对,就是十分钟,没有接触过爬虫的你,肯定一脸懵逼,感觉好高深的样子,一开始我也有点懵,但用了以后发现还是很简单的,java爬虫框架有很多,让我有种选择困难症,通过权衡比较还是感觉jsoup比较好用些,简单强大,怎么简单强大呢?看了后面你就知道了。
为什么要给大家讲一下使用jsoup呢?一是为了大家少走弯路,能快速掌握爬虫技术,不要像我一样绕了几个小时在这上面。二是如果我讲的不好或是哪里有不对的地方麻烦大家在评论区指出来,大家一起讨论讨论,就像我们公司的口号一样,帮助他人就是成就我自己。记得刚入行的时候,所在的公司是做旅游方向软件的,主要工作是开发各县区的旅游景区APP,每做一个app我就要上网找数据,录数据,作为现场竞标演示使用。那时候也蠢,只知道上网找数据,然后复制粘贴,一个景区的数据少则一天,多则一个礼拜。在这家公司工作的一年时间里,差不多有三四个月是在无脑录数据,而不是专研在技术上,现在想想就心痛,如果当时用爬虫的话,就可以省下一大笔时间了,多的时间用在技术和泡妞上不知道有多nice。所以大家应该知道掌握爬虫的重要性了吧!
大家是不是有点不耐烦了,在骂我还不进入正题,好好好,现在进入正题,我们以需求的方式去讲这次的内容吧!我的需求是这样的:爬取某网站的深圳写字楼数据,保存到我们自己的数据库,以充实我们的数据量。我们就拿点点租为例吧!首先我们进入点点租官网(http://sz.diandianzu.com/listing),如图所示:
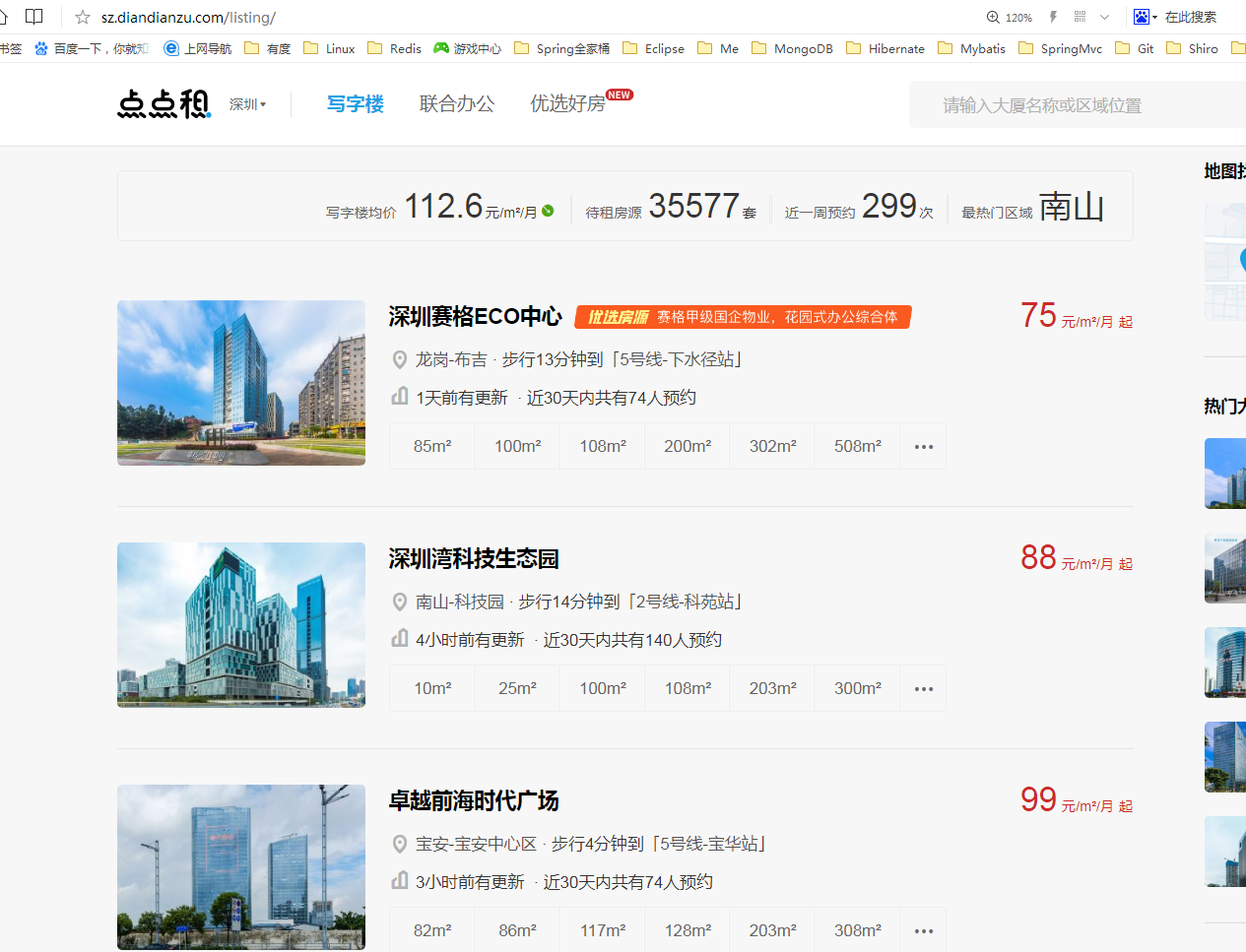
怎么才能通过jsoup爬取到所有写字楼数据呢?先剧透一点,通过Document doc = Jsoup.connect(“http://sz.diandianzu.com/listing”).get()就能获取当前页http://sz.diandianzu.com/listing的html源码,所以我们是通过源码标签,id选择器,类选择器等多种方式去找到我们所要的数据。作为一个java程序员,如果你对html一概不知的话,我真想认识认识你,这是程序员必备技能。首先我们通过伪代码的方式去实现它!爬取数据最主要的一点就是找网站规律,实现代码很简单。我们可以先花三十秒思考一下怎么才能爬取到所有深圳写字楼的数据呢?
