卷积神经网络Step by Step(一)
这第一篇博客先从理论的角度阐述卷积神经网络的原理,包括卷积特征提取、池化以及误差反向传播。博客的内容是根据对Stanford大学的“UFLDL Tutorial”进行学习,并结合自己的理解所成,欢迎拍砖。
1. 用“卷积”进行特征提取
利用自然图像中的统计特征不变性,我们可以对图像的某一部分进行特征学习,然后通过卷积处理的形式应用到图像的其他部分做特征激活(feature activation)。
举例:假设对于一个96×96的图像,首先我们已经完成了对某个8×8图像块的特征学习,接下来将图像上的每个8×8的区域(1,1),(1,2),…(89,89),用相同的特征提取器分别进行特征激活,最终得到卷积特征。对于用来做特征提取或者特征学习,比较常见的是autoencoder。
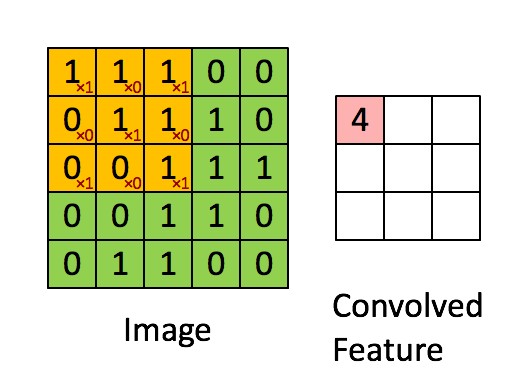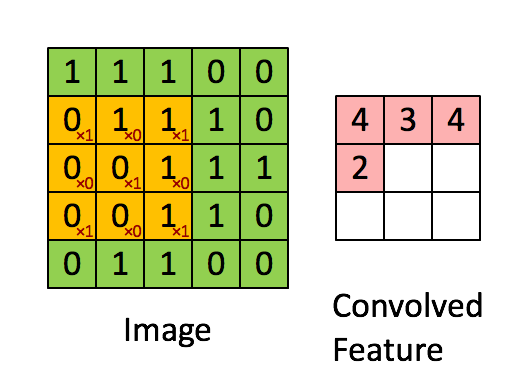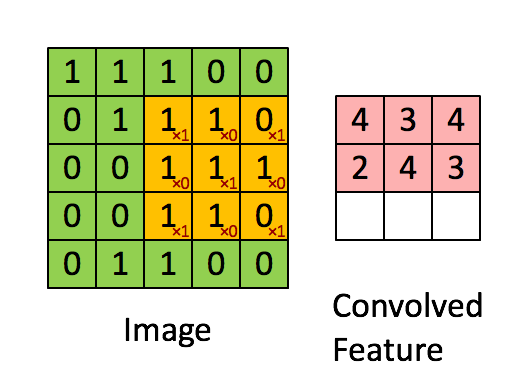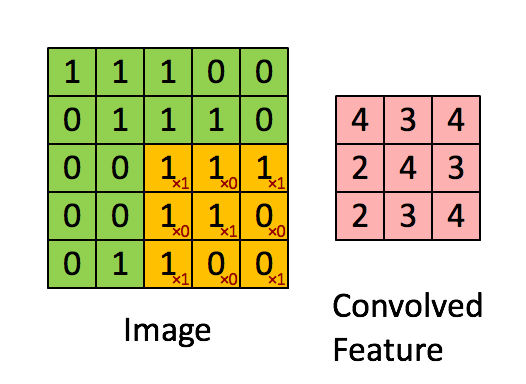
