内核以页框为基本单位管理物理内存(页框是主存的一部分,是一个存储区域。页是一个数据块,可以存放在任何页框或磁盘中。)
一、页框描述
1、 内核为每个页框都建立了一个page结构(使用struct page结构体描述每个页框)
2、page结构
(1)采用元数据与数据分离的方案:page结构并不存放在其所描述的页框内;专门从内存中分配了若干空间,存储所有页框的page结构
(2)从线性地址空间角度,在64位系统中:所有page结构都依页框号依次存放在vmemmap开始的地方。在32位系统中:所有的page结构被放在mem_map数组中。
#define vmemmap ((struct page*)VMEMMAP_START)
#define VMEMMAP_START _AC(0xffffea0000000000,UL)
#define _AC(X,Y) (X##Y)
(3)struct page
3、页框号pfn和page结构之间的转换
pfn_to_page: vmemmap + pfn
page_to_pfn:(unsignedlong)(page - vmemmap)
二、页框组织
1、如何管理有效区域?(比如如何提供判断某个页框pfn是否有效的功能)
在一些系统中,物理地址空间存在许多的空洞——无效区域。内核会为每个页框建立一个page结构,如果包括了空洞区域,将造成很大的空间浪费。因此,内核需要管理有效区域,只为或尽量只为有效区域中的页框建立page结构。
可以用下面的方法:
(1)以页框为粒度,如位向量、…………
对于64位系统(现在可用的为46位),使用位向量时需要耗费2G内存。2^46除以2^12(页框大小4KB)再除以2^3(字节)=2^31(2G)
缺点:空间复杂度同页框(无效+有效)个数线性相关,扩展性差。
(2)以若干长度不等的有效或空洞区域为粒度?,如线段树、…………
缺点:时间复杂度差,和有效区域个数成log关系
因此Linux内核以section为粒度,在时间和空间的折中,在理论上牺牲了一定的准确性。
2、section
(1)section
Linux内核将物理地址空间划分成若干个section,每个section大小一样,拥有PAGES_PER_SECTION(0x8000)个页框,即128MB。
64位系统物理地址划分:
bit0—bit11:页内字节偏移量bit12—bit26:section内的页框偏移量bit12—bit45:页框号bit27—bit45:section号共计NR_MEM_SECTIONS(0x80000)个section
(2)mem_section
内核使用mem_section结构体来描述每一个section
struct mem_section {
unsigned long section_mem_map;
unsigned long *pageblock_flags;
};
1)section_mem_map包括两个部分
page结构数组的线性地址;
标志位:
SECTION_MARKED_PRESENT:bit0
SECTION_HAS_MEM_MAP:bit1
2)pageblock_flags
指向一段空间,存放了当前section内所有页框的迁移等属性。该段空间32字节,此处页框粒度不是4KB,而是2MB,因此2MB页框数为0x40,每个页框使用4个bit的标志,共计256bit
不同section的page结构、 pageblock_flags指向的空间,在同一个node内,在物理地址上是连续的。
3、section的组织--root
每个section,都有一个mem_section结构。同page结构一样,由于空洞的存在,一些section或者连续的section是无效的,不必创建。怎么办?
内核将每SECTIONS_PER_ROOT(0x80)个section,组织成一个root,一个root包含0x400000个页框,共16GB。
物理地址划分:
bit0—bit11:页内字节偏移量bit12—bit26:section内的页框偏移量bit27—bit33:root内section的偏移量bit12—bit45:页框号bit27—bit45:section号bit34—bit45:root号共计NR_MEM_SECTIONS(0x80000)个section共计NR_SECTION_ROOTS(0x1000)个root
内核没有提供专门的元数据类型描述root,root就是mem_section结构数组,所有root的地址,都放在mem_section指针数组中
struct mem_section *mem_section[NR_SECTION_ROOTS];
4、root/section的构建过程
section、page结构的建立依赖于memblock.memory(
结构体memblock的全局实例memblock保存了内存region信息
)
(1)对memblock.memory中的每个内存region,检查对应的root是否存在,若不存在则申请root空间,并保存到root表中
(2)创建root空间
(3)设置内存region对应的mem_section的section_mem_map字段的bit0(SECTION_MARKED_PRESENT )
(4)为设置了SECTION_MARKED_PRESENT位的mem_section,以node为单位:
1)统计需要的page结构体总数,分配page结构体数组
2)统计需要的pageblock_flags指向空间的总大小,并分配
(5)设置section_mem_map、pageblock_flags,并设置SECTION_HAS_MEM_MAP位
5、页框组织关系图

上面个地址都是物理地址。
6、一个section内,哪怕只有一个页框有效,这个section也会建立,所有page结构也会建立。因此section的管理方式在理论上损失了一定正确性。
