一. 简介
Apache Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。可以让用户在不了解分布式底层细节的情况下,开发出可靠、可扩展的分布式计算应用。
Apache Hadoop 框架,允许用户使用简单的编程模型来实现计算机集群的大型数据集的分布式处理。它的目的是支持从单一服务器到上千台机器的扩展,充分利用了每台机器所提供本地计算和存储,而不是依靠硬件来提供高可用性。其本身被设计成在应用层检测和处理故障的库,对于计算机集群来说,其中每台机器的顶层都被设计成可以容错的,以便提供一个高度可用的服务。
Apache Hadoop 的框架最核心的设计就是:HDFS 和 MapReduce。HDFS 为海量的数据提供了存储,而 MapReduce 则为海量的数据提供了计算。
我是通过log4j将日志传递给Flume,最终写入HDFS保存。
二. Linux环境搭建
集群配置参考:http://www.cnblogs.com/shishanyuan/p/4147580.html
我这里就只写一下单机版的配置
2.1. 下载VMWare安装虚拟机
我在使用VMWare的时候遇到过几个问题:
2.1.1. 报错"Intel VT-x…":
原因是笔记本没有开启虚拟机功能选项,重启笔记本T430i,然后按住F1键,进入BIOS设置,找到Virtual选项,设置成enable,然后保存退出。
2.1.2. 报错"无法连接MKS:套接字连接尝试次数太多,正在放弃":
“我的电脑”->“管理”->“服务和应用程序”->“服务”
开启以下服务:
VMware Authorization Service
VMware DHCP Service
VMware NAT Service
VMware USB Arbitration Service
VMware Workstation Server
2.1.3. 移动虚拟机所在位置
默认是安装在C盘我的文档下面的Virtual Machines目录
将它移到你想放的位置,比如D盘
在VMWare中删除虚拟机,然后选择打开虚拟机,选中指定的虚拟机文件即可
2.2. 在VMWare下安装CentOS7
在安装系统的时候,创建Hadoop用户(用户名:hadoop,密码:hadoop)。
也可以在安装完成后,用root用户通过命令创建:
useradd hadoop2.3. 设置机器名:
以root用户登录,使用
vi /etc/sysconfig/network打开配置文件,根据实际情况设置该服务器的机器名,新机器名在重启后生效
2.4. 设置Host映射文件:
vi /etc/hosts
2.5. 使用如下命令对网络设置进行重启:
/etc/init.d/network restart2.6. 验证设置是否成功:
ping hadoop2.7. 关闭防火墙:
在Hadoop安装过程中需要关闭防火墙和SElinux,否则会出现异常
(1)查看防火墙状态,如下所示表示iptables已经关闭
service iptables status (2)以root用户使用如下命令关闭iptables
chkconfig iptables off(3)关闭SElinux
使用getenforce命令查看是否关闭
修改/etc/selinux/config 文件
将SELINUX=enforcing改为SELINUX=disabled,执行该命令后重启机器生效

2.8. JDK安装及配置:
(1)下载jdk1.8.0_172的tar包
(2)赋予hadoop用户/usr/lib/java目录可读写权限,使用命令如下:
sudo chmod -R 777 /usr/lib/java(3)把下载的安装包,使用ssh工具上传到/usr/lib/java 目录下,使用如下命令进行解压
tar -zxvf jdk-8u172-linux-x64.tar.gz解压后目录如下图所示:

(4)使用root用户配置 /etc/profile,该设置对所有用户均生效
vi /etc/profileexport JAVA_HOME=/usr/lib/java/jdk1.8.0_172
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