一般来讲,对于一个维数为
2. 池化
2.1 概览
通过前一节的处理,我们在原始图像上获得了“卷积处理”后的特征,接下来应该是将这些特征送入一个softmax分类器进行训练,但是考虑到特征的数量巨大(例如,对于
为了解决这个问题,我们引入“池化”的概念进行特征聚合。对于“卷积处理”后的二维特征图像,我们可以分区域进行求平均/求最大值操作,这样得到的统计特征的维数相比于之前的全“卷积”特征会大大降低,同时也会避免过拟合。“池化”一般采用的方法有“平均值池化”和“最大值池化”。
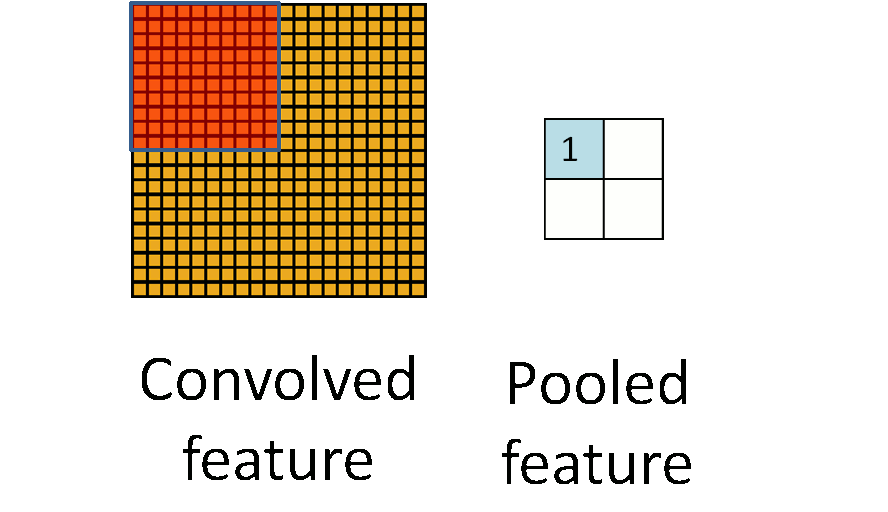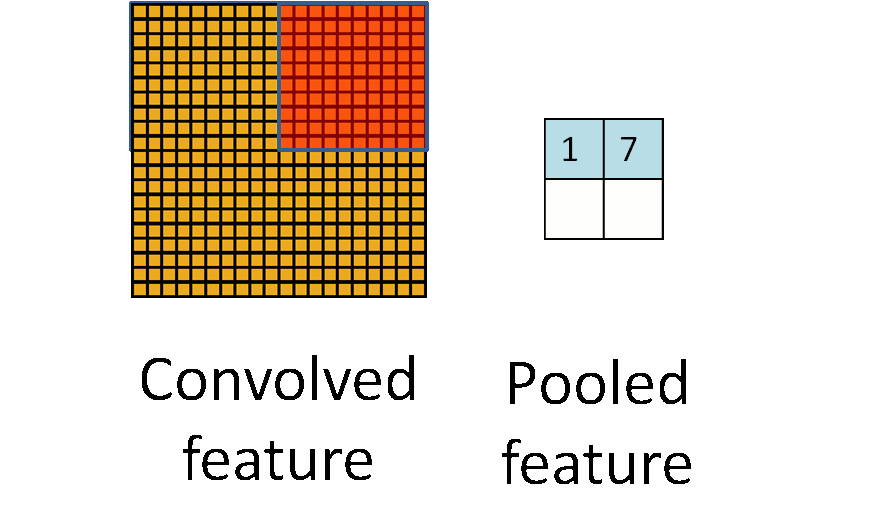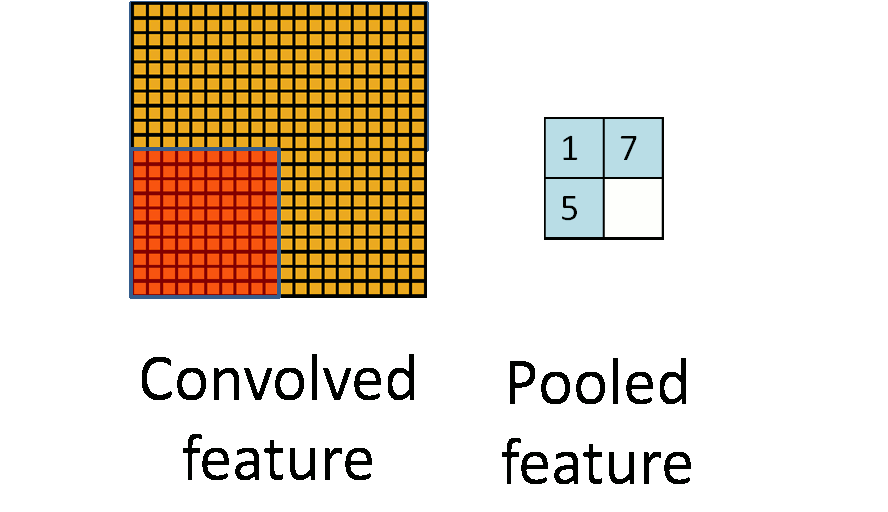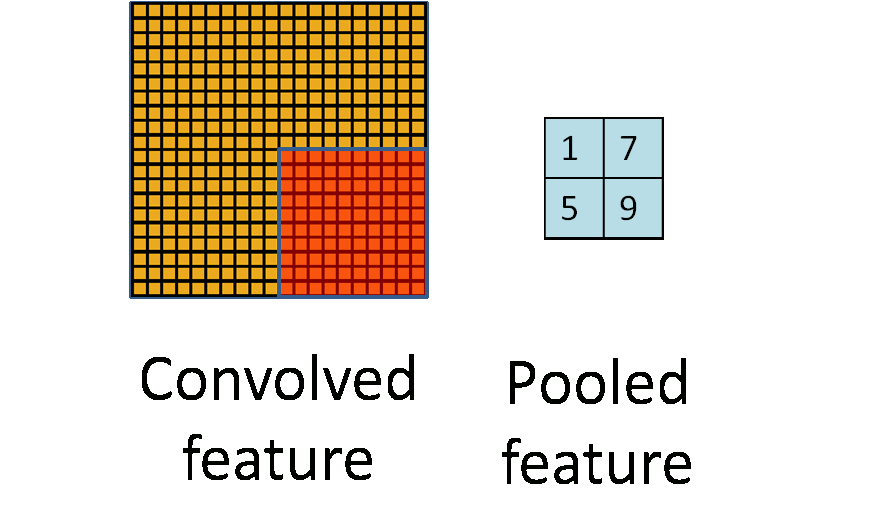
2.2 池化不变性
如果我们选择图像中的连续范围作为池化区域,并且只是池化相同(重复)的隐层单元(hidden units)产生的特征,那么,这些池化单元就具有平移不变性 (translation invariant)。