三、空闲页框的组织
1、内存管理的关键之一在于碎片问题,对页框管理而言,主要是外碎片(外碎片对页框管理而言带来的危害不大,利用页表机制,可以映射非连续的空闲页框,碎片化的页框仍然可以得到使用)
2、内核在很多场景下,需要连续的页框,例如:DMA;连续的页框有利于减少元数据,提高空间利用率;需要支持大页(2MB、1GB的页),也需要连续的页框等。因此内核使用buddy system算法(伙伴系统算法),记录空闲连续页框块的情况,以尽量避免为满足对小块的请求而分割大的内存块。
3、buddy 系统
(1)buddy系统将空闲页框分组为11个块链表,每个块链表分别包含大小为1、2、4、8、16、32、64、128、256、512、1024个连续的页框
分别对应2^order,order=0、1、2、……、10
比如:
链表0中,每个页框块的大小是2^0个连续页框
链表1中,每个页框块的大小是2^1个连续页框
…………………
链表10中,每个页框块的大小是2^10个连续页框
每个页框大小为4KB因此,链表10中,页框块大小为4MB。
(2)注意:buddy系统中每个页框块的第一个页框的物理地址是该块大小的整数倍。例如:大小为16个页框的块,其起始地址是16*2^12的倍数。
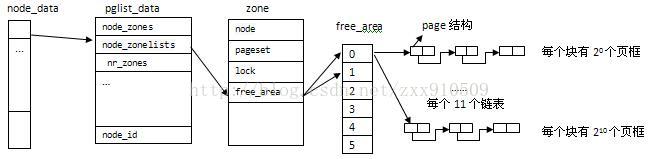
(3)结构体zone中的free_area数组,即对应了buddy系统中的11个链表。
struct free_area free_area[MAX_ORDER];//MAX_ORDER =11
但是,每个free_area中并不只是一个链表,free_area中,每种迁移类型对应一个free_list。(将物理内存按照迁移属性划分成若干区域后,有利于减少碎片,不可移动页面的影响被局限在不可移动类别页面中,有利于其他迁移属性区域尽可能获得大的连续物理内存。)
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;//页框块的个数
};enum {
MIGRATE_UNMOVABLE,//从这里分配的页面不可移动
MIGRATE_RECLAIMABLE,//从这里分配的页面可用于回收,这类页不能直接移动,但可以删除,其内容页可以从其他地方重新生成,例如,映射自文件的数据属于这种类型
MIGRATE_MOVABLE,//从这里分配的页面可以移动,大部分应用程序的页面可从这里分配,
MIGRATE_PCPTYPES,//用于per cpu区域,常简称为pcp
MIGRATE_RESERVE = MIGRATE_PCPTYPES,
MIGRATE_CMA,//模拟ZONE_MOVABLE的工作方式,只有可移动的页面才能从此区域分配,
MIGRATE_ISOLATE,//用于跨越NUMA节点移动物理内存页。在大型系统上,它有益于将物理内存页移动到接近于使用该页最频繁的CPU
MIGRATE_TYPES //6
};
每个free_list指向页框块中第一个页框的page结构的lru字段(而不是page结构的首地址),第一个页框的page结构的lru字段,指向链表中下一个页框块的第一个页框的page结构的lru字段......
四、页框的分配与释放
1、页框的分配:
一次只能向Buddy系统申请2^order个页框
(1)内核根据order和迁移类型,找到分配的链表
(2)若该链表有空闲页框块,则返回给申请者
(3)若该链表没有空闲页框块,搜索order+1对应的链表:若有空闲页框块,则返回一半页框块给申请者,并将另外一半放入order对应的链表中,否则,递归地访问order+2对应的链表
例如:申请256个页框
先在order=8对应的链表中查找,若未找到空闲页框块:
然后在order=9对应的链表中查找,若未找到空闲页框块:
在order=10对应的链表中查找,找到了将256个页框交给申请者,将256个页框放到order=8对应的链表中,将512个页框放到order=9对应的链表中。
2、页框的释放:
向buddy系统归还页框块时(page结构、order):找到对应的链表;判断其伙伴块是否也是空闲的,若伙伴块是空闲的,则合并伙伴块和归还块。合并后,递归判断新合并块的伙伴是否空闲。当不能再合并时,将合并块放入对应链表中。
伙伴块:
(1)与归还块大小一样;
(2)物理地址上与归还块连续
(3)这两个页框块的第一个页框的地址,满足buddy系统算法要求是(2*归还块页框数*页框大小)的倍数
例如:假设有页框0~7,页框2-3没有分出去,其余都已分配,当释放了4-5后,页框4-5加入链表1(2^1),但是页框2-3与页框4-5不能合并加入链表2(2^2),因为合并后的页框首地址(2)不是4的倍数。再次申请4个页框时,将会显示页框不足,因为首先会在链表2(2^2)上进行申请。
五、每CPU页框高速缓存
内核经常请求和释放单个页框;基本的页框分配和释放操作,每次都需要使用自旋锁,对zone结构进行加锁;为了提高单个页框的申请和释放效率,内核建立了每cpu页框高速缓存,其中存放了若干预先分配好的页框;当请求单个页框时,直接从当前cpu的页框高速缓存中获取页框,不必加锁
,不必进行复杂的页框分配操作。
zone结构中的pageset字段,指向了每cpu页框高速缓存。
struct per_cpu_pageset __percpu *pageset;//pageset是gs段内偏移量
#define __percpu
struct per_cpu_pageset {
struct per_cpu_pages pcp;
};struct per_cpu_pages {
int count;//lists中页框的个数
int batch;//当lists中页面不够或者过多时,一次性添加或删除的页框数量
struct list_head lists[MIGRATE_PCPTYPES];
};
七、页框分配时,node和zone的选择