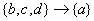版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Left_Think/article/details/41213815
关联规则
关联规则的发现是指找出支持度大于等于最小支持度(minsup),并且置信度大于最小置信度(minconf)的所有
规则。
对于关联规则分析来说,主要分为两个步骤:
1.找出频繁项集:找出满足最小支持度阈值的所有项集。2.规则的产生:从第一步中找出置信度大于最小置信度阈值的规则。一、基本定义1.支持度(support):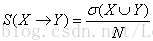 2.置信度(confidence):
2.置信度(confidence):
3.支持度计数: 其中符号| |代表求元素的个数。
其中符号| |代表求元素的个数。
二、频繁项集的产生
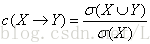
对于一个k项集来说,它可能产生
 个频繁项集,如果去计算
个项集的支持度,再去判断是否大于支持度
阈值,这样就十分繁重。下面介绍一种使用支持度度量,减少频繁项集的产生时所需要探查的候选集个数。
个频繁项集,如果去计算
个项集的支持度,再去判断是否大于支持度
阈值,这样就十分繁重。下面介绍一种使用支持度度量,减少频繁项集的产生时所需要探查的候选集个数。
个频繁项集,如果去计算
个项集的支持度,再去判断是否大于支持度
阈值,这样就十分繁重。下面介绍一种使用支持度度量,减少频繁项集的产生时所需要探查的候选集个数。
相反,若一个项集是非频繁项集,那么它的所有超集一定是非频繁项集。如下图所示,若项集{AB}是非频繁, 则包含{AB}项集的子图就可以被剪枝。1.先验原理:如果一个项集是频繁的,那么它的所有子集也一定是频繁的。
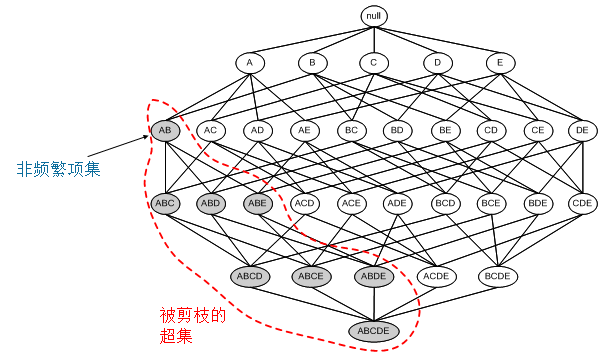 2.Apriori算法产生频繁项集Apriori算法主要步骤如下:(1)扫描数据集,确定每个项的支持度,得到所有的频繁1-项集。(2)使用上一次迭代发现的频繁(k-1)-项集,产生新的k-侯项集。(候选项集的产生使用apriori-gen函数)(3)对新产生的k-候选集的支持度计数,需要再次扫描数据集。(4)计算了候选集的支持度计数后,删去小于最小支持度阈值的候选集(5)当没有新的频繁项集产生时,算法结束。
2.Apriori算法产生频繁项集Apriori算法主要步骤如下:(1)扫描数据集,确定每个项的支持度,得到所有的频繁1-项集。(2)使用上一次迭代发现的频繁(k-1)-项集,产生新的k-侯项集。(候选项集的产生使用apriori-gen函数)(3)对新产生的k-候选集的支持度计数,需要再次扫描数据集。(4)计算了候选集的支持度计数后,删去小于最小支持度阈值的候选集(5)当没有新的频繁项集产生时,算法结束。
候选项集的产生需要注意以下几点:
(1)若它至少存在一个自己是非频繁的,则这个候选集是不必要的,产生候选集时应当避免产生过多不必要的候选集。
(2)必须确保候选项集是完整的。
(3)不会产生重复的候选项集。
这种方法运用频繁1-项集和频繁(k-1)项集进行组合,从而产生k-侯项集,再计算每个 k-侯项集的支持度进行剪枝。a.方法产生候选集:
函数apriori-gen函数产生候选项集的过程中,合并一对频繁(k-1)-项集,仅当它们的前(k-2)个项全部相 同,且它们的第k项不同。令b.方法产生候选项集:
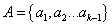 和
和
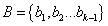 是一对频繁(k-1)-项集,当他们满足:
是一对频繁(k-1)-项集,当他们满足:

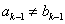
eg:假设有三个频繁项集{面包,牛奶}、{啤酒,尿布}和{面包,尿布}。
二、规则的产生
若将频繁项集Y划分成两个非空的子集X和(Y-X),使得
满足最小置信度阈值。
基于置信度的剪枝:
定理:若规则
也一定不满足置信度阈值,其中
为X的子集。
eg:若{a,b,c,d}中