特征提取
MFCC
compute-mfcc-feats.cc
Create MFCC feature files.
Usage: compute-mfcc-feats [options...] <wav-rspecifier> <feats-wspecifier>其中参数rspecifier用于读取.wav文件,wspecifier用于写入得到的MFCC特征。典型应用中,特征将被写入到一个大的”archive”文件,同时会写入一个”scp”文件用于随机存取。该程序并未提取delta特征(add-delats.cc).
其–channel参数用于选择立体声情况(–channel=0, –channel=1).
compute-mfcc-feats --config=conf/mfcc.conf \
scp:exp/make_mfcc/train/wav1.scp \
ark:/data/mfcc/raw_mfcc_train.1.ark;第一个参数”scp:…”用于读取exp/make_mfcc/train/wav1.scp指定的文件。第二个参数”ark:…”指示计算得到的特征写入归档文件/data/mfcc/raw_mfcc_train.1.ark。归档文件里的每一句是N(frames)× N(mfcc)的特征矩阵。
MFCC特征的计算是在对象MFCC中的compute方法完成的,计算过程如下:
1.遍历每一帧(通常25ms一帧,10ms滑动)
2.对每一帧
a.提取数据,添加可选扰动,预加重和去直流,加窗
b.计算该点的能量(使用对数能量,而非C0)
c.做FFT并计算功率谱
d.计算每个梅尔频点的能量,共计23个重叠的三角频点,中心频率根据梅尔频域均匀分布。
e.计算对数能量,做离散余弦变换,保留指定的系数个数
f.倒谱系数加权,确保系数处于合理的范围。
三角梅尔频点的上下限由–low-freq和–high-freq决定,通常被分别设置成接近0和奈奎斯特频率。如对于16KHz语音–low-freq=20, –high-freq=7800。
可以使用copy-feats.cc将特征转换成其它格式。
倒谱均值和方差归一化
该归一化通常是为了获得基于说话人或者基于说话语句的零均值,单位方差归一化特征倒谱。但是并不推荐使用这个方法,而是使用基于模型的均值和方差归一化,如Linear VTLN(LVTLN)。可以使用基于音素的小语言模型进行快速归一化。特征提取代码compute-mfcc-feats.cc/compute-plp-feats.cc同样提供了–substract-mean选项获得零均值特征。如果要获得基于说话人或者基于句子的均值和方差归一化特征,可以使用
compute-cmvn-states.cc或者apply-cmvn.cc程序。
compute-cmvn-stats.cc将会计算均值和方差需要的所有统计量,并将这些统计信息以矩阵的形式写入到table中。
compute-cmvn-stats
--spk2utt=ark:data/train/train.1k/spk2utt \
scp:data/train.1k/feats.scp \
ark:exp/mono/cmvn.ark;单音素训练
初始化单音素模型
-gmm-init-mono.cc
该程序有两个输入和两个输出。做为输入,需要描述声学模型的HMM音素结构的拓扑文件(如data/lang/topo)和高斯混合模型中每个分量的维度。
如
gmm-init-mono data/lang/topo \
39 \
exp/mono/0.mdl \
exp/mono/tree;在这个例子中tree是语境决策树。
-compile-train-graphs.cc
假设我们已经得到了决策树和模型。接下来的命令创建训练集对应的HCLG图归档文件。该程序为每一个训练语句编译FST。
compile-train-graphs exp/mono/tree \
exp/mono/0.mdl \
data/L.fst \
ark:data/train.tra \
ark:exp/mono/graphs.fsts;train.tra是训练集的索引文件,该文件每一行的第一个字段是说话人ID。该程序的输出是graphs.fsts;其为train.tra中的每句话建立一个二进制格式的FST。该FST和HCLG对应,差异在于没有转移概率不在里面。这是因为该图将在训练中被多次用到且转移概率也将会发生变化,所以后面才会加上转移概率。但是归档的FST中包含了silence的概率(编码到L.fst)。解码图就是
。
1.H包括了HMM定义;输出符号是上下文无关的音素,输入符号是一系列状态转变ID(是概率id和其它信息的编码)。
2.C代表的是上下文依赖关系。其输出代表音素的符号,输入是代表上下文相关的音素符号;
3.L是字典(Lexicon);输出是单词,输入是一系列音素。
4.G表示的是Grammar;是语音模型的有限状态机。
由于训练时候不要进行符号消歧义,所以图创建要比测试时简单,训练和测试使用HCLG形式上是一样的,不同在于,训练时G仅仅包括和训练文集相关的一个线性接收器。
同样希望HCLG具有随机性,传统方法使用“push-weights”方法。
训练单音素模型
-align-equal-compiled.cc
