我们最常用的数据结构就是树,最基础的数据结构是数组,那么树在数组的基础上解决了什么问题?为什么用树而不用数组?下面我们来详细的剖析一下:
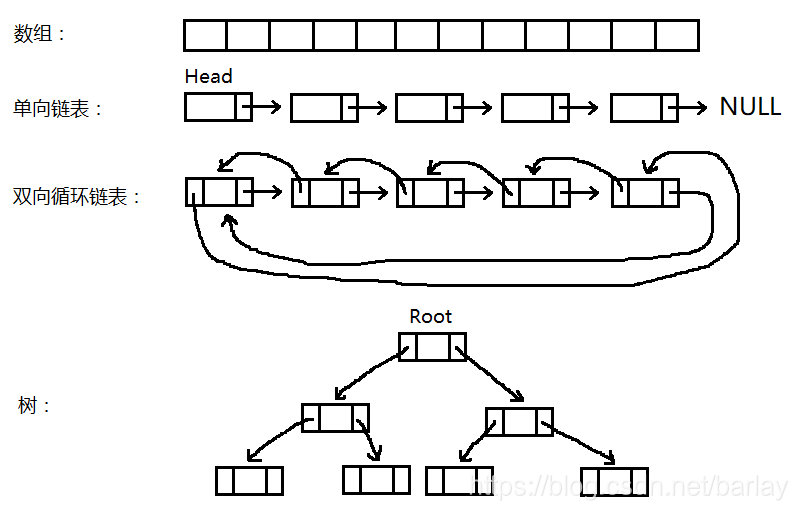
上面的图是数组、链表和树的示意图,可以看到,数组中的元素没有指针,单向链表有一个指针,双向链表有两个指针,它们都是表示的顺序关系,也就是说,数组的下一个元素肯定挨着上一个元素,单向链表指针指向的肯定是下一个元素,双向链表的右指针指向的是下一个元素,左指针指向的是上一个元素。它们之间除了顺序关系之外就没有其它的关系了。
下面我们在双向链表的基础上引入大小关系,也就是树的元素的左指针指向的树中的所有元素都比当前元素的值要小,树的元素的右指针指向的树中的所有元素都比当前元素的值要大,这样,这棵树就是一颗二叉搜索树,如果左右子树的高度相差不超过1,那么这棵树就叫做平衡二叉树,也叫AVL树。
这样,树其实是把数组和链表的优点整合起来了。对数组的操作:排序和二叉搜索对于AVL树来说是天生支持的,可以说AVL树就是为这两种操作而生的。
可以参考一下博客:
数据结构:链表(linked-list)
1分钟了解MyISAM与InnoDB的索引差异
【经典数据结构】B树与B+树
PS:很多人理解的数组就是数据的容器,但是如果但从容器的角度上来理解数组的话是有一定的局限性的。容器是用来存数据的,但是针对容器的操作不只是存数据,他还包括数据的增删改查,其中增和查是重中之重,因为我们新增的话得要保证查询的高效性,而查询到对应的数据的话才能修改和删除,所以容器应该首先满足查询的高效性。而HashMap这种数据结构是查询效率最高的,因为的它的查询时间复杂度是O(1),没有比它的查询效率更高的数据结构了。这也就是为什么面试经常问到HashMap的底层原理,因为它的使用频率最高,而它使用频率高的原因是查询效率最高。
可以看到,数据结构其实是为算法实现的,是为了满足某种算法的高效性而实现的。数据结构和算法不是独立存在的,而是相互依存的。没有数据结构,谈不上算法,没有算法,就不会出现对应的数据结构。可以说是肉体和灵魂的关系。
数组、链表和树的演进
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/barlay/article/details/83507497
猜你喜欢
转载自blog.csdn.net/barlay/article/details/83507497
今日推荐
周排行