前言
在控制决策领域里面强化学习还是占很重比例的,最近出了几篇角色控制的论文需要研究,其中部分涉及到强化学习,都有开源,有兴趣可以点开看看:
A Deep Learning Framework For Character Motion Synthesis and Editing
Phase-Functioned Neural Networks for Character Control
Terrain-Adaptive Locomotion Skills Using Deep Reinforcement Learning
DeepLoco: Dynamic Locomotion Skills Using Hierarchical Deep Reinforcement Learning
DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
为了看懂这些文章,还是得对强化学习做一个基本了解,看文章的时候再去针对具体的方法作深入了解,这里就先看看最基本的Q-learning,其实在强化学习中有一个很重要的理论知识叫做马尔科夫决策过程(Markov Decision Process,MDP),建议没事的时候看看
Markov Decision Processes
而Q-learnging就是解决马尔科夫决策问题的一个方法,参考博文:
增强学习入门之Q-Learning
走近流行强化学习算法:最优Q-Learning
如何用简单例子讲解 Q - learning 的具体过程?
理论
在学习马尔科夫链的时候,我有一篇译文《马尔科夫链和马尔科夫链蒙特卡洛方法》中提到了对于马尔科夫链,存在唯一的一个稳态分布,也就是说当马尔科夫链达到稳态分布以后,其后得到的所有转移状态都具有相同的概率分布。而Q-learning的最终目的就是利用价值迭代算法寻找最优稳态(策略)。
通俗点将Q-learning的根本目的就是寻找在某种状态下采取某种策略得到的价值是多少,比如踩雷,在某个格子,我标雷或者点开,如果炸了,就惩罚,如果没炸就奖励
类似于隐马尔科夫模型(HMM),我们也需要提前知道一些变量,以扫雷为例:
- S:状态,当前在哪个格子上
- A:行为,对当前格子标雷还是踩下去
- r:长期奖励和短期奖励的折扣因子,短期奖励就是说炸了我就扣分扣到你怀疑人生,长期奖励就是价值函数,即根据以往经验,我去下一个格子标雷或者踩下去是个啥情况
- P:状态转移矩阵,维度是[行为*状态],与HMM不同的是,Qlearning是依据状态转移和采取的行动得到下一个状态,即当前格子选择完处理行为后,下一个格子我会去哪里踩
- R:短期奖励
最终目的:
- Q:价值函数
更新价值函数的迭代流程:
- 初始化当前状态:踩到哪个格子了
- 在当前状态下采取哪个行动(标雷,踩下去)
- 计算每种行动获得的反馈,计算哪个行动得到最大的价值
- 根据状态转移矩阵得到下一次我可能去探雷的位置,重复2和3步骤
其中最主要的是怎么获取行动反馈,答案就是一句长期奖励和短期奖励,大概意思就是以下两项的和:
- 短期奖励:R[当前状态][当前行为]
- 长期奖励:折扣因子* 依据当前状态和行为转移到下一个状态后再采取的所有可能行为中依据以往经验能得到的最大奖励,即
然后根据这个最大奖励更新Q[当前状态][当前行为]
其实这部分为看到了好几种更新方法: - 莫凡Python上面的

你没看错,理论到此结束,最主要的就是如何依据短期利益和长期利益去确定当前状态下采取行动所获得的最大奖励。
-
知乎上@牛阿的回答
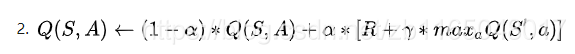
-
参考博客1的方法
-
参考博客2的方法更奇怪,这里就不贴了额,有兴趣自己去看看
不过所有的代码意思几乎都是在长远利益中选择最大值,但是长远利益的计算方法有所不同,最后更新方法也有点区别
伪代码实现:
state=1;//把踩雷游戏的最左上角的格子当做初始状态
while !finish_game:
action=random(0,1);//0是标记雷,1是踩下去
next_state=P[state][action];//依据当前状态和行为得到下一个位置
for next_action in [0,1]//踩雷和标雷都计算
temp_reward[next_state][next_action]=Q[next_state][next_action]
Q[state][action]=(1-a)*Q[state][aciton]+a*[R+max(temp_reward[nextstate][:])]
貌似看着不难,后面找个啥例子再深入了解一波。
后记
这里就是初步接触强化学习,了解何为行为与奖励,这里有一个愤怒小鸟的强化学习代码,有兴趣去玩玩:
https://github.com/SarvagyaVaish/FlappyBirdRL