故事是这样的,在没有王者农药之前,笔者大部分业余时间都是靠着有毒的免费小说来打发的。那时都是先通过百度搜索小说名,然后进入相应的小说网站来看,有很多不爽的体验:第一,每次都要百度,去找有这个小说的网站;第二,每家网站的更新速度不一样,有时要切换很多次才能找到最新章节;第三,这些小说网站都有很多广告,严重影响了阅读体验。
大概在今年年初的时候,萌生了一个想法,就是打造一个自己的搜书系统,基本的思路是:从各个小说网站爬取相关的书籍信息,通过一个手机客户端来阅读小说。经过半年多的打造,目前该系统已经基本完成,这里主要从技术角度来做些分享。
整个系统架构如下图所示,数据系统和Web服务组成了后端服务,客户端采用Android开发(笔者屌丝,买不起iphone)。数据系统,一方面负责从各个小说网站采集数据,按照既定的格式进行存储;另一方面将采集的原始数据进行异步加工,生成适合搜索、可以快速访问的中间数据。Web服务,主要提供REST API供前端访问,包括搜索服务、获取书籍列表等等。值得一提的是,考虑到版权和存储容量的问题,从外部小说网站采集过来的只是一些摘要信息和原始链接,不涉及具体的小说文章内容(后面会具体介绍)。因此,Andorid端就主要负责搜索、书籍列表展示和从原始链接的HTML中提取小说内容进行显示即可。

整个后端服务是系统的关键,Android App只是内容展现的一种方式而已,因此这里将重点介绍后端服务。本文将从系统设计的角度,来谈谈设计的思路和踩过的坑,后面将另起一文来介绍如何基于Elasticsearch构建系统的搜索服务。
数据爬取
数据的爬取工作,需要考虑这么几点:
- 从哪里爬取数据?
- 爬取什么数据?
- 如何进行全量爬取和增量更新?
- 数据如何存储?
- 采用何种爬虫框架来实现?
带着这些问题,调研了几家排名较前的免费小说网站,惊奇的发现各家的网站布局结构几乎一致,基本由四部分组成:
1)首页,里面是一些热门和推荐的小数,以HTML表格形式呈现。
2)某本书的摘要信息页面,从中可以提取出该小说的基本信息。另外,页面URL的格式基本是http://domain/book/id,id就是这本书在数据库中的存储id,由此我们可以推断出该网站总共拥有多少本书,在做全量爬取时,直接循环替换这个id就可以了。
3)某本书的目录页,从中可以提取出该小说的所有章节名称和链接。该页面的URL格式页基本也是携带id的格式。
4)某本书某章节的具体内容页面,从中可以提取出该章节的小说内容,HTML的格式也基本一致。
下图所示即为某网站的一个摘要信息页面。

各个网站布局的一致性让人非常惊喜,这意味着可以用比较通用的一套代码来完成所有的数据爬取工作。结合上面的网页结构分析,基本可以确定数据爬取的实现方案。
1)爬取内容为两部分:一个是书的基本信息,另一个是书的所有章节信息。二者均为格式化的数据,考虑使用MySQL来存储,采用两张关联的表来存储数据。前文也提到,这里只存储相应的小说章节的链接,并不断更新,不会存储具体的小说章节文字内容。

2)如前面分析所言,网站中某本书的摘要信息和目录信息页面的URL都是由id组成的,因此在全量爬取时,尝试从id=0开始爬取,然后逐渐递增id来构建新的URL,直到连续10个URL都是无效的为止,如此便可以爬取该网站的全部小说信息了。全量爬取比较耗费时间,因此只做一次,在这之后就是每日的增量更新了。增量更新时选取最近15天内没有更新过的小说的URL,重新去爬取它的章节信息即可。
3)关于爬虫框架的选择,因为笔者对Python比较熟悉,所以优先考虑与之相关的框架。Scrapy是一个不错的选择,可以实现快速开发,抓取Web网站并从页面中提取结构化的数据,能较好的满足需求,具体如何使用Scrapy这里不做详细描述。至于在爬取过程中如何有效的避免反爬虫,笔者的策略是具体问题具体分析,遇到一个解决一个,不要过多的提前设计。庆幸的是这些免费小说网站的反爬虫策略都很弱,大部分没有,小部分通过降低频率和设置USER_AGENT也都解决了。
值得提出的是,数据爬取的关键是对要爬取的网站进行详细的分析,然后才是实现。
数据融合
有了爬取的数据后,就可以实现查找某本书并阅读其内容了,但是这里还有另外几个问题:
- 比如要看小说A,有多个小说网站都有这本书,但是每家的更新频率不一样,如何快速找出更新到最新的那家网站的书和相关章节信息?
- 由于都是一些免费的小说网站,有时会很不稳定甚至无法访问,如何及时的屏蔽这些无效网站的书源信息?
解决这个问题有两个思路,一个是在每次查询时进行分析和信息筛选,另一个是针对爬取的数据进行分析和融合,生成中间数据作为查询的数据。第一个方案需要在每次查询中都做一次,会影响查询的响应时间,而第二个采用异步的方法来生成中间数据,相比而言,笔者更倾向于第二个方案。实施这个方案分两步:
第一步,建立vendor信息表(vendor表示小说网站),记录某个小说网站是否有效,当前访问延迟是多少等等。在做异步融合时,首先去探测该小说网站是否可以访问以及访问延迟,并进行更新。如果人为觉得某个网站不稳定,也可以手动将其置为无效。
第二步,建立book_best_source表,记录当前时刻每本书的优选书源是什么。在做异步融合时,会遍历上述的book表,为每本书挑选出一个最佳书源和一个备用最佳书源,挑选的策略是按照三个条件进行排序:网站可访问–>该书的章节数量–>网站的访问延迟。

