一、算法
布朗聚类是一种自底向上的层次聚类算法,基于n-gram模型和马尔科夫链模型。布朗聚类是一种硬聚类,每一个词都在且只在唯一的一个类中。

w是词,c是词所属的类。
布朗聚类的输入是一个语料库,这个语料库是一个词序列,输出是一个二叉树,树的叶子节点是一个个词,树的中间节点是我们想要的类(中间结点作为根节点的子树上的所有叶子为类中的词)。
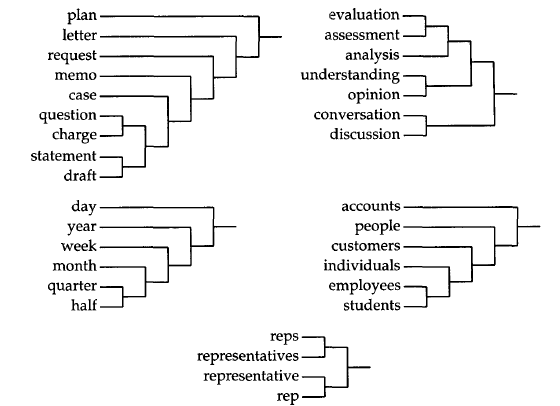
初始的时候,将每一个词独立的分成一类,然后,将两个类合并,使得合并之后评价函数最大,然后不断重复上述过程,达到想要的类的数量的时候停止合并。
上面提到的评价函数,是对于n个连续的词(w)序列能否组成一句话的概率的对数的归一化结果。于是,得到评价函数:
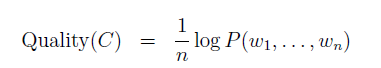
n是文本长度,w是词
上面的评价公式是PercyLiang的“Semi-supervised learning for natural languageprocessing”文章中关于布朗聚类的解释,Browm原文中是基于class-based bigram language model建立的,于是得到下面公式:
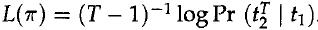

T是文本长度,t是文本中的词
上述公式是由于对于bigram,于是归一化处理只需要对T-1个bigram。我觉得PercyLiang的公式容易理解评价函数的定义,但是,Brown的推导过程更加清晰简明,所以,接下来的公式推导遵循Brown原文中的推导过程。
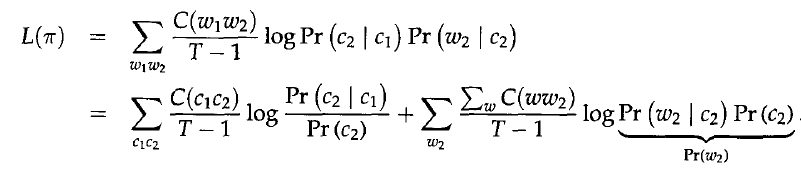
上面的推导式数学推导,接下来是一个重要的近似处理,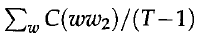
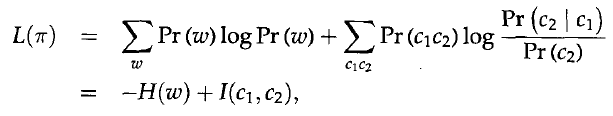
H(w)是熵,只跟1-gram的分布有关,也就是与类的分布无关,而I(c1,c2)是相邻类的平均互信息。所以,I决定了L。所以,只有最大化I,L才能最大。
二、优化
Brown提出了一种估算方式进行优化。首先,将词按照词频进行排序,将前C(词的总聚类数目)个词分到不同的C类中,然后,将接下来词频最高的词,添加到一个新的类,将(C+1)类聚类成C类,即合并两个类,使得平均互信息损失最小。虽然,这种方式使得计算不是特别精确,类的加入顺序,决定了合并的顺序,会影响结果,但是极大的降低了计算复杂度。
显然上面提及的算法仍然是一种naive的算法,算法复杂度十分高。(上述结果包括下面的复杂度结果来自Percy Liang的论文)。对于这么高的复杂度,对于成百上千词的聚类将变得不现实,于是,优化算法变得不可或缺。Percy Liang和Brown分别从两个角度去优化。
Brown从代数的角度优化,通过一个表格记录下每次合并的中间结果,然后,用来计算下一次结果。
Percy Liang从几何的角度考虑优化,更加清晰直观。但是,Percy Liang是从跟Brown的损失函数L相反的角度去考虑(即两者正负号不同),但是,都是为了保留中间结果,减少计算量,个人觉得PercyLiang的算法比较容易理解,而且,他少忽略了一些没必要计算的中间结果,更加优化,后面介绍的代码,也是PercyLiang写的,所以,将会重点介绍一下他的思考方式。
Percy Liang将聚类结果表示成一个无向图,图的节点有C个,代表C个类,同时,任何两个节点都有一条边,边代表相邻两个节点之间(两个类之间)的平均互信息。边的权重如下表达式:
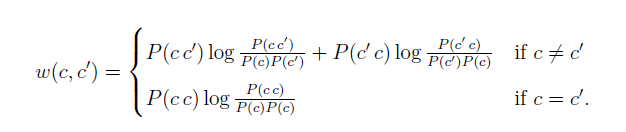
而评价的总的平均互信息I就是所有边的权重之和。下面是实际代码中的计算损失评价的函数即合并后的I减去合并前的I的损失。
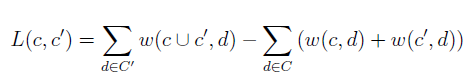
