文章目录
一、支持度与置信度
二、关联规则误区与注意事项
三、Apriori算法
四、序列模式关联
关联规则分析就是在交易数据、关系数据或其他信息载体中,查找存在于项目集合或对象集合之间的频繁模式、关联、相关性或因果结构。
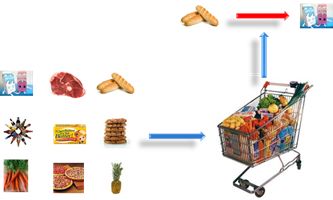
“啤酒与尿布”的例子相信很多人都听说过吧,故事是这样的:在一家超市中,人们发现了一个特别有趣的现象,尿布与啤酒这两种风马牛不相及的商品居然摆在一起。但这一奇怪的举措居然使尿布和啤酒的销量大幅增加了。为什么有这么奇怪现象呢?是因为美国妇女在丈夫回家前买尿布,然后丈夫顺手买了自己喜欢的啤酒,所以发生了这么有趣的事情。
项(Items),比如面包、牛奶,每一个都是一项。
项集(Itemset),包含k个项的集合。
交易(Transaction),包含项的非空集。表示我们的一条消费记录。
如:我们有如下数据库:
我们根据关联规则分析,得到规则:买了面包的人可能会买黄油,或者说面包对黄油的销售有促进作用。
一、支持度与置信度
1.支持度(support):交易记录中某项集出现的概率。
某关联规则的支持度:
如果支持度太低,说明很少有人按照该规则去购买,说明也没有太大的研究必要。
支持度一般按照项集k值的增加,而减少。
2.置信度(confidence)
置信度表达式:
买了X的人又买了Y,置信度是条件概率P(Y|X)。
置信度很高说明该规则很强(strong),如果某人买了X,那就非常有信心他也买了Y。
支持度表示频率,置信度表示强度。我们把它俩量化后,设置一个阈值
和:
频繁项集:
强规则:
频繁集挖掘步骤:
1.找到所有频繁项集(关键,也是最麻烦的部分。因为数据量本身巨大,组合数量规模更加爆炸。)
2.生成频繁项集所有的非空子集,找到所有可能的关联规则,然后设置阈值对关联规则进行校验。
二、关联规则误区与注意事项
1.强规则并不代表有强的实际意义。规则的置信度要和商品本身的概率进行比较。
2.当两个商品出现的概率差别非常大的时候,从数据中得到的强规则强并不代表有强的实际意义。
买电池后再买面包的置信度确实大于买面包的置信度,但买电池的毕竟只是小概率,和买面包的概率相差过大。
3.美国某地区警察局长分析,该地区针对女性犯罪的犯罪率和冰淇淋的销售率成正比。冰淇淋销售率上升,犯罪率就上升,或者说犯罪率上升,冰淇淋销售率就上升。
听起来很搞笑,但实际上我们在现实生活中也经常犯这样的错误:两件事物相关,并不代表他俩之间有因果关系。
我们探讨的关联规则只是条件概率,只能说可能会出现某种现象,不要针对数据轻易判断或者做出多余的解释。
4.例如。我们可能在购买某种关于云计算的书籍后,店家给我们了如下推荐:

这两本书可能根据cloud一词关联到了一起,但很明显这不是我们想要的,所以在进行信息关联编码时要根据关联词在不同情况下的不同含义加以区分。
三、Apriori算法
频繁集挖掘面临的最大难题就是项集的组合爆炸,如下图:
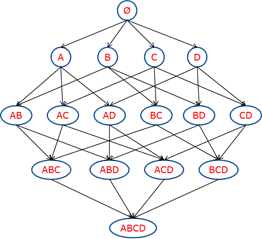
随着商品数量增多,这个网络的规模将变得特别庞大。我们不可能根据传统方法进行统计和计算。
Apriori算法中运用如下方法来大幅度削减搜索空间。
任何一个频繁项的所有非空子集必须频繁。
如果某一项不频繁,则它的所有超项都是不频繁的。
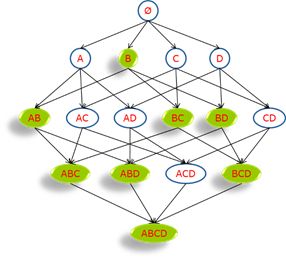
如下图,如果我们已知B不频繁,那么可以说图中所有绿色的项集都不频繁,搜索时就要这些项避开。
Apriori算法框架:
Ck:长度为k的项集
Lk:长度为k的频繁项集

如何从Lk生成 Ck+1呢?
我们的目标是在保证Ck+1包含所有长度为k+1的频繁项集的情况下,长度尽可能短。
首先对项集内的项排序(如项集为{3,1},就调整为{1,3}),我们规定只有当Lk中项集X和项集Y前k-1项相同,第k项不同时,我们才取新生成的Ck+1为X∪Y。
这种对Ck+1的生成结果不一定使用到Lk中的所有项集(高效率),但一定包含频繁项集Lk+1。
我们要获得Lk+1,就需要进一步从Ck+1中筛选。
例1:1、2、3、4、5为种商品,现在有4条购买记录,利用Apriori算法计算频繁项集。
如上图所示,我们得到了长度k为1、2、3的频繁项集L1、L2、L3 。
例2:某服装商店在某段时间内的销售记录如下:
置信度超过阈值了,看起来买牛仔裤确实对买鞋子有促进作用。
我们之前说要与描述商品本身的概率相比较,买鞋子的概率是50%,和置信度一样多,所以我们说买牛仔裤对买鞋子有促进作用是不对的。
四、序列模式关联
序列模式就是在非序列模式上加了一条时间轴,每个人买东西本身就是一个序列:
序列是一组有先后关系的项集的组合。
商品的一前一后出现是有特定含义的。
如果一条序列是另一条序列的子序列,我们就说长序列支持短序列。注意的是,长序列的子序列中每一项的排列顺序与长序列中一致。
如下图四条交易记录中,前两条中t是s的子序列,后两条则不是。
序列模式中的支持度计算方式和非序列模式一样,计算所有人中有多少人按照该项集顺序购买的概率:
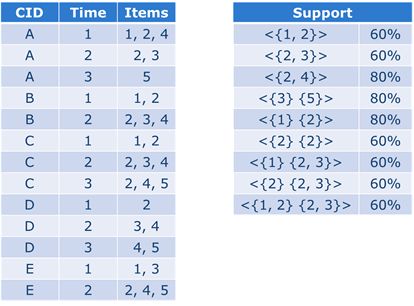
如下图,在5人的消费记录中,子序列的支持度Support计算:
序列的拼接:如果两序列中间部分完全一致,我们就可以把这两序列拼接在一起。
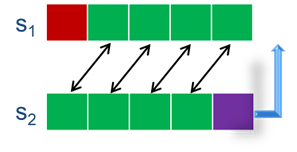
序列模式的Apriori:
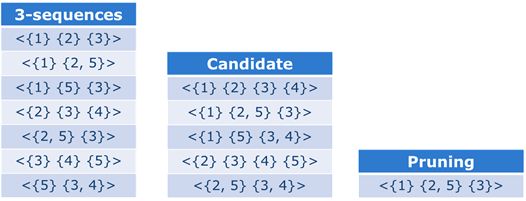
筛选后只有序列<{1} {2,5} (3)>为频繁项集