目标
针对667条宠物商品的搜索关键字进行聚类,将相似度高的条目聚为一类。在用户搜索某一商品时,电商平台能据此为用户展示类似的商品,从而提高用户的购物体验。
思路
首先明确这是一个聚类问题,而不是分类。因为商品类目本身是没有标签的,用机器学习的话来说,这是一个无监督学习的问题。接着,分析大致做法:
1. 数据导入
2. 处理数据(转化为语料库,再进行清洗过程)
3. 创建文档词条矩阵dtm,是一个稀疏矩阵
4. 对稀疏的矩阵进行降维,并转为标准矩阵格式
5. 聚类分析
- kmeans聚类
- 层次聚类
6. 检验聚类结果
过程
1.数据导入
setwd("F:/研究生/课程/R")
Raw <- read.csv("Raw.csv", header = TRUE)
Raw <- Raw[,1]
Raw <- as.matrix(Raw)
head(Raw)
查看前6行的商品词条
[1] "CAT TREE POST SCRATCHER FURNITURE PLAY HOUSE PET BED KITTEN TOY BEIGE"
[2] "DELUXE CAT TREE 36INCH CONDO FURNITURE SCRATCHING POST PET HOUSE PLAY TOY"
[3] "SMALL WARMING CAT DOG COVERED BED HOOD MICROFLEECE LINING FOAM FILLED"
[4] "PET HEATING PAD RADIENT BED WARMER CAT DOG USA SELLER FREE SHIPPING"
[5] "OUTDOOR HEATED PAD KITTY PAD"
[6] "SUNNY SEAT WINDOW CAT BED"
2. 处理数据
调用tm包——文本挖掘常用的R包
library(tm)
corp <- Corpus(DataframeSource(Raw))
writeLines(as.character(corp[[2]]))
lapply(corp, as.character)
可以查看某个文档以及每个文档的内容:
第2个文档包含的词条内容是:
DELUXE CAT TREE 36INCH CONDO FURNITURE SCRATCHING POST PET HOUSE PLAY TOY
以及查看全部文档的词条内容:
$`666`
[1] "HURTTA FLEECE OVERALL"
$`667`
[1] "DOG GROOMING BANDANAS S M L PET SCARF TIE"
下面进行格式转化,去噪:
corp1 <- tm_map(corp, content_transformer(tolower))#全部转小写
corp2 <- tm_map(corp1, removeWords, stopwords("english"))#删去介词冠词之类的停止词
corp3 <- tm_map(corp2, stripWhitespace)#删去空格
stemDocumentfix <- function(x){
PlainTextDocument(paste(stemDocument(unlist(strsplit(as.character(x), " "))),collapse=' '))
}
corp4 <- tm_map(corp3, stemDocumentfix)#提取词干
dataframe<-data.frame(text=unlist(sapply(corp4, `[`, "content")),stringsAsFactors=F)
head(dataframe)
corp5 <- Corpus(DataframeSource(dataframe))
可以看到此时的文本数据经过转化,与之前的数据有明显区别。
1 cat tree post scratcher furnitur play hous pet bed kitten toy beig
2 delux cat tree 36inch condo furnitur scratch post pet hous play toy
3 small warm cat dog cover bed hood microfleec line foam fill
4 pet heat pad radient bed warmer cat dog usa seller free ship
5 outdoor heat pad kitti pad
6 sunni seat window cat bed
3. 创建文档-词条矩阵dtm
将语料库的信息转化为矩阵,dtm表示行是文档,列是词条(也有tdm,意思相反)。某个文档出现某个词汇就记为1,否则为0,得到一个由0和1构成的矩阵。
dtm <- DocumentTermMatrix(corp5)
dtm
inspect(dtm)
查看dtm的信息:
<<DocumentTermMatrix (documents: 667, terms: 1020)>>
Non-/sparse entries: 4648/675692
Sparsity : 99%
Maximal term length: 14
Weighting : term frequency (tf)
可以得到有667个文档,包含了1020个单词。另外得到矩阵的稀疏度为99%,非常稀疏,由此需要进行降维。
4. 对dtm进行降维,并转为可处理的矩阵格式
dtm <- removeSparseTerms(dtm, 0.99)
dtm
data <- as.matrix(dtm)
除此之外,还可以进行一些其他操作。比如:
查找出现过10次以上的单词有哪些?
findFreqTerms(dtm, 10)