上述的(c并c')代表合并c和两个节点后的一个节点,C是当前集合,而C'是合并后的集合:

三、代码实现
代码实现的主要过程概览:
1、读取文本并预处理
1) 将文本中的每个词读入并编码(其中过滤一些频次极其低的)
2)统计词表大小、出现次数
3)将文本左右两个方向的n-gram存储
2、初始化布朗聚类(N log N)
1)将词进行排序
2)将频次最高的initC个词分配到每个类
3)初始化p1(概率),q2(边的权重)
3、进行布朗聚类
1)初始化L2(合并减少的互信息)
2) 将当前未聚类的词中,出现频次最高的,作为一个类,添加进去,并同时,计算p1,q2,L2
3)找到最小的L2
4)合并,并更新q2,L2
代码还实现了计算KL散度比较相关性,此部分略去。
这里p1如下
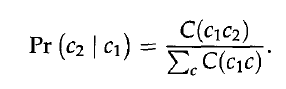
q2如下
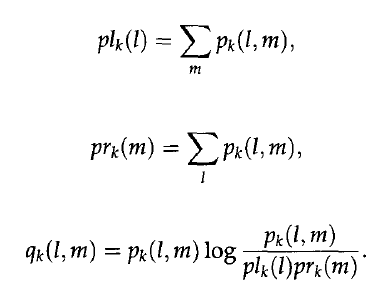
四、重要代码段解析
初始化L2:
<span style="font-size:18px;">// O(C^3) time.
void compute_L2() {
track("compute_L2()", "", true);
track_block("Computing L2", "", false)
FOR_SLOT(s) {
track_block("L2", "L2[" << Slot(s) << ", *]", false)
FOR_SLOT(t) {
if(!ORDER_VALID(s, t)) continue;
double l = L2[s][t] = compute_L2(s, t);
logs("L2[" << Slot(s) << "," << Slot(t) << "] = " << l << ", resulting minfo = " << curr_minfo-l);
}
}
}</span>上面调用,单步计算L2:
<span style="font-size:18px;">// O(C) time.
double compute_L2(int s, int t) { // compute L2[s, t]
assert(ORDER_VALID(s, t));
// st is the hypothetical new cluster that combines s and t
// Lose old associations with s and t
double l = 0.0;
for (int w = 0; w < len(slot2cluster); w++) {
if ( slot2cluster[w] == -1) continue;
l += q2[s][w] + q2[w][s];
l += q2[t][w] + q2[w][t];
}
l -= q2[s][s] + q2[t][t];
l -= bi_q2(s, t);
// Form new associations with st
FOR_SLOT(u) {
if(u == s || u == t) continue;
l -= bi_hyp_q2(_(s, t), u);
}
l -= hyp_q2(_(s, t)); // q2[st, st]
return l;
}
</span>
聚类过程中,更新p1,q2,L2,调用时(两次):
<span style="font-size:18px;">// Stage 1: Maintain initC clusters. For each of the phrases initC..N-1, make
// it into a new cluster. Then merge the optimal pair among the initC+1
// clusters.