这意思是指,图像整体上发生了平移一样能提取特征进行匹配。在知乎上有一个很形象的例子来解释池化的平移不变性:把近视眼镜摘了以后,我依然能够挑中菜里的肉。池化操作对于图像的一个例子可以见下图。

无论是“最大值池化”还是“平均值池化”都是在提取区域特征,相当于一种抽象,抽象就是过滤掉了不必要的信息(当然也会损失信息细节),所以在抽象层次上可以进行更好的识别。
3. 卷积神经网络
3.1 概述
一个卷积神经网络是由一个或多个卷积层,下采样层,以及一个或多个全连接层组成。CNN(卷积神经网络)的结构很适合做二维结构的信号处理,譬如说图像信号或者语音信号。CNN的优点在于很容易训练,并且相较于有相同隐层单元的全连接网络来说有更少的参数。
3.2 网络结构
以输入卷积层的图像为
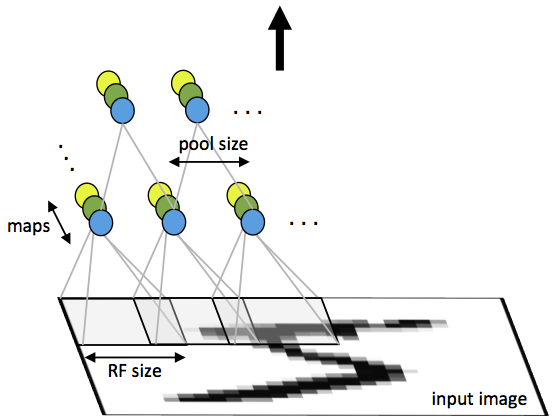
3.3 反向传播
设
同时梯度计算为:
如果第
其中
最后,要计算在特征映射上的梯度值,按照以下公式来进行计算:
其中
参考文献
http://ufldl.stanford.edu/tutorial/supervised
https://www.zhihu.com/question/34898241