(5)重新登录并验证
logout
java -version
(6)C自带的OpenSSL存在bug,如果不更新OpenSSL在Ambari部署过程会出现无法通过SSH连接节点,使用如下命令进行更新
yum update openssl2.9. SSH无密码验证配置
(1) 以root用户使用
vi /etc/ssh/sshd_config打开sshd_config配置文件,开放三个配置,如下图所示:
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys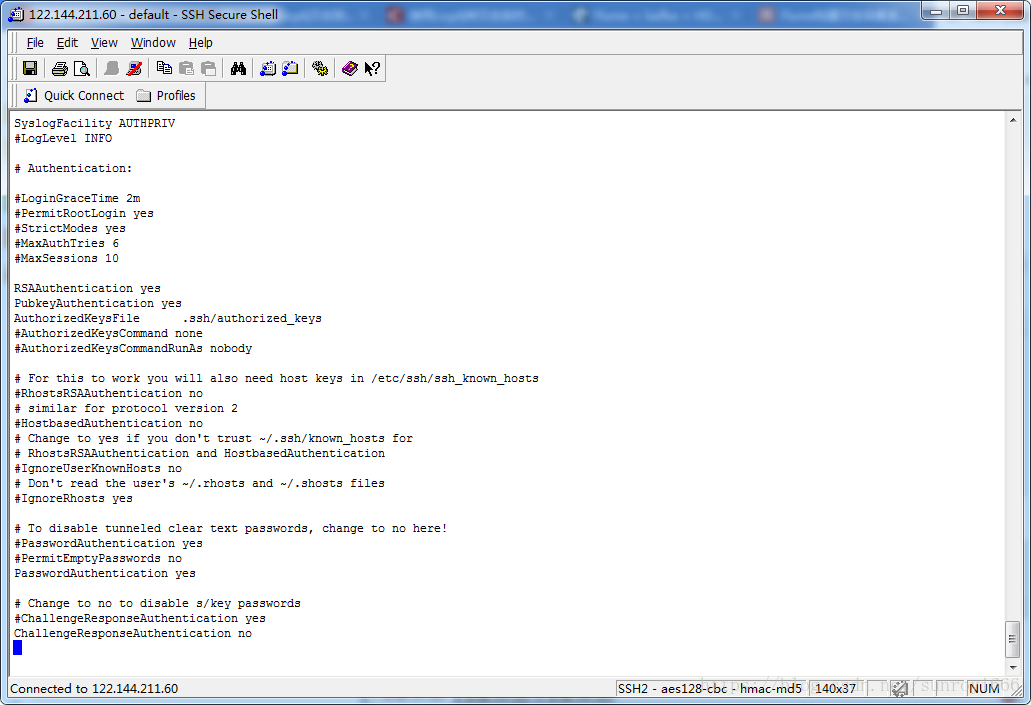
(2)配置后重启服务
service sshd restart(3)使用hadoop用户登录在三个节点中使用如下命令生成私钥和公钥
ssh-keygen -t rsa(4)进入/home/hadoop/.ssh目录(这时候还没有authorized_keys)

(5)把公钥命名为authorized_keys,使用命令如下:
cp id_rsa.pub authorized_keys(6)设置authorized_keys读写权限
chmod 400 authorized_keys(7)测试ssh免密码登录是否生效
三. Hadoop环境配置
3.1. 下载并解压hadoop安装包
(1)把下载的hadoop-2.9.1.tar.gz安装包,使用ssh工具上传到/home/hadoop/Downloads 目录下
(2)解压后转移到/usr/local目录下
(3)使用chown命令修改目录所有者为hadoop
sudo chown -R hadoop /usr/local/hadoop-2.9.13.2. hadoop的各种配置:
(1)创建子目录
mkdir tmp
mkdir hdfs
mkdir hdfs/name
mkdir hdfs/data(2)配置hadoop-env.sh
hadoop的配置文件都在etc/hadoop下:

vi hadoop-env.sh加入配置内容,设置hadoop中jdk和hadoop/bin路径
export JAVA_HOME=/usr/lib/java/jdk1.8.0_172
export PATH=$PATH:/usr/local/hadoop-2.9.1/bin

编译配置文件hadoop-env.sh,并确认生效
source hadoop-env.sh
hadoop version
(3)配置core-site.xml
vi core-site.xml<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.9.1/tmp</value>
</property>
</configuration>