// O(N*C^2) time.
track_block("Stage 1", "", false) {
mem_tracker.report_mem_usage();
for(int i = initC; i < len(freq_order_phrases); i++) { // Merge phrase new_a
int new_a = freq_order_phrases[i];
track("Merging phrase", i << '/' << N << ": " << Cluster(new_a), true);
logs("Mutual info: " << curr_minfo);
incorporate_new_phrase(new_a);//添加后,C->C+1
repcheck();
merge_clusters(find_opt_clusters_to_merge());//合并后,C+1->C
repcheck();
}
}
</span>添加后,更新p1,q2,L2
<span style="font-size:18px;">// Add new phrase as a cluster.
// Compute its L2 between a and all existing clusters.
// O(C^2) time, O(T) time over all calls.
void incorporate_new_phrase(int a) {
track("incorporate_new_phrase()", Cluster(a), false);
int s = put_cluster_in_free_slot(a);
init_slot(s);
cluster2rep[a] = a;
rep2cluster[a] = a;
// Compute p1
p1[s] = (double)phrase_freqs[a] / T;
// Overall all calls: O(T)
// Compute p2, q2 between a and everything in clusters
IntIntMap freqs;
freqs.clear(); // right bigrams
forvec(_, int, b, right_phrases[a]) {
b = phrase2rep.GetRoot(b);
if(!contains(rep2cluster, b)) continue;
b = rep2cluster[b];
if(!contains(cluster2slot, b)) continue;
freqs[b]++;
}
forcmap(int, b, int, count, IntIntMap, freqs) {
curr_minfo += set_p2_q2_from_count(cluster2slot[a], cluster2slot[b], count);
logs(Cluster(a) << ' ' << Cluster(b) << ' ' << count << ' ' << set_p2_q2_from_count(cluster2slot[a], cluster2slot[b], count));
}
freqs.clear(); // left bigrams
forvec(_, int, b, left_phrases[a]) {
b = phrase2rep.GetRoot(b);
if(!contains(rep2cluster, b)) continue;
b = rep2cluster[b];
if(!contains(cluster2slot, b)) continue;
freqs[b]++;
}
forcmap(int, b, int, count, IntIntMap, freqs) {
curr_minfo += set_p2_q2_from_count(cluster2slot[b], cluster2slot[a], count);
logs(Cluster(b) << ' ' << Cluster(a) << ' ' << count << ' ' << set_p2_q2_from_count(cluster2slot[b], cluster2slot[a], count));
}
curr_minfo -= q2[s][s]; // q2[s, s] was double-counted
// Update L2: O(C^2)
track_block("Update L2", "", false) {
the_job.s = s;
the_job.is_type_a = true;
// start the jobs
for (int ii=0; ii<num_threads; ii++) {
thread_start[ii].unlock(); // the thread waits for this lock to begin
}
// wait for them to be done
for (int ii=0; ii<num_threads; ii++) {
thread_idle[ii].lock(); // the thread releases the lock to finish
}
}
//dump();
}
</span>合并后,更新
<span style="font-size:18px;">// O(C^2) time.