给定声学模型/图rspecifier/特征rspecifier。这个程序会返回用于对齐的wspecifier。这是EM算法中的E步骤(EM算法见http://blog.csdn.net/shichaog/article/details/78415473)。对齐是整数向量。
align-equal-compiled 0.mdl \
graphs.fsts \
scp:train.scp \
ark:equal.ali; 如果要查看对齐结果,可以使用show-alignments.cc程序查看。
-gmm-acc-stats-ali.cc
这个程序有三个输入:1.编译好的声学模型(0.mdl);2.训练用的音频文件特征(MFCC,train.scp)3.先前计算的隐藏状态的对齐信息。输出文件是GMM训练用的状态集(0.acc)。
gmm-acc-stats-ali 0.mdl \
scp:train.scp \
ark:equal.ali \
0.acc-gmm-test.cc
这是EM算法的M步骤,给定1.声学模型; 2.GMM训练状态集,这个程序将会输出新的声学模型(经过ML估计更新)。
gmm-test --min-gaussian-occupancy=3 \
--mix-up=250 \
exp/mono/0.mdl \
exp/mono/0.acc \
exp/mono/1.mdl;参数--mix-up指定了新的混合高斯模型成分的数量。
当训练数据量小时,--min-gaussian-occupancy需要指定以处理少见的音素。
音素和数据对齐
-gmm-align-compiled.cc
给定1.声学模型;2.图的rspecifier;3.特征的rspecifier。该程序返回对齐的wspecifier。这是EM算法中的E步骤。对齐是指HMM状态和提取的语音特征向量关系。每一个HMM状态有一个高斯分布输出,对齐后的特征向量会被用于高斯参数更新(
和
).
gmm-align-compiled 1.mdl \
ark:graphs.fsts \
scp:train.scp \
ark:1.ali;三音素训练
上下文相关音素决策数构建
CART(Clustering and Regression Tree).
-acc-tree-stats.cc
该程序有三个输入参数1.声学模型,2.声学特征的rspecifier,3.前一次对齐的rspecifier。返回值是树累积量。
该程序不仅能处理单音素对齐,也能处理基于上下文关系的对齐(如三音素),构建树需要的统计量被以BuildTreeStatsType类型写入磁盘,函数AccumulateTreeStats()接收P和N。命令行程序会将P和N缺省设置成3和1,但是可以使用--context-with和--central-position选项进行更改。acc-tree-stats.cc接收一系列上下文无关音素(如,silence),这可以减少统计量的数目。
acc-tree-stats final.mdl \
scp:train.scp \
ark:JOB.ali \
JOB.treeacc;-sum-tree-statics.cc
该程序为音素树构建求和统计量,该程序输入多个*.treeacc文件,输出单个累积后统计量(如treeacc)。
sum-tree-stats treeacc \
phonesets.int \
questions.int;-compile-questions.cc
该程序的输入是1.HMM拓扑(如,topo),2.音素列表(如,questions.int),返回EventMap(如phonesets.qst)中“key”对应问题的C++对象表示的音素列表。
compile-questions data/lang/topo \
exp/triphones/questions.int \
exp/triphones/questions.qst;-build-tree.cc
当统计量累积后可以使用build-tree.cc构建树。其有三个输入参数:1.累积的树统计量(treeacc),2.问题配置(questions.qst),3.根文件(roots.int)。
树统计量使用程序acc-tree-stats.cc求得,问题配置使用程序compile-questions.cc求得,cluster-phones.cc求得音素问题拓扑列表。
build-tree建立了一系列决策树,最大叶子节点数(如2000)是概率数量,在分割之后,对每一颗树会做后聚类。共享的叶子的作用域在单棵树内。
build-tree treeacc \
roots.int \
questions.qst \
topo \
tree;可以使用程序draw-tree.cc查看决策树。
draw-tree data/lang/phones.txt \
exp/mono/tree | \
dot -Tps -Gsize=8,10.5 | \
ps2pdf - ~/tree.pdf-gmm-init-model.cc
根据1.决策树(tree),2.累积树状态(treeacc),3.HMM拓扑(topo)来初始化GMM声学模型(1.mdl)。
gmm-init-model tree \
treeacc \
topo \