(4)配置hdfs-site.xml
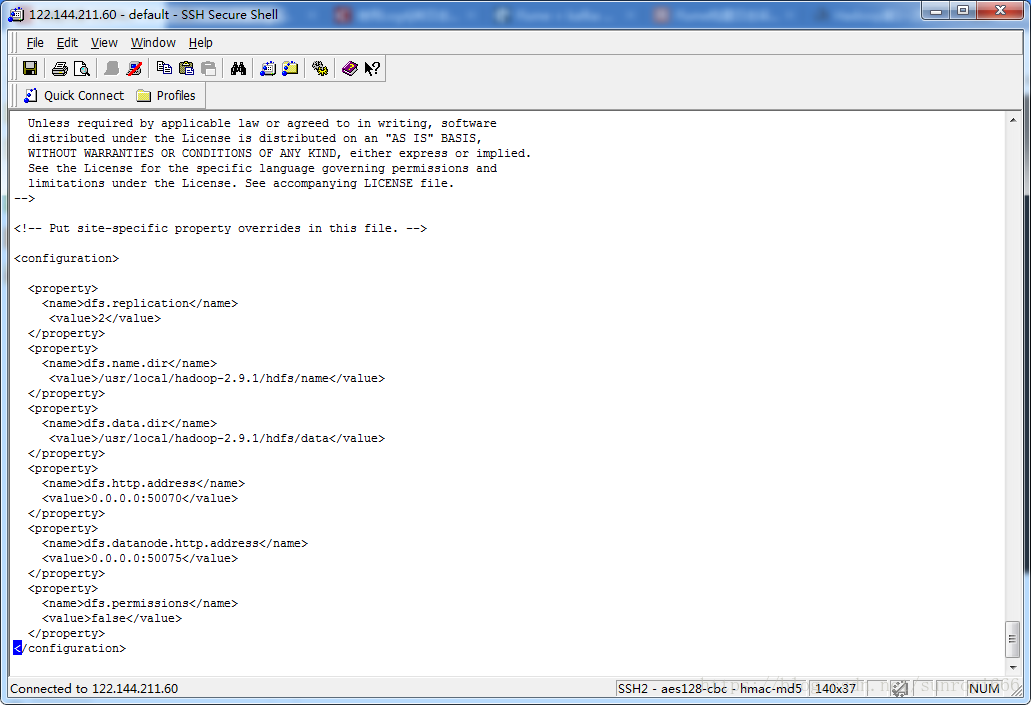
vi hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop-2.9.1/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop-2.9.1/hdfs/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50075</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
(5)配置mapred-site.xml
vi mapred-site.xml<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop:9001</value>
</property>
<property>
<name>mapred.job.tracker.http.address</name>
<value>0.0.0.0:50030</value>
</property>
<property>
<name>mapred.task.tracker.http.address</name>
<value>hadoop:50060</value>
</property>
</configuration>

(6)配置masters和slaves文件
vi mastershadoop
vi slaveshadoop
(7)格式化namenode
cd /usr/local/hadoop-2.9.1/bin
./hadoop namenode -format
3.3. 启动hadoop:
cd /usr/local/hadoop-2.9.1/sbin
./start-all.sh
3.4. 验证:
使用jps命令查看hadoop的进程是否都启动了

四. Flumed的介绍和配置
4.1. Flume特点
- Flume是一个分布式的、可靠的、高可用的海量日志采集、聚合和传输的系统
- 数据流模型:Source-Channel-Sink
- 事务机制保证消息传递的可靠性
- 内置丰富插件,轻松与其他系统集成
- Java实现,优秀的系统框架设计,模块分明,易于开发
4.2. Flume原型图

