简评: hacker news 上刷的一篇文章,可以使用类似操作数据库的方式访问网络上的资源,可以大大简化爬虫的代码。
Mixnode 将网络变成了一个巨大的数据库!换句话说,Mixnode 允许您将 Web 上的所有网页,图像,视频,PDF文件和其他资源视为数据库表中的行,相当于一个包含数万亿行的巨型数据库表,您可以使用标准结构化查询语言(SQL)进行查询。因此,您可以使用熟悉的语言编写简单查询,而不是运行 Web 爬虫/抓取工具,来实时检索网上各种有趣的信息。
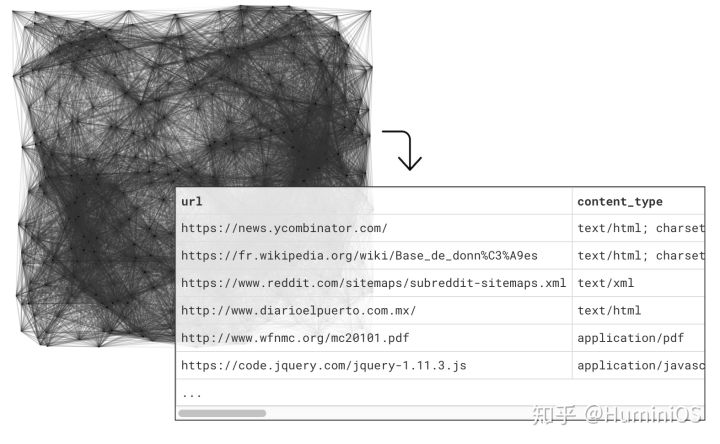
举个例子:
我么可以使用下面的语句来直接查询 url 的资源
select
url,
string_between(content, '<title>', '</title>') as title
from
resources
where
content_type like 'text/html%'
可以直接得到如下的结果:
url title
https://stackoverflow.com/questions/8318911/why-does-html-think-chucknorris-is-a-color [Why does HTML think “chucknorris” is a color? - Stack Overflow]
https://en.wikipedia.org/wiki/List_of_animals_with_fraudulent_diplomas [List of animals with fraudulent diplomas - Wikipedia]
https://www.amazon.co.jp/dp/B06XXQD54H/ [Amazon | アクータメンツ フィンガーリス 指人形 フィンガーパペット 指人形 | おもちゃ雑貨 | おもちゃ]
https://www.reddit.com/r/funny/comments/5yhipb/its_a_bit_breezy_out_there_today/ [It's a bit breezy out there today : funny]
https://imgur.com/gallery/cJO834B [Just cause you pelican doesn't mean you pelishould - Album on Imgur]
原文: Turn the web into a database: An alternative to web crawling/scraping - Mixnode News Blog