1 简介
mysql复制的原理现阶段都是一样的,master将操作记录到bin-log中,slave的一个线程去master读取bin-log,并将他们保存到relay-log中,slave的另外一个线程去重放relay-log中的操作来实现和master数据同步。
基本介绍可参考我的文章:【 http://blog.csdn.net/jesseyoung/article/details/41942467】
2 主机配置信息
2.1 相关配置介绍
开启二进制日志,建立主机唯一server ID。
在主机上开启二进制日志是因为它是master向slave复制变化数据的基础。
对一个复制组里的主机建立唯一server ID是为了将一组内的数据库服务器区分开来,server ID的取值范围为1至2^32-1之间任意值。
配置binlog及server ID时需要关闭mysql服务器,编辑my.cnf或my.ini文件,在[mysqld]选项下添加log-bin及server-id选项,例如:
注意事项:
1 如果我们忽略了server ID选项或明确指定其值为默认值0,master主机将拒绝来自slave从机的任何连接。
2 对于Innodb事务,为了提高数据的持久性及连续性,我们应该在my.cnf里面设置
已经提交的数据。
sync_binlog=n,当每进行n次事务提交之后,MySQL将进行一次fsync之类的磁盘同步指令来将binlog_cache中的数据强制写入磁盘。
3 确保master主机上skip-networking选项是禁用的,否则master主机数据库只允许通过本地mysql.sock文件进行连接,slave从机将无法联系到主机。
log-slave-updates:从库更新也写binlog,主要用于链式复制,从库作为另一个库的主库,或者HA架构中,从库可升级为主库。
skip_slave_start:阻止从库崩溃后,自动启动复制
replicate_wild_ignore_table:
replicate_wild_ignore_db:解决主从架构mysql跨库更新问题, 使用replicate_do_db和replicate_ignore_db时有一个隐患,跨库更新时会出错。
如在Master(主)服务器上设置 replicate_do_db=test
use mysql;
update test.table1 set ......
那么Slave(从)服务器上第二句将不会被执行
如Master设置 replicate_ignore_db=mysql
use mysql;
update test.table1 set ......
那么Slave上第二句会被忽略执行
原因是设置replicate_do_db或replicate_ignore_db后,MySQL执行sql前检查的是当前默认数据库,所以跨库更新语句在Slave上会被忽略。
可以在Slave上使用 replicate_wild_do_table 和 replicate_wild_ignore_table 来解决跨库更新的问题,如:
replicate_wild_do_table=test.%
或
replicate_wild_ignore_table=mysql.%
这样就可以避免出现上述问题了 3.1 相关配置介绍
slave从机开启二进制日志不是必要操作,server ID一定要设置,my.cnf文件中server-id需要设置并且与master的server-id不能冲突,例如:
设置完后重启slave从机服务器。
注意事项:
如果我们没有指定server-id或指定server-id数字为默认值0,slave从机都不会去连接主机。
如果我们开启了从机的二进制日志,我们可以将从机的binlog用于数据备份及数据损坏恢复,也可以用于复杂的复制拓扑结构中,如当前从机作为其它从机的主机。
3.2 复制相关配置模板(slave)
server_id要与主机区分开来,read_only设置为1,表示对于普通用户不能向从机写入数据,从机只接收来自于主机的同步数据。
4 在主机上创建复制用户
每个slave连接到master需要使用用户名及密码,所以master主机上需要创建用于slave访问的用户及密码。我们可以在master主机上为每个slave创建一个访问的用户名及密码,不同的slave也可以访问master的同一个用户名及密码。
使用CREATE USER创建复制用户
如果master主机上有数据,我们同步之前,需要停止向主机上做更新操作,获取master的文件及位置信息,然后将主机数据导出,导出数据可通过mysqldump等相关工具或者直接拷贝data目录。
获取master主机二进制文件位置需要如下两个步骤:
1 在master主机上使用mysql命令行客户端,将所有数据刷进磁盘,并阻塞所有的写入操作
执行该命令的mysql命令行客户端一旦关闭,该命令便会失效。
2 在master主机上使用mysql命令行客户端,查看binlog日志信息

我们可以看到包括文件名,同步位置等信息。
6 备份主机文件
在slave从机开始同步前,需要先将主机的备份文件导入,master主机备份有多种方式,我们介绍两种简单方式
6.1 通过mysqldump方式
使用该参数时,执行mysqldump前就没有必要在master主机上执行FLUSH TABLES WITH READ LOCK和SHOW MASTER STATUS等相关操作。