4.3. Flume基本组件
- Event:消息的基本单位,有header和body组成
- Agent:JVM进程,负责将一端外部来源产生的消息转 发到另一端外部的目的地
- Source:从外部来源读入event,并写入channel
- Channel:event暂存组件,source写入后,event将会 一直保存,
- Sink:从channel读入event,并写入目的地
4.4. 下载二进制安装包
下载地址:http://flume.apache.org/download.html
4.5. 安装Flume
解压缩安装包文件,并重命名为flume
tar -zxvf apache-flume-1.8.0-bin.tar.gz
mv apache-flume-1.8.0 flume4.6. 配置环境变量
vi /etc/profile增加以下内容:
export FLUME_HOME=/usr/local/flume
export PATH=$PATH:${JAVA_HOME}/bin:${ZOOKEEPER_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${HIVE_HOME}/bin:${FLUME_HOME}/bin:${KAFKA_HOME}/bin:${HBASE_HOME}/bin:${SPARK_HOME}/bin
4.7. 配置FLume
cd /usr/local/flume/conf
vi flume-log-agent.conf
添加内容:
#name the components on this agent
flume-log-agent.sources = s1 s2
flume-log-agent.sinks = k1 k2
flume-log-agent.channels = c1 c2
# Describe/configure the source
flume-log-agent.sources.s1.type = avro
flume-log-agent.sources.s1.bind = 0.0.0.0
flume-log-agent.sources.s1.port = 44444
flume-log-agent.sources.s2.type = avro
flume-log-agent.sources.s2.bind = 0.0.0.0
flume-log-agent.sources.s2.port = 55555
# Describe the sink
flume-log-agent.sinks.k1.type = hdfs
flume-log-agent.sinks.k1.hdfs.path = hdfs://hadoop:9000/byllog
flume-log-agent.sinks.k1.hdfs.fileType = DataStream
flume-log-agent.sinks.k1.hdfs.writeFormat = TEXT
flume-log-agent.sinks.k1.hdfs.rollInterval=30
flume-log-agent.sinks.k1.hdfs.rollSize=1024
flume-log-agent.sinks.k1.hdfs.rollCount=100
flume-log-agent.sinks.k1.hdfs.idleTimeout=60
flume-log-agent.sinks.k1.hdfs.callTimeout=60000
flume-log-agent.sinks.k2.type = hdfs
flume-log-agent.sinks.k2.hdfs.path = hdfs://hadoop:9000/smphbeatslog
flume-log-agent.sinks.k2.hdfs.fileType = DataStream
flume-log-agent.sinks.k2.hdfs.writeFormat = TEXT
flume-log-agent.sinks.k2.hdfs.rollInterval=30
flume-log-agent.sinks.k2.hdfs.rollSize=1024
flume-log-agent.sinks.k2.hdfs.rollCount=100
flume-log-agent.sinks.k2.hdfs.idleTimeout=60
flume-log-agent.sinks.k2.hdfs.callTimeout=60000
# Use a channel which buffers events in memory
flume-log-agent.channels.c1.type = memory
flume-log-agent.channels.c2.type = memory
# Bind the source and sink to the channel
flume-log-agent.sources.s1.channels = c1
flume-log-agent.sinks.k1.channel = c1
flume-log-agent.sources.s2.channels = c2
flume-log-agent.sinks.k2.channel = c2
#Start Command:
#flume-ng agent --name flume-log-agent --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/flume-log-agent.conf -Dflume.root.logger=INFO,console
#
#Log File Upload Command:
#flume-ng avro-client -F /home/hadoop/test/log.txt -H hadoop1 -p 5678
我这里一个配置文件对应了两套Source-Channel-Sink,一套监听44444端口的日志,一套监听55555端口的日志。
4.8. 启动FLume
flume-ng agent --name flume-log-agent --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/flume-log-agent.conf -Dflume.root.logger=INFO,console18/01/27 18:17:25 INFO node.AbstractConfigurationProvider: Channel c1 connected to [r1, k1]
18/01/27 18:17:25 INFO node.Application: Starting new configuration:{ sourceRunners:{r1=EventDrivenSourceRunner: { source:org.apache.flume.source.NetcatSource{name:r1,state:IDLE} }} sinkRunners:{k1=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@20470f counterGroup:{ name:null counters:{} } }} channels:{c1=org.apache.flume.channel.MemoryChannel{name: c1}} }
18/01/27 18:17:25 INFO node.Application: Starting Channel c1
18/01/27 18:17:25 INFO node.Application: Waiting for channel: c1 to start. Sleeping for 500 ms
18/01/27 18:17:25 INFO instrumentation.MonitoredCounterGroup: Monitored counter group for type: CHANNEL, name: c1: Successfully registered new MBean.
18/01/27 18:17:25 INFO instrumentation.MonitoredCounterGroup: Component type: CHANNEL, name: c1 started
18/01/27 18:17:26 INFO node.Application: Starting Sink k1
18/01/27 18:17:26 INFO node.Application: Starting Source r1
