版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Gpwner/article/details/78404192
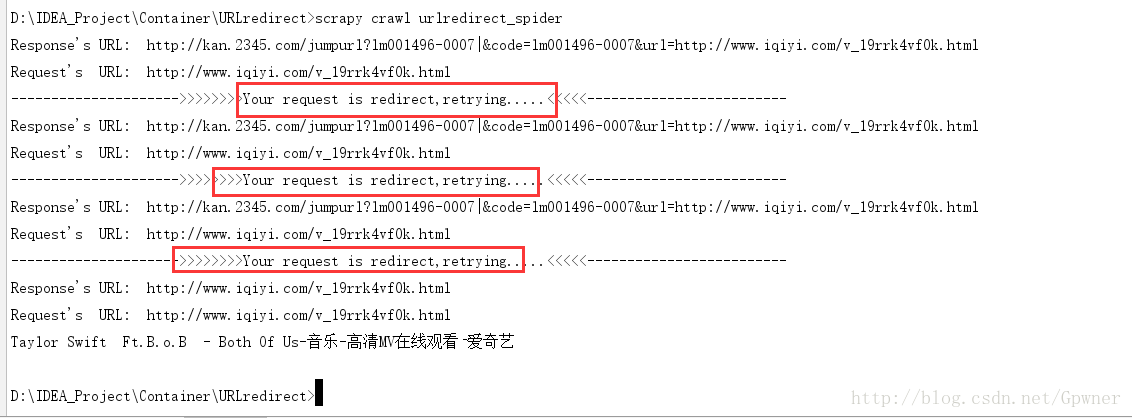
在写爱奇艺爬虫的时候经常碰到URL被重定向的问题,导致无法请求到数据:
以下是我的代码:
# -*- coding: utf-8 -*-
import scrapy
headers = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
import re
class URLredirect(scrapy.Spider):
name = 'urlredirect_spider'
def start_requests(self):
reqs = []
url = 'http://www.iqiyi.com/v_19rrk4vf0k.html'
req = scrapy.Request(url, headers=headers, meta={'url': url})
reqs.append(req)
return reqs
def parse(self, response):
responseURL = response.url
requestURL = response.meta['url']
print '''Response's URL: ''', response.url
print '''Request's URL: ''', response.meta['url']
if str(responseURL).__eq__(requestURL):
print re.compile('<title>(.*?)</title>').findall(response.body)[0].decode('utf-8')
else:
print '--------------------->>>>>>>>Your request is redirect,retrying.....<<<<<-------------------------'
yield scrapy.Request(url=requestURL, headers=headers, meta={'url': requestURL}, callback=self.parse)
大致意思就是判断如果没被重定向就解析网页,如果被重定向了就重新请求,以下是执行的结果:

解决的办法是在Request中将scrapy的dont_filter=True,因为scrapy是默认过滤掉重复的请求URL
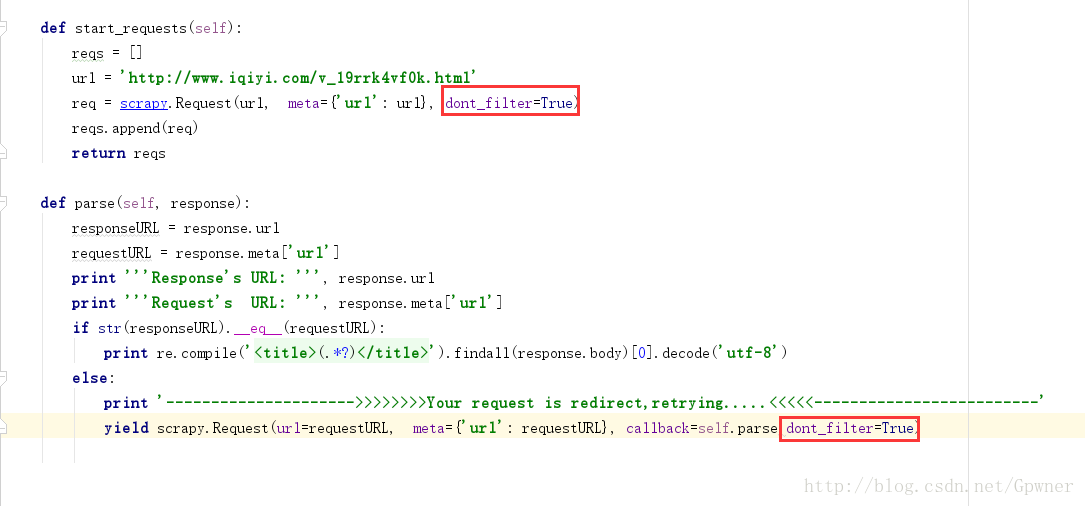
添加上参数之后即使被重定向了也能请求到正常的数据了