与单词”tree”相关度在0.8以上的单词有哪些?
$tree
furnitur condo
0.97 0.87
5.层次聚类
利用R自带的dist函数求距离,这里采用的是欧式距离。再利用hcluster进行层次聚类,选用的是离差平方和”ward.D”.
data.scale <- scale(data)#先标准化
d <-dist(data.scale,method = "euclidean")
fit <- hclust(d,method = "ward.D")
plot(fit)

可以看到由于样本量较多,聚类都聚集在一起,看不清楚。为了进一步解释聚类的结果,故只选取50个文档进行聚类。
d2 <- dist(data[1:50,],method = "euclidean")
fit2 <- hclust(d2,method = "ward.D")
plot(fit2,hang=-1)
rect.hclust(fit2,8)
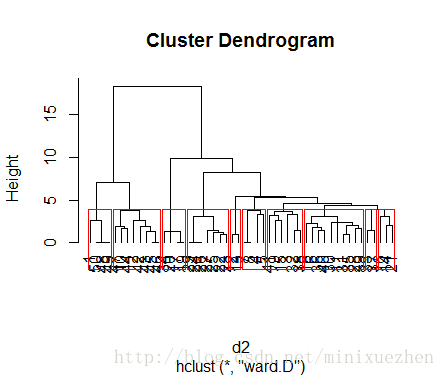
从图中可以看出,层次聚类将1,50,48,49这四个文档归为一类。查看原始的数据,

可以看出的确这四个词条的相似度很高,且48,49,50是完全相同的。用这几个词条在eBay上进行搜索,得到的结果也很相似。
6. kmeans聚类
首选要考虑的是k的取值为多少比较合适。将结果分成几类对聚类的好坏有很大的影响。分类过少可能会将两个完全不同的东西聚类为同一类,而分类过多会将相近的两样东西分离开来,从而失去了聚类的意义。
虽然聚类是无监督学习的过程,但是仍然有些指标可以在选择k值的时候作为参考。下面计算组间方差,组间方差越大,一般效果会更好。
numofk <- c()
bssp <- c()
for (i in (2:20)){
kmeans <- kmeans(data, i)
numofk[i-1] <- i
bssp[i-1] <- kmeans$betweenss/kmeans$totss
}
result <- data.frame(numofc[],bssp[])
library(ggplot2)
qplot(numofk, bssp, data = result, geom = c("point","smooth"))
一般k的取值不会太大,可以通过枚举,令k从2到一个固定值如20,在每个k值上重复计算其组间方差,得到结果用图表示。
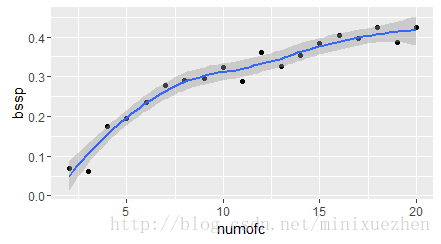
从图中可以看出,k取14类就比较合适了,14之后图形比较平稳,组间方差变化不大。
因此取k=14,用stats包中的kmeans函数进行聚类,得到的结果保存在excel表格中。
kmeansRes <- kmeans(data,15)
plot(kmeansRes$cluster)
title1 <- list(title = Raw,type = kmeansRes$cluster)
write.csv(title1,file = "Res.csv")
查看结果。

筛选查看聚类结果为type6的情况,并挑选前三条在eBay上进行搜索,搜出来的东西差不多都是狗的项圈之类的商品,说明聚类结果还算可以。同时进一步查看商品的单价,可以看出大多数单价都在2、30美金左右,但也有几条数据在50到70不等,在eBay上搜索这个价位对应的关键字,搜出来的结果也基本是训练狗的项圈,但这类商品功能更加多,也更高端,所以价格相对高,这也是合理的。