mysqldump详细使用方法可参考我前面的文章:【 http://blog.csdn.net/jesseyoung/article/details/41078947】
6.2 直接拷贝原始数据文件
如果数据量比较大,直接拷贝原始数据文件比使用mysqldump更加有效,也省去了执行insert语句更新索引的开销。
6.2.1 包含InnoDB表的拷贝:
1 在master主机上使用mysql命令行客户端,将所有数据刷进磁盘,并阻塞所有的写入操作
6.2.2 不包含InnoDB表的拷贝:
1 在master主机上使用mysql命令行客户端,将所有数据刷进磁盘,并阻塞所有的写入操作
可自行研究。
7 在从机上设置复制
7.1 初始安装mysql设置主从复制
最简单的方式是在两台新安装的mysql主机上设置主从复制。
设置步骤如下:
1 配置master主机my.cnf文件(参考上面第2节-主机配置信息)
2 启动mysql master服务
3 在master上设置复制用户及密码(参考上面第4节-在主机上创建复制用户)。
4 获取master主机binlog信息(参考上面第5节)
5 在master上释放读锁(如果前面执行过FLUSH TABLES WITH READ LOCK;)
7 启动slave mysqld服务
8 在slave从机上执行change master操作(参考下面第9节)
9 在slave从机上启动复制线程
10 查看主从复制状态
注意:
如果mysql采用5.6及其后续版本,开启了GTID,第四步可省略,slave会自动寻找master主节点binlog文件及位置。
7.2 已有数据的mysql设置主从复制
如果master主机中已经存在数据,新加入slave从机进行同步,同步前需要从主机上拿到备份文件,获取备份文件可使用mysqldump,xtrabackup或直接拷贝原始数据文件等。
配置的基本方法如下:
对于master的设置方法不在赘述,可参考上面第2节
对于master数据文件的备份方法不在赘述,可参考上面第6节
对于slave从机的操作步骤如下:
1 更新从机的配置文件(参考上面第3节)
2 将数据导入从机
2.1 使用mysqldump备份的数据导入
启动slave mysql数据库
导入从master获得的备份数据
解压从master获得的备份数据到salve的data目录
启动slave mysql数据库
3 在slave从机上执行change master操作(参考后面第九节)
4 在slave从机上启动复制线程
注:
slave从库使用的信息存储在它的主机信息库里面,以便追踪master的二进制日志应用了多少。信息库可以是文件或表的形式,取决于参数--master-info-repository,如果该参数是FILE,我们可以在从机的data目录下看到master.info 和 relay-log.info两个文件,如果参数是TABLE,相关信息会存储在mysql库的slave_master_info表里面。这两种情况之下都不建议删除或修改文件或表,除非明确知道我们要做什么并充分理解这样做所带来的影响。
8 向主从复制环境中添加额外的从机
向现有复制环境增加一台slave从机,可以参考下面方法。
1 关闭已有的slave
【详细】
3 从已有slave拷贝master info以及relay log info信息到新的slave,它们包含master的二进制日志及slave的relay log日志的当前位置。
4 启动已有slave
5 在新的slave上编辑my.cnf配置文件,确保server-id 没有被master及其他slave使用。
6 启动新的salve。新的slave使用master信息库开启复制进程。
9 在slave从机上设置主机配置信息
原文地址: http://blog.csdn.net/jesseyoung/article/details/41894521
博客主页: http://blog.csdn.net/jesseyoung
****************************************************************************************
mysql复制的原理现阶段都是一样的,master将操作记录到bin-log中,slave的一个线程去master读取bin-log,并将他们保存到relay-log中,slave的另外一个线程去重放relay-log中的操作来实现和master数据同步。
基本介绍可参考我的文章:【 http://blog.csdn.net/jesseyoung/article/details/41942467】
2 主机配置信息
2.1 相关配置介绍
开启二进制日志,建立主机唯一server ID。
在主机上开启二进制日志是因为它是master向slave复制变化数据的基础。
对一个复制组里的主机建立唯一server ID是为了将一组内的数据库服务器区分开来,server ID的取值范围为1至2^32-1之间任意值。
配置binlog及server ID时需要关闭mysql服务器,编辑my.cnf或my.ini文件,在[mysqld]选项下添加log-bin及server-id选项,例如:
[mysqld]
log-bin=mysql-bin
server-id=1注意事项:
1 如果我们忽略了server ID选项或明确指定其值为默认值0,master主机将拒绝来自slave从机的任何连接。
2 对于Innodb事务,为了提高数据的持久性及连续性,我们应该在my.cnf里面设置
[mysqld]
innodb_flush_log_at_trx_commit=1
sync_binlog=1已经提交的数据。
sync_binlog=n,当每进行n次事务提交之后,MySQL将进行一次fsync之类的磁盘同步指令来将binlog_cache中的数据强制写入磁盘。
3 确保master主机上skip-networking选项是禁用的,否则master主机数据库只允许通过本地mysql.sock文件进行连接,slave从机将无法联系到主机。
[mysqld]
#skip-networking2.2复制相关配置模板(master)
[mysqld]
server_id = 123
binlog_format = mixed
log-bin = mysql-bin
relay-log = mysql-relay-bin
log-slave-updates = 1
#skip_slave_start = 1
#replicate_wild_ignore_table = mysql.****_%
read_only = 0
####性能相关####
innodb_flush_log_at_trx_commit = 1
sync_binlog = 1
####复制方式相关####
plugin-load = "rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
rpl-semi-sync-master-enabled = 1
rpl-semi-sync-slave-enabled = 1
####复制错误相关####
#replicate-ignore-table = mysql.***
slave-skip-errors = ddl_exist_errors
####复制信息相关####
relay-log-info-repository = TABLE
relay_log_recovery = 1
master_info_repository = TABLE
####GTID相关####
gtid-mode = ON
enforce-gtid-consistency = 1
log-slave-updates:从库更新也写binlog,主要用于链式复制,从库作为另一个库的主库,或者HA架构中,从库可升级为主库。
skip_slave_start:阻止从库崩溃后,自动启动复制
replicate_wild_ignore_table:
replicate_wild_ignore_db:解决主从架构mysql跨库更新问题, 使用replicate_do_db和replicate_ignore_db时有一个隐患,跨库更新时会出错。
如在Master(主)服务器上设置 replicate_do_db=test
use mysql;
update test.table1 set ......
那么Slave(从)服务器上第二句将不会被执行
如Master设置 replicate_ignore_db=mysql
use mysql;
update test.table1 set ......
那么Slave上第二句会被忽略执行
原因是设置replicate_do_db或replicate_ignore_db后,MySQL执行sql前检查的是当前默认数据库,所以跨库更新语句在Slave上会被忽略。
可以在Slave上使用 replicate_wild_do_table 和 replicate_wild_ignore_table 来解决跨库更新的问题,如:
replicate_wild_do_table=test.%
或
replicate_wild_ignore_table=mysql.%
这样就可以避免出现上述问题了 3.1 相关配置介绍
slave从机开启二进制日志不是必要操作,server ID一定要设置,my.cnf文件中server-id需要设置并且与master的server-id不能冲突,例如:
[mysqld]
#log-bin=mysql-bin
server-id=2设置完后重启slave从机服务器。
注意事项:
如果我们没有指定server-id或指定server-id数字为默认值0,slave从机都不会去连接主机。
如果我们开启了从机的二进制日志,我们可以将从机的binlog用于数据备份及数据损坏恢复,也可以用于复杂的复制拓扑结构中,如当前从机作为其它从机的主机。
3.2 复制相关配置模板(slave)
[mysqld]
server_id = 456
binlog_format = mixed
log-bin = mysql-bin
relay-log = mysql-relay-bin
log-slave-updates = 1
#skip_slave_start = 1
#replicate_wild_ignore_table = mysql.****_%
read_only = 1
####性能相关####
innodb_flush_log_at_trx_commit = 1
sync_binlog = 1
####复制方式相关####
