LinkedHashMap也是循环双链表,继承自HashMap 因此调用put() 和构造器都是HashMap()的方法,但是在put()中的addEntry()中使用的是继承自HashMap中的HashMapEntry 并且又添加了两个属性由原来的单链表变成了循环的双向链表。并且这个双向链表是在init()方法中进行初始化的。这个方法在HashMap中构造器中进行调用,但是并没有实现。具体的实现方法是在LinkedHashMap中。
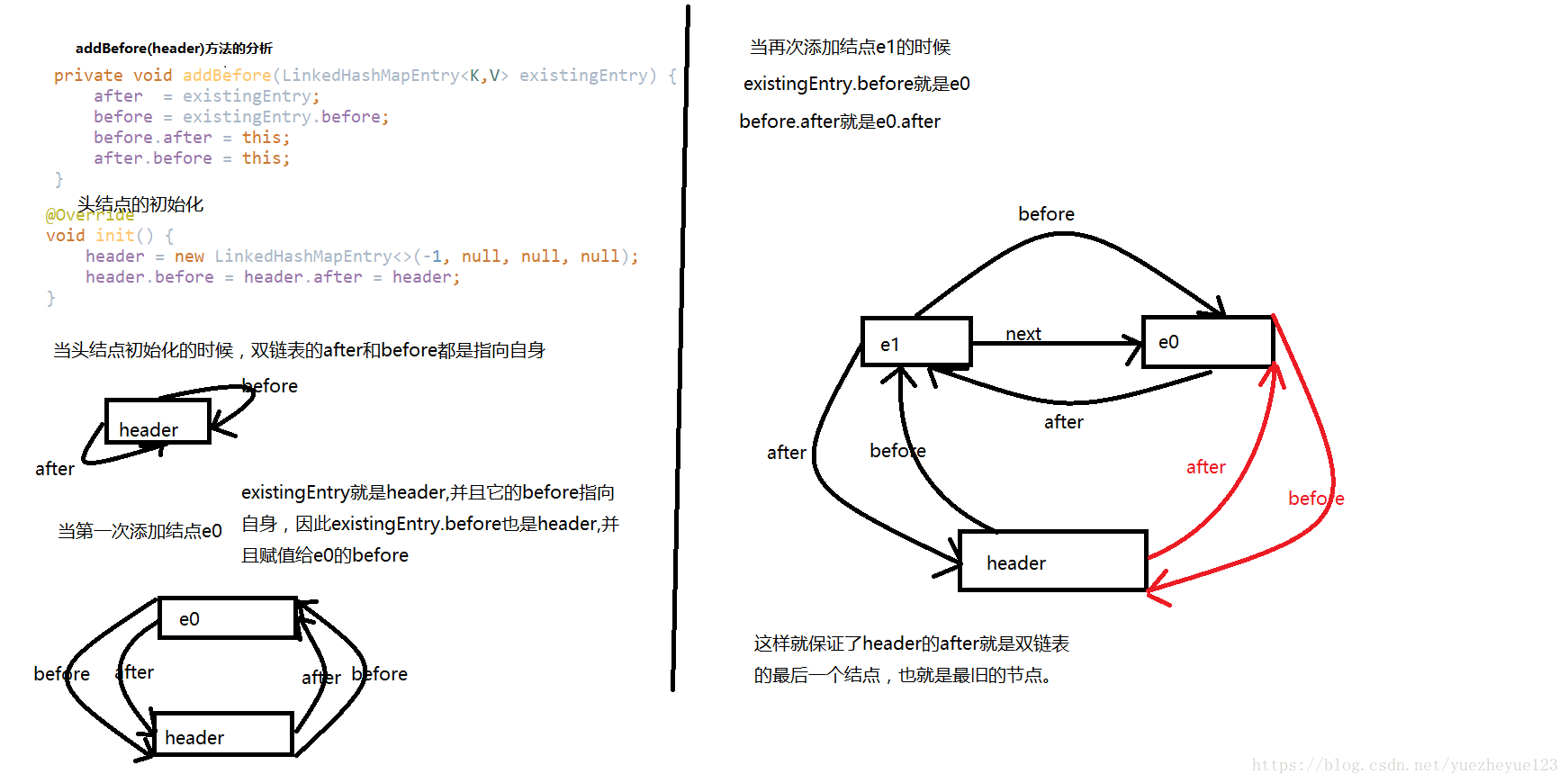
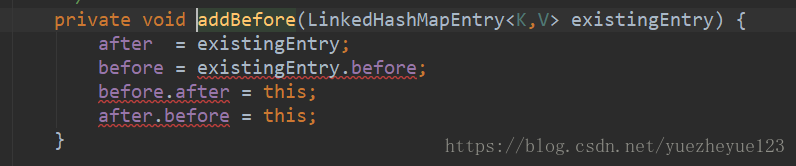
这个头节点的前驱和后继都指向自身,很明显是双向链表。并且是使用了一条循环双链表,将所有的节点都串联起来。具体的实现就是在addBefore()方法中。和HashMap的区别也在这里,HashMap中每个数组上的节点都可以是一个单链表的第一个节点,并且使用next进行关联下个节点,这样形成了多条单链表。

在LinkedHashMap中并不是使用了双链表就抛弃了数组,这里面还是维持了节点的数组,但是又维护了一个双链表,并且定义了迭代的顺序,在单线程的操作中,他是按照顺序进行存取。
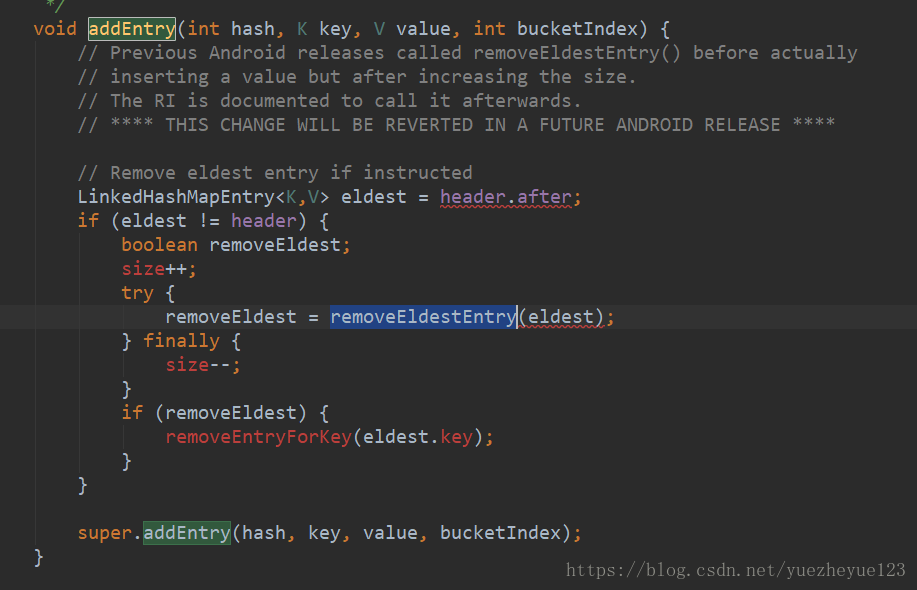
