java/jdk1.8.0_77注意:JAVA_HOME的值是上面安装JDK的路径,要根据安装的路径而定。
(2)配置文件2:yarn-env.sh 修改JAVA_HOME的值和Hadoop-env.sh的配置文件一样
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/opt/java/jdk1.8.0_77
(3)配置文件3:slaves,这个文件中保存的是所有的数据节点
slaver1
slaver2
(4)配置文件4:core-site.xml 添加内容如下:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdfs_all/tmp</value>
</property>
</configuration>
(5)配置文件5:hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
(6)配置文件6:mapred-site.xml 修改如下:
(默认情况下,hadoop/etc/hadoop/文件夹下有mapred.xml.template文件,我们要复制该文件,并命名为mapred-site.xml,该文件用于指定MapReduce使用的框架)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>(7)配置文件7:yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.addreess</name>
<value>master:8088</value>
</property>
</configuration>
至此Hadoop配置文件已全部配置完成。
接着把配置好的Hadoop通过ssh复制到slaver1和slaver2中。例如:
scp –r /root/Hadoop-2.6.5 slaver1:/root为方便用户和系统管理使用hadoop、hdfs相关命令,需要在/etc/environment配置系统环境变量,使用命令:vim /etc/environment。配置内容为hadoop目录下的bin、sbin路径,具体修改内容如下
PATH="/opt/java/jdk1.8.0_77/bin:/root/hadoop-2.6.5/bin:/root/hadoop-2.6.5/sbin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games"添加完后执行生效命令:source /etc/environment。下面要做的就是启动验证,建议在验证前,把以上三台机器重启,使其相关配置生效。
添加完后执行生效命令:source /etc/environment
下面要做的就是启动验证,建议在验证前,把以上三台机器重启,使其相关配置生效。
验证是否配置成功
(1) 测试是否安装成功
首先,在主节点master上格式化主节点命名空间:
这里写root@master:~# hadoop namenode -format代码片在master控制节点上启动hdfs:root@master:~# start-all.sh
应该看到如下结果:
root@master:~# start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /root/hadoop-2.6.5/logs/hadoop-root-namenode-master.out
slaver1: starting datanode, logging to /root/hadoop-2.6.5/logs/hadoop-root-datanode-slaver1.out
slaver2: starting datanode, logging to /root/hadoop-2.6.5/logs/hadoop-root-datanode-slaver2.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is 2f:a3:68:a8:fa:92:3e:4e:d9:72:61:4a:2f:30:ec:70.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /root/hadoop-2.6.5/logs/hadoop-root-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /root/hadoop-2.6.5/logs/yarn-root-resourcemanager-master.out
slaver1: starting nodemanager, logging to /root/hadoop-2.6.5/logs/yarn-root-nodemanager-slaver1.out
slaver2: starting nodemanager, logging to /root/hadoop-2.6.5/logs/yarn-root-nodemanager-slaver2.out
使用Jps命令master有如下进程,说明ok
root@master:~# jps
2099 Jps
1845 ResourceManager
1487 NameNode
1711 SecondaryNameNode
使用jps命令slaver1、slaver2有如下进程,说明ok
root@slaver1:~# jps
1360 DataNode
1508 NodeManager
1607 Jps
root@slaver2:~# jps
1364 DataNode
1512 NodeManager
1611 Jps
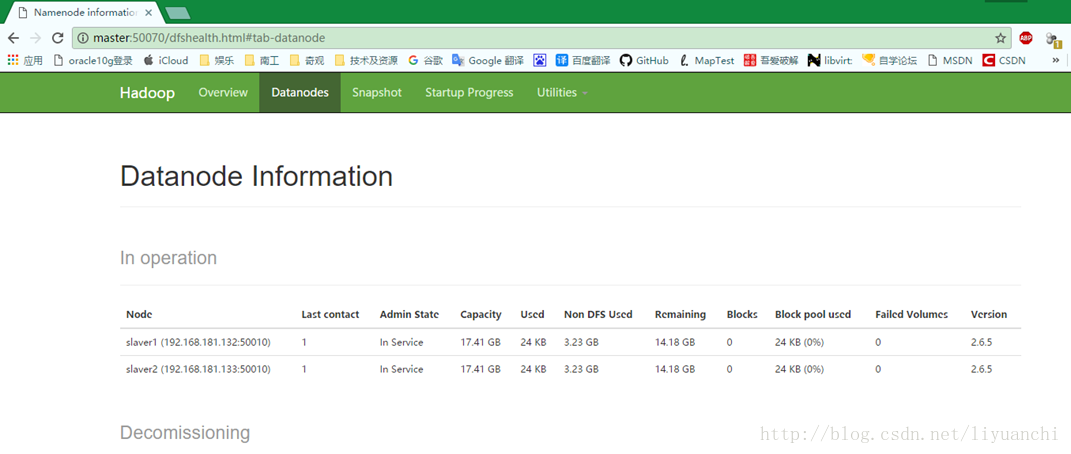
查看当前集群状态:
root@master:~# hadoop dfsadmin -report
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
Configured Capacity: 37380292608 (34.81 GB)
Present Capacity: 30453653504 (28.36 GB)
DFS Remaining: 30453604352 (28.36 GB)
DFS Used: 49152 (48 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Live datanodes (2):
Name: 192.168.181.132:50010 (slaver1)
Hostname: slaver1
Decommission Status : Normal
Configured Capacity: 18690146304 (17.41 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 3463319552 (3.23 GB)
DFS Remaining: 15226802176 (14.18 GB)
DFS Used%: 0.00%
DFS Remaining%: 81.47%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Tue Jun 06 13:37:45 CST 2017
Name: 192.168.181.133:50010 (slaver2)
Hostname: slaver2
Decommission Status : Normal
Configured Capacity: 18690146304 (17.41 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 3463319552 (3.23 GB)
DFS Remaining: 15226802176 (14.18 GB)
DFS Used%: 0.00%
DFS Remaining%: 81.47%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Tue Jun 06 13:37:45 CST 2017
查看分布式文件系统:http://master:50070(如果无法访问就把master换成master的IP,例如:192.168.181.131:5007)