1.mdl;-gmm-mixup.cc
根据1.高斯声学模型(1.mdl),2.每个状态转变ID出现次数,做高斯合并操作,返回的高斯声学模型(2.mdl)的分量数会增加。
gmm-mixup --mix-up=$numgauss \
1.mdl \
1.occs \
2.mdl-convert-ali.cc
根据1.旧的GMM模型(monophones_aligned/final.mdl),2.新的GMM模型(triphones_del/2.mdl),3.新的决策树(triphones_del/tree),4.就的对齐的rspecifier(monophones_aligned/ali..gz),该程序将返回新的对齐(triphones_del/ali..gz)。
convert-ali monophones_aligned/final.mdl \
triphones_del/2.mdl \
triphones_del/tree \
monophones_aligned/ali.*.gz \
triphones_del/ali.*.gz -compile-train-graphs.cc
给定输入1.决策树(tree),2.声学模型(2.mdl),3.字典的有限状态转换器(L.fst),4.训练文本集的rspecifier(text)将输出训练图的wspecifier(fsts.*.gz)。
compile-train-graphs tree \
1.mdl \
L.fst \
text \
fsts.*.gz;贝叶斯准则
其中
的概率源于语言模型(如n-gram)
是根据训练数据集得到的统计模型。
要找到语音对应句子,就是找
概率最大的句子。
WFST关键点
1.determinization
2.minimization
3.composition
4.equivalent
5.epsilon-free
6.functional
7.on-demand algorithm
8.weight-pushing
9.epsilon removal
HMM关键点
1.Markov Chain
2.Hidden Markov Model
3.Forward-backward algorithm
4.Viterbi algorithm
5.E-M for mixture of Gaussians
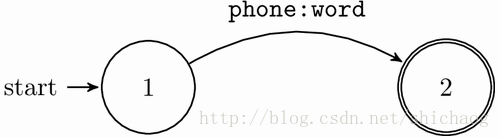
L.fst 发音字典FST
L将单音素序列映射到单词。
文件L.fst是根据音素符号序列获得单词序列的有限状态转换器。
聚类机制
类GaussClusterable(高斯统计量)继承了纯虚类Clusterable。未来会加入从Clusterable类继承来的可以聚类对象的处理。Clusterable 存在的目的是使用通用聚类算法。
Clusterable的核心思想是将统计量相加,然后评测目标函数,两个可以聚类对象的距离是指两个对象各自目标函数和他们相加之后目标函数带来的影响。
Clusterable类相加的实例有混合高斯统计量的高斯模型,离散观测量的计数值。
获得Clusterable*对象的实例如下:
Vector<BaseFloat> x_stats(10), x2_stats(10);
BaseFloat count = 100.0, var_floor = 0.01;
// initialize x_stats and x2_stats e.g. as
// x_stats = 100 * mu_i, x2_stats = 100 * (mu_i*mu_i + sigma^2_i)
Clusterable *cl = new GaussClusterable(x_stats, x2_stats, var_floor, count);聚类算法
聚类函数如下:
- ClusterBottomUp
- ClusterBottomUpCompartmentalized
- RefineClusters
- ClusterKMeans
- TreeCluster
- ClusterTopDown
常用到的数据类型是:
std::vector<Clusterable*> to_be_clustered;K-means及其类似算法接口
聚类代码调用实例如下:
std::vector<Clusterable*> to_be_clustered;
// initialize "to_be_clustered" somehow ...
std::vector<Clusterable*> clusters;
int32 num_clust = 10; // requesting 10 clusters
ClusterKMeansOptions opts; // all default.
std::vector<int32> assignments;
ClusterKMeans(to_be_clustered, num_clust, &clusters, &assignments, opts);ClusterBottomUp() 和ClusterTopDown()和ClusterKMeans()的调用方法类似,如果聚类的数量较大,ClusterTopDown()比ClusterKMeans()更高效。