在put()方法中重写了父类HashMap中的addEntry() 和 createEntry()方法
LruCache使用了LinkedHashMap,主要是提供了删除旧元素的方法,当添加元素的时候,就会调用removeEldestEntry()方法,这个方法默认是返回false,需要重写这个方法,达到删除的目的。

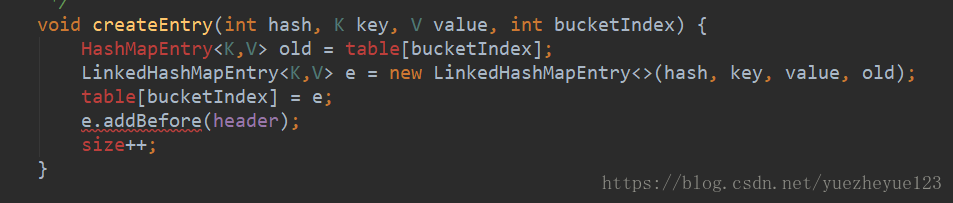
添加元素的时候,将新的元素放在数组中,并且将原有的头元素放在新元素的下一位。
当调用get()方法的时候,就会先找到这个元素,然后将这个元素从双链表中删除,并且添加到双链表的首位。但是这个调用get()方法后进行排序功能是由accessOrder属性进行配置,这个属性在调用构造器的时候,默认是设置为false,因此一般情况下并不执行。因此可以解释为什么迭代器中的数值按照存储的数据输出。
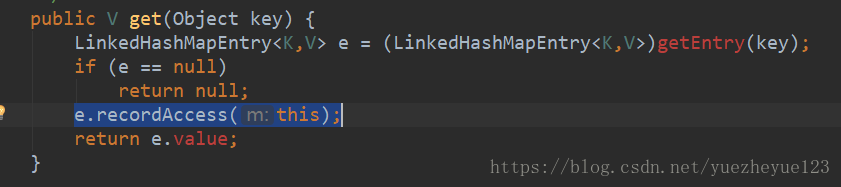
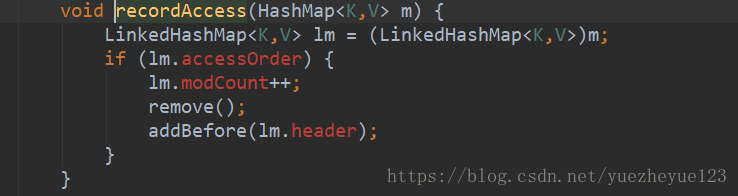
删除当前访问的节点,然后调用addBefore()方法将访问的节点进行添加
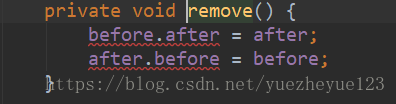
addBefore()方法的分析