18/01/27 18:17:26 INFO source.NetcatSource: Source starting
18/01/27 18:17:26 INFO source.NetcatSource: Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]4.9. 在后台运行Flume
由于我是通过ssh工具远程连接的CentOS,如果ssh工具断开,Flume进程也会被终止,所以需要将FLume设为后台进程,不受ssh远程客户端关闭的影响。
只要在Flume的启动命令前加上setid即可。
setsid flume-ng agent --name flume-log-agent --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/flume-log-agent.conf -Dflume.root.logger=INFO,console
查看flume进程:
ps -ef |grep flume
删除进程:
kill 进程id
删除端口进程:
lsof -i :44444|grep -v "PID"|awk '{print "kill -9",$2}'|sh
五. 在SpringMVC框架下进行日志记录
5.1. 创建一个maven项目,pom.xml文件中引入依赖
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
</dependency>
<!-- Flume -->
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.flume.flume-ng-clients</groupId>
<artifactId>flume-ng-log4jappender</artifactId>
<version>1.7.0</version>
</dependency>
<!-- Flume -->5.2. 添加log4j的配置文件,log4j.properties:
log4j.rootLogger=INFO,stdout,flume
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.target = System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c] [%p] - %m%n
log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname = 122.133.211.60
log4j.appender.flume.Port = 55555
log4j.appender.flume.UnsafeMode = true
5.3. 添加测试类:
package com.inesa.modules.bt.web;
import org.apache.log4j.Logger;
public class FlumeTest {
private static final Logger logger = Logger.getLogger(FlumeTest.class);
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 100; i++) {
logger.info("Info [" + i + "]");
}
}
}只要logger.info()记录的内容都会通过FLume写入HDFS中
六. 在SpringCloud框架下进行日志记录
与SpringMVC基本一样,但是pom.xml里面还需要多加一点配置。
SpringCloud的项目默认会有默认的日志记录方式和配置,只是添加log4j会不起作用,因此要把默认的日志关闭。
在<dependencies>后直接添加:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- log4j. -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j</artifactId>
</dependency>七. 结果验证
[hadoop@hadoop hadoop-2.9.1]$ hadoop fs -ls /
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2018-10-26 14:21 /byllog
drwxr-xr-x - hadoop supergroup 0 2018-10-15 16:47 /smphbeatslog
[hadoop@hadoop hadoop-2.9.1]$ hadoop fs -ls /smphbeatslog
...
-rw-r--r-- 2 hadoop supergroup 1193 2018-09-29 09:02 /smphbeatslog/FlumeData.1538182852342
-rw-r--r-- 2 hadoop supergroup 1272 2018-09-29 09:02 /smphbeatslog/FlumeData.1538182852343
-rw-r--r-- 2 hadoop supergroup 1161 2018-09-29 09:02 /smphbeatslog/FlumeData.1538182852344
-rw-r--r-- 2 hadoop supergroup 1265 2018-09-29 09:02 /smphbeatslog/FlumeData.1538182852345
-rw-r--r-- 2 hadoop supergroup 1042 2018-09-29 09:02 /smphbeatslog/FlumeData.1538182852346
[hadoop@hadoop hadoop-2.9.1]$ hadoop fs -cat /smphbeatslog/FlumeData.1538182852350
Mapped "{[/a/sys/sysLogin/sendValidateMobile],methods=[POST]}" onto public void com.thinkgem.jeesite.modules.sys.web.SysLoginController.sendValidateMobile(javax.servlet.http.HttpServletRequest,javax.servlet.http.HttpServletResponse,java.lang.String)
Mapped "{[/f/sys/sysVersion/delete],methods=[POST]}" onto public void com.thinkgem.jeesite.modules.sys.web.SysVersionController.delete(javax.servlet.http.HttpServletRequest,javax.servlet.http.HttpServletResponse,java.lang.String)
Mapped "{[/f/sys/sysVersion/save],methods=[POST]}" onto public void com.thinkgem.jeesite.modules.sys.web.SysVersionController.save(javax.servlet.http.HttpServletRequest,javax.servlet.http.HttpServletResponse,com.thinkgem.jeesite.modules.sys.entity.SysVersion)
Mapped "{[/f/sys/sysVersion/search],methods=[POST]}" onto public void com.thinkgem.jeesite.modules.sys.web.SysVersionController.search(javax.servlet.http.HttpServletRequest,javax.servlet.http.HttpServletResponse,com.thinkgem.jeesite.modules.sys.entity.SysVersion,java.lang.String,java.lang.String)
可以看到,FlumeData.1538182852350里面记录的是系统记录的日志信息。
如果自己的系统可以自定义格式,方便以后的日志分析。