plugin-load = "rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
rpl-semi-sync-master-enabled = 1
rpl-semi-sync-slave-enabled = 1
####复制错误相关####
#replicate-ignore-table = mysql.***
slave-skip-errors = ddl_exist_errors
####复制信息相关####
relay-log-info-repository = TABLE
relay_log_recovery = 1
master_info_repository = TABLE
####GTID相关####
gtid-mode = ON
enforce-gtid-consistency = 1server_id要与主机区分开来,read_only设置为1,表示对于普通用户不能向从机写入数据,从机只接收来自于主机的同步数据。
4 在主机上创建复制用户
每个slave连接到master需要使用用户名及密码,所以master主机上需要创建用于slave访问的用户及密码。我们可以在master主机上为每个slave创建一个访问的用户名及密码,不同的slave也可以访问master的同一个用户名及密码。
使用CREATE USER创建复制用户
mysql> CREATE USER 'repl'@'%' IDENTIFIED BY 'replpassword';mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%' IDENTIFIED BY 'replpassword';如果master主机上有数据,我们同步之前,需要停止向主机上做更新操作,获取master的文件及位置信息,然后将主机数据导出,导出数据可通过mysqldump等相关工具或者直接拷贝data目录。
获取master主机二进制文件位置需要如下两个步骤:
1 在master主机上使用mysql命令行客户端,将所有数据刷进磁盘,并阻塞所有的写入操作
mysql> FLUSH TABLES WITH READ LOCK;执行该命令的mysql命令行客户端一旦关闭,该命令便会失效。
2 在master主机上使用mysql命令行客户端,查看binlog日志信息
mysql> SHOW MASTER STATUS;
我们可以看到包括文件名,同步位置等信息。
6 备份主机文件
在slave从机开始同步前,需要先将主机的备份文件导入,master主机备份有多种方式,我们介绍两种简单方式
6.1 通过mysqldump方式
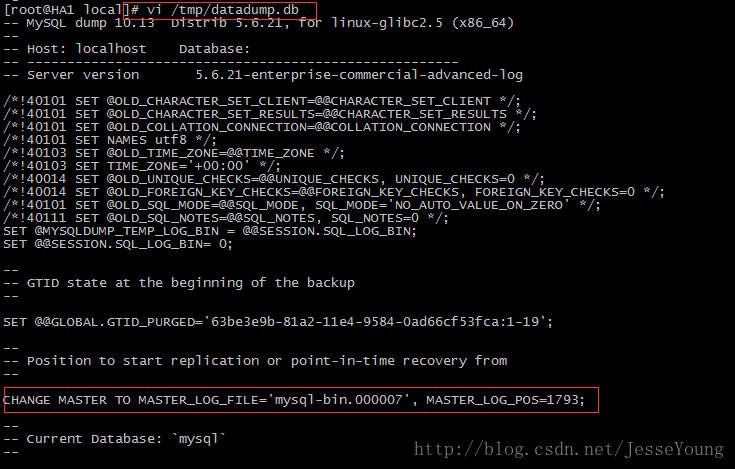
[root@HA1 data]# /usr/local/mysql/bin/mysqldump --all-databases --master-data > /tmp/datadump.db使用该参数时,执行mysqldump前就没有必要在master主机上执行FLUSH TABLES WITH READ LOCK和SHOW MASTER STATUS等相关操作。
mysqldump详细使用方法可参考我前面的文章:【 http://blog.csdn.net/jesseyoung/article/details/41078947】
6.2 直接拷贝原始数据文件
如果数据量比较大,直接拷贝原始数据文件比使用mysqldump更加有效,也省去了执行insert语句更新索引的开销。
6.2.1 包含InnoDB表的拷贝:
1 在master主机上使用mysql命令行客户端,将所有数据刷进磁盘,并阻塞所有的写入操作
mysql> FLUSH TABLES WITH READ LOCK;[root@HA1 data]# mysqladmin shutdown[root@HA1 data]# tar czvf /tmp/databack.tar.gz /usr/local/mysql/data6.2.2 不包含InnoDB表的拷贝:
1 在master主机上使用mysql命令行客户端,将所有数据刷进磁盘,并阻塞所有的写入操作
mysql> FLUSH TABLES WITH READ LOCK;[root@HA1 data]# tar czvf /tmp/databack.tar.gz /usr/local/mysql/datamysql> UNLOCK TABLES;可自行研究。
7 在从机上设置复制
7.1 初始安装mysql设置主从复制
最简单的方式是在两台新安装的mysql主机上设置主从复制。
设置步骤如下:
1 配置master主机my.cnf文件(参考上面第2节-主机配置信息)
2 启动mysql master服务
3 在master上设置复制用户及密码(参考上面第4节-在主机上创建复制用户)。
4 获取master主机binlog信息(参考上面第5节)
5 在master上释放读锁(如果前面执行过FLUSH TABLES WITH READ LOCK;)
mysql> UNLOCK TABLES;7 启动slave mysqld服务
8 在slave从机上执行change master操作(参考下面第9节)
9 在slave从机上启动复制线程
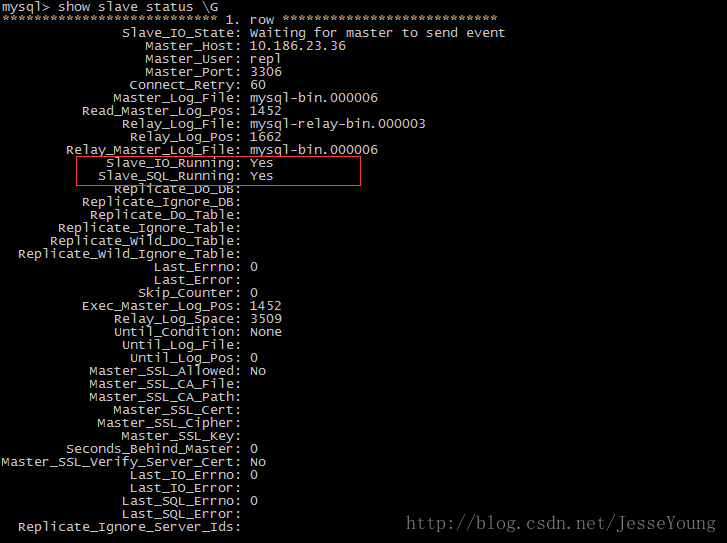
mysql> START SLAVE;10 查看主从复制状态