1.我们要获取到当前页的所有楼盘id 2. 我们要获取到所有页的楼盘id 3. 通过楼盘id获取楼盘详情。你是不是也是这么想的呢?首先我们通过f12查看一下源代码,查找一下当前页的楼盘id,如图所示,我们可以很快查找到当前页所有楼盘的id,如图所示: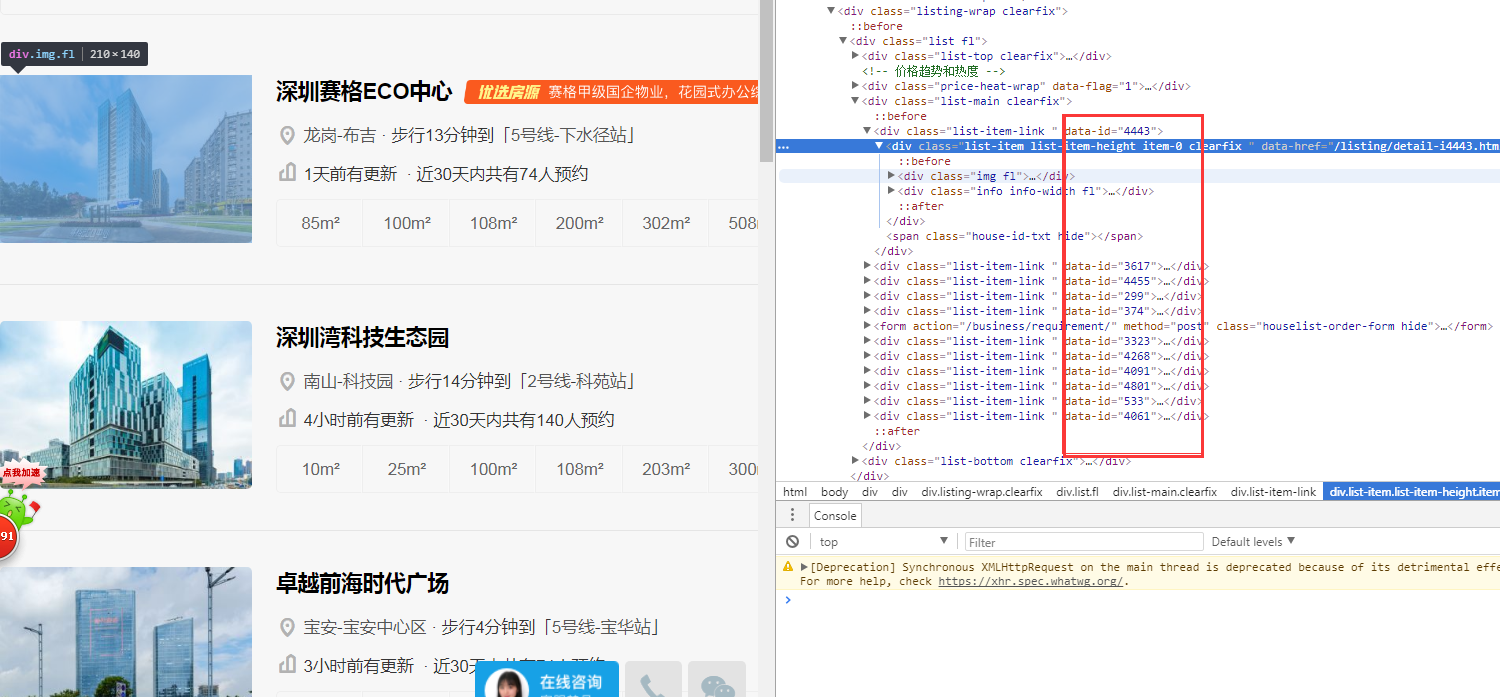
现在我们只是找到了当前页的所有楼盘id,怎么才能获取到所有页的楼盘id呢?我们先看一下第二页,如图