// Merge clusters a (in slot s) and b (in slot t) into c (in slot u).
void merge_clusters(int s, int t) {
assert(ORDER_VALID(s, t));
int a = slot2cluster[s];
int b = slot2cluster[t];
int c = curr_cluster_id++;
int u = put_cluster_in_free_slot(c);
free_up_slots(s, t);
// Record merge in the cluster tree
cluster_tree[c] = _(a, b);
curr_minfo -= L2[s][t];
// Update relationship between clusters and rep phrases
int A = cluster2rep[a];
int B = cluster2rep[b];
phrase2rep.Join(A, B);
int C = phrase2rep.GetRoot(A); // New rep phrase of cluster c (merged a and b)
track("Merging clusters", Cluster(a) << " and " << Cluster(b) << " into " << c << ", lost " << L2[s][t], false);
cluster2rep.erase(a);
cluster2rep.erase(b);
rep2cluster.erase(A);
rep2cluster.erase(B);
cluster2rep[c] = C;
rep2cluster[C] = c;
// Compute p1: O(1)
p1[u] = p1[s] + p1[t];
// Compute p2: O(C)
p2[u][u] = hyp_p2(_(s, t));
FOR_SLOT(v) {
if(v == u) continue;
p2[u][v] = hyp_p2(_(s, t), v);
p2[v][u] = hyp_p2(v, _(s, t));
}
// Compute q2: O(C)
q2[u][u] = hyp_q2(_(s, t));
FOR_SLOT(v) {
if(v == u) continue;
q2[u][v] = hyp_q2(_(s, t), v);
q2[v][u] = hyp_q2(v, _(s, t));
}
// Compute L2: O(C^2)
track_block("Compute L2", "", false) {
the_job.s = s;
the_job.t = t;
the_job.u = u;
the_job.is_type_a = false;
// start the jobs
for (int ii=0; ii<num_threads; ii++) {
thread_start[ii].unlock(); // the thread waits for this lock to begin
}
// wait for them to be done
for (int ii=0; ii<num_threads; ii++) {
thread_idle[ii].lock(); // the thread releases the lock to finish
}
}
}
void merge_clusters(const IntPair &st) { merge_clusters(st.first, st.second); }
</span>更新L2过程,其中使用了多线程:
使用数据结构:
<span style="font-size:18px;">// Variables used to control the thread pool
mutex * thread_idle;
mutex * thread_start;
thread * threads;
struct Compute_L2_Job {
int s;
int t;
int u;
bool is_type_a;
};
Compute_L2_Job the_job;
bool all_done = false;
</span>初始化,将所有线程锁住:
<span style="font-size:18px;">// start the threads
thread_start = new mutex[num_threads];
thread_idle = new mutex[num_threads];
threads = new thread[num_threads];
for (int ii=0; ii<num_threads; ii++) {
thread_start[ii].lock();
thread_idle[ii].lock();
threads[ii] = thread(update_L2, ii);
}
</span><span style="font-size:18px;">// Update L2: O(C^2)
track_block("Update L2", "", false) {
the_job.s = s;
the_job.is_type_a = true;
// start the jobs
for (int ii=0; ii<num_threads; ii++) {
thread_start[ii].unlock(); // the thread waits for this lock to begin
}
// wait for them to be done
for (int ii=0; ii<num_threads; ii++) {
thread_idle[ii].lock(); // the thread releases the lock to finish
}
}
</span>第二处是在合并后
<span style="font-size:18px;">// Compute L2: O(C^2)
track_block("Compute L2", "", false) {
the_job.s = s;
the_job.t = t;
the_job.u = u;
the_job.is_type_a = false;
// start the jobs
for (int ii=0; ii<num_threads; ii++) {
thread_start[ii].unlock(); // the thread waits for this lock to begin
}
// wait for them to be done
for (int ii=0; ii<num_threads; ii++) {
thread_idle[ii].lock(); // the thread releases the lock to finish
}
}
</span>结束调用:
<span style="font-size:18px;">// finish the threads
all_done = true;
for (int ii=0; ii<num_threads; ii++) {
thread_start[ii].unlock(); // thread will grab this to start
threads[ii].join();
}
delete [] thread_start;
delete [] thread_idle;
delete [] threads;
</span>参考文献:
Liang: Semi-supervised learning for natural language processing
Brown, et al.: Class-Based n-gram Models of Natural Language
代码来源:
https://github.com/percyliang/brown-cluster