mysql> show slave status \G注意:
如果mysql采用5.6及其后续版本,开启了GTID,第四步可省略,slave会自动寻找master主节点binlog文件及位置。
7.2 已有数据的mysql设置主从复制
如果master主机中已经存在数据,新加入slave从机进行同步,同步前需要从主机上拿到备份文件,获取备份文件可使用mysqldump,xtrabackup或直接拷贝原始数据文件等。
配置的基本方法如下:
对于master的设置方法不在赘述,可参考上面第2节
对于master数据文件的备份方法不在赘述,可参考上面第6节
对于slave从机的操作步骤如下:
1 更新从机的配置文件(参考上面第3节)
2 将数据导入从机
2.1 使用mysqldump备份的数据导入
启动slave mysql数据库
导入从master获得的备份数据
[root@HA1 data]# mysql < datadump.db解压从master获得的备份数据到salve的data目录
[root@HA1 data]# tar xzvf databack.tar.gz启动slave mysql数据库
3 在slave从机上执行change master操作(参考后面第九节)
4 在slave从机上启动复制线程
mysql> START SLAVE;注:
slave从库使用的信息存储在它的主机信息库里面,以便追踪master的二进制日志应用了多少。信息库可以是文件或表的形式,取决于参数--master-info-repository,如果该参数是FILE,我们可以在从机的data目录下看到master.info 和 relay-log.info两个文件,如果参数是TABLE,相关信息会存储在mysql库的slave_master_info表里面。这两种情况之下都不建议删除或修改文件或表,除非明确知道我们要做什么并充分理解这样做所带来的影响。
8 向主从复制环境中添加额外的从机
向现有复制环境增加一台slave从机,可以参考下面方法。
1 关闭已有的slave
shell> mysqladmin shutdown【详细】
3 从已有slave拷贝master info以及relay log info信息到新的slave,它们包含master的二进制日志及slave的relay log日志的当前位置。
4 启动已有slave
5 在新的slave上编辑my.cnf配置文件,确保server-id 没有被master及其他slave使用。
6 启动新的salve。新的slave使用master信息库开启复制进程。
9 在slave从机上设置主机配置信息
设置从机与master主机进行通信,我们必须告诉从机必须的连接信息
9.1 基本的配置如下:
mysql> CHANGE MASTER TO
-> MASTER_HOST='master_host_name',
-> MASTER_USER='replication_user_name',
-> MASTER_PASSWORD='replication_password',
-> MASTER_LOG_FILE='recorded_log_file_name',
-> MASTER_LOG_POS=recorded_log_position;mysql> CHANGE MASTER TO MASTER_HOST = '10.186.23.36', MASTER_USER = 'repl', MASTER_PASSWORD = 'replpassword', MASTER_PORT = 3306, MASTER_LOG_FILE = 'mysql-bin.000005', MASTER_LOG_POS = 524, MASTER_RETRY_COUNT = 0, MASTER_HEARTBEAT_PERIOD = 10000;mysql> CHANGE MASTER TO
-> MASTER_HOST='master_host_name',
-> MASTER_USER='replication_user_name',
-> MASTER_PASSWORD='replication_password',
-> MASTER_AUTO_POSITION = 1;mysql> CHANGE MASTER TO MASTER_HOST = '10.186.23.36', MASTER_USER = 'repl', MASTER_PASSWORD = 'replpassword', MASTER_PORT = 3306, MASTER_AUTO_POSITION = 1, MASTER_RETRY_COUNT = 0, MASTER_HEARTBEAT_PERIOD = 10000;关于change master的详细用法,可参考我其它文章【http://blog.csdn.net/jesseyoung/article/details/41942809】。
原文地址: http://blog.csdn.net/jesseyoung/article/details/41894521
博客主页: http://blog.csdn.net/jesseyoung
****************************************************************************************