数据存储水平拆分
完成数据爬取和异步融合后,整个数据系统就趋于完善了。然而运行一段时间后,数据存储就暴露出问题了,出问题的是chapter这张表。按照之前的设计,chapter表用来存储所有书籍的所有章节信息,每章一条记录。随着爬取的书籍越来越多,该表也越来越大,查询的效率开始下降,并且在有一天,这张表的id不够大了(默认INT类型),导致新的数据无法写入。
针对这个问题,开始考虑对chapter表进行水平拆分,拆分的策略是按照书源来区分,即为每个小说网站的书建立不同的表来存储章节信息。拆分的工作分布在三块:
1)数据存储,即MySQL中建立新的表和数据迁移;
2)数据爬取,需要根据当前爬取的是哪家网站来选取对应的章节表进行存储;
3)Web服务,在REST API来查询时,需要根据查询的书所属的书源来查找对应的章节信息。
庆幸的是整个系统并不复杂,拆分工作很快就完成了。这件事也说明在早期进行数据库设计时,要充分考虑数据的增长速率,并作出相应的策略。
Web服务
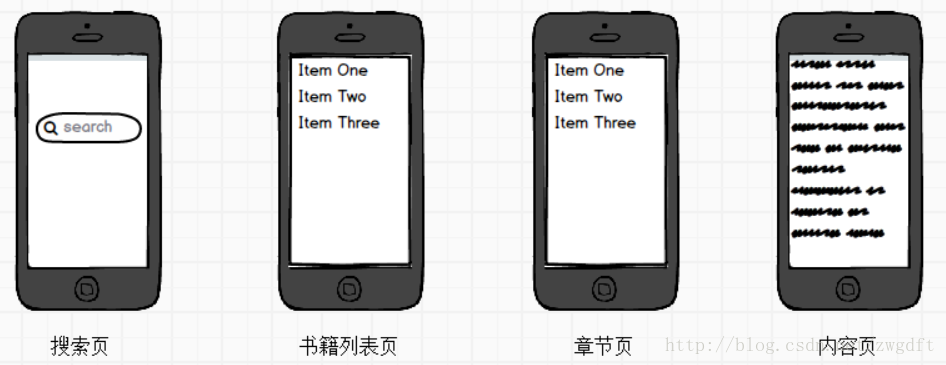
Web服务就是提供Android客户端所需要的后台服务API,采用Python Django来搭建。在该系统中,Android客户端比较简单,主要包含下面四块:
1)搜索页,通过关键词来搜索相关的书籍;
2)书籍列表页,用来显示搜索出来的书籍列表;
3)书籍章节列表页,用来显示某本书的章节列表,即目录;
4)内容页面,即用来显示某本书某章节的小说内容。
结合前端需求,需要开发两个REST API来供前端调用:
1)搜索API
GET
/api/v1/book/search/?keyword=大主宰
Response:
{
"count": 20,
"results": [
{
"id": 694077,
"name": "大主宰. ",
"author": "天蚕土豆",
"vendor": "网站1",
"cover": "",
"category": "玄幻奇幻",
"brief": "大千世界,位面交汇,万族林立,群雄荟萃..."
}
]
}2)根据某本书的id,获取其章节信息
GET
/api/v1/book/694077/chapters/
Response:
{
"count": 70,
"results": [
{
"name": "大主宰.",
"link": "http://www.example.com/20296/779515.html",
"id": 97416937
},
{
"name": "第一章 北灵院",
"link": "http://www.exapmle.com/20296/779516.html",
"id": 97416938
}
]
}整个系统设计大致如上所述,当然中间还有很多细节,比如开发中间出现阿里云的磁盘空间不够用,导致MySQL数据无法写入等等。由于只是把它当做个人项目来锻炼,利用业余时间来做,系统的实现历时近半年,到目前为止,系统已接近完成,运行也相对稳定。如前文所诉,后面还将另开一文来聊一聊期间搜索的事情。
(全文完,本文地址:http://blog.csdn.net/zwgdft/article/details/75209434)
Bruce,2017/08/26