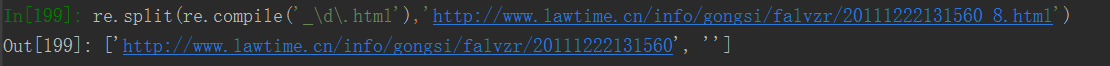问题:
若想把翻页网址'http://www.lawtime.cn/info/gongsi/falvzr/20111222131560_8.html'进行还原为'http://www.lawtime.cn/info/gongsi/falvzr/20111222131560'可以从以下三个角度进行,即直接匹配字符串,替换获得字符串,拆分获得字符串。
解答:
1.直接匹配字符串
re模块里用来匹配特定字符串的方法有三种,分别是match,search,findall。但三者的作用存在差异。
三者的区别:match和search是匹配一次,findall匹配所有。语法上也稍有不同,下面会列出。
re.match(pattern,string,flags=0) #返回一个匹配的对象
re.search(pattern,string,flags=0) #扫描整个字符串并返回第一个成功的匹配,返回一个匹配的对象
pattern.findall(string[,pos[,endpos]]) ##在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。要获取的表达式,match和search要用group或groups来获取。如:

此时,用到了compile函数,re.compile()用于编译正则表达式,根据一个模式字符串和可选的标志参数来生成一个正则表达式(Pattern)对象。
2.通过替换获得字符串
re.sub(pattern,repl,string,count=0) #替换字符串中的匹配项,其中count表示模式匹配后替换的最大次数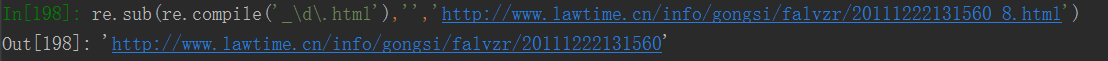
扫描二维码关注公众号,回复:
3757852 查看本文章

3.拆分获得字符串
re.split(pattern,string[,maxsplit=0,flags=0]) #按照能匹配的子串将字符串分割后返回列表。maxsplit即分割次数。