现在大多数推荐系统均采用协同过滤(或协作过滤)算法进行推荐。
相似性度量
在对比每个人之间在品味方面的相似程度,一般通过计算相似度评价值。在书中给出了2中评价体系:欧氏距离和pearson相关度。
欧氏距离:即两点间的距离!
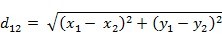
pearson相关度:判断两组数据与某一直线的拟合程度(两组数据变化移动的趋势)。该直线尽可能地靠近所有数据所对应的坐标点,也称最佳拟合直线。基本计算公式如下图:
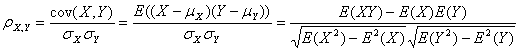


pearson系数经常用于基于user-based的协同过滤系统
(以下转自:http://blog.csdn.net/hxxiaopei/article/details/7695740
user-based:考虑相同爱好的用户兴趣,推荐这些用户喜欢/访问过的item,和用户当前的行为关系不大,更多的是用户的这些朋友访问过什么,属于圈子的社会化行为,推荐的item是相同爱好用户最喜欢的item,所以具备热点效应,也就是推荐圈子用户访问最多的;同时也可以将圈子用户刚刚访问item推荐出来,具备很强的实时性,尤其是新引入的热点,可以很快的扩散,也能解决new-item的冷启动问题。
item-based 主要考虑用户历史兴趣,推荐与用户历史喜欢item相似的item,和用户的当前行为有很大的关系,推荐的item与用户当前click的相似性,用户是可以理解的,也就是所谓的可解释性很强,推荐的item也不是热门的,很有可能是冷门(长尾),但是和用户的兴趣相关,要求用户在这个网站上的兴趣是长久和固定的,推荐的意义在于帮助用户找到和其兴趣相关的item。推荐item和是哪个用户关系不大,所以比较好的解决新加入用户的问题)
基于user-based推荐物品(如电影)
总体思路:根据影片评分计算用户间的相似度,为用户推荐时,通过加权的平均值为影片打分,对评论者的评分结果进行排序,即可得到推荐影片列表。
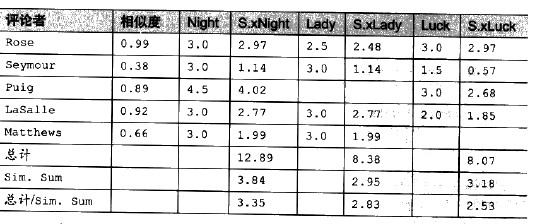
第4/6/8列为相关度评价值(相似度与该影片评分的乘积)
总计表示加权评价值总和
考虑到利用总计值来进行排名,评论较多的电影会对结果产生更大的影响,因此加入对该电影的评论者的相似度之和(Sim.Sum)进行归一化处理
基于item-based推荐电影
总体思路:为每件物品计算好最为相近的其他物品,即物品相似度,为用户推荐时,查看其曾经评分的物品,从中选出排位靠前者,进而构造一包含相近物品的加权列表。
基于user-based数据集形式为(user,item),对该数据进行转置即可得到item-based数据集。
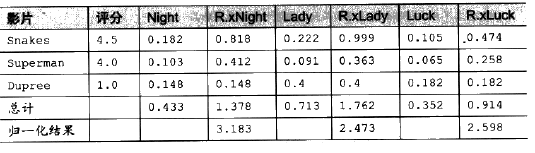
表格一行代表曾观看的影片,以及对该电影的评价,每一列为未曾看过的影片与已看影片的相似程度,R.x等表示相似度评价值(评分*相似度)。通过对相似度评价值进行归一化处理进行排序,即可得到影片推荐列表。
选择user-based还是item-based
对于稀疏数据集,item-based优于user-based。密集型数据,二者效果相似。
user-based相比于item-based方法更易于实现。