构造函数
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
分析:
LinkedHashMap是HashMap的子类。那么我们就想,为啥要来个LinkedHashMap呢?这是为了解决什么问题呢?根据构造函数我们会发现有个accessOrder属性,字面意思就是有序访问,那我们很自然就会想到一个问题HashMap没法按照放入值的顺序去访问,到这里我们就知道这个LinkedHashMap就是一个可以顺序访问的HashMap。查看源码我们也知道,它是继承自HashMap,里面并没操作元素的方法,它的方法都是来自父类HashMap,这里如果你理解多态的话就非常好理解了(如果还是没有很清楚的话自行补回来吧)。
那么我们接下来看看LinkedHashMap是如何做到有序访问的,我们先来看它的属性。
属性
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
final boolean accessOrder;分析:
inkedHashMap和HashMap的区别在于它们的基本数据结构上,看一下LinkedHashMap的基本数据结构,也就是Entry。不用要搞错了next和before、After,next是用于维护HashMap指定table位置上连接的Entry的顺序的,before、After是用于维护Entry插入的先后顺序的。如果你还是不好理解,那么看看下面这张图就很容易理解了。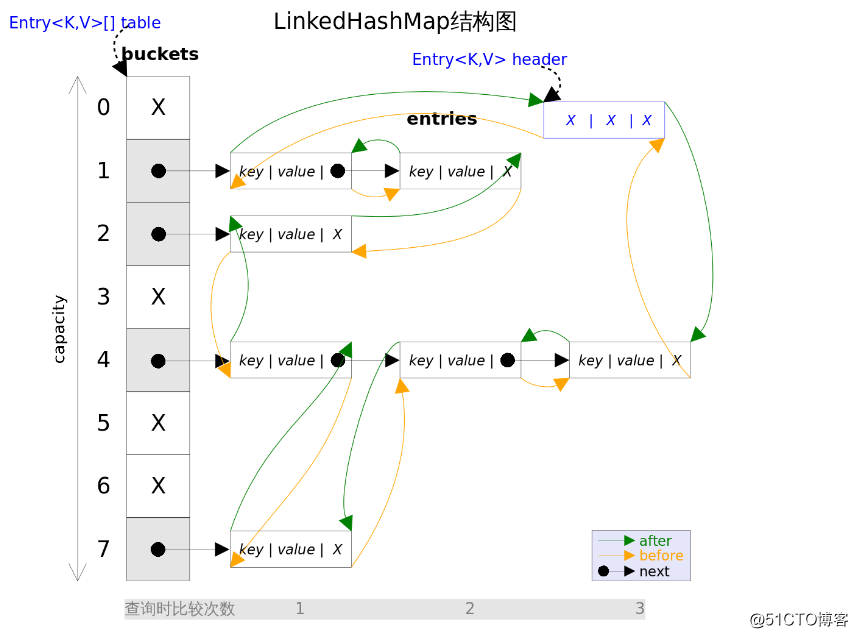
从上面看是不是感觉它有点像LinkedList和HashMap的变种,那么我们就将上面的图转化一下就更清楚了,如下: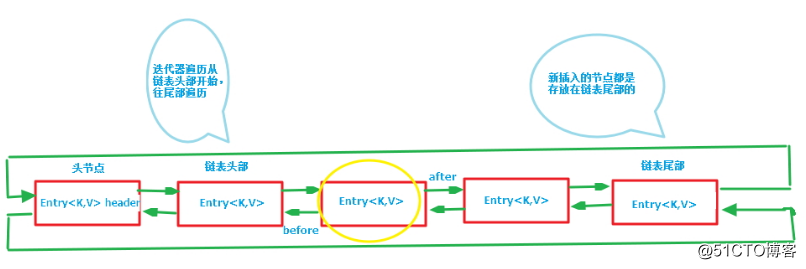
这样拍平是不是就看着更顺眼了?也更好理解了对吧。
注意该循环双向链表的头部存放的是最久访问的节点或最先插入的节点,尾部为最近访问的或最近插入的节点,迭代器遍历方向是从链表的头部开始到链表尾部结束,在链表尾部有一个空的header节点,该节点不存放key-value内容,为LinkedHashMap类的成员属性,循环双向链表的入口。
get方法
在LinkedHashMap里它重写这个方法,代码如下:
// HashMap的get方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
// LinkedHashMap的get方法
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}我们继续查看一些代码:
final class LinkedEntrySet extends AbstractSet<Map.Entry<K,V>> {
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator<Map.Entry<K,V>> iterator() {
return new LinkedEntryIterator();
}
public final boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Node<K,V> candidate = getNode(hash(key), key);
return candidate != null && candidate.equals(e);
}
public final boolean remove(Object o) {
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Object value = e.getValue();
return removeNode(hash(key), key, value, true, true) != null;
}
return false;
}
public final Spliterator<Map.Entry<K,V>> spliterator() {
return Spliterators.spliterator(this, Spliterator.SIZED |
Spliterator.ORDERED |
Spliterator.DISTINCT);
}
public final void forEach(Consumer<? super Map.Entry<K,V>> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e);
if (modCount != mc)
throw new ConcurrentModificationException();
}
}总结:
1.LinkedHashMap是继承子HashMap
2.LinkedHashMap是可以有序访问的
3.LinkedHashMap可以理解为是LinkedList和HashMap结合的产物,LinkedList维护访问次序,HashMap维护数据散列。
4.当然它不是线程安全的啦
其实这里如果看懂了这些代码对于理解java的多态是非常有帮助的。反过来,也是一样的,如果懂了多态,理解这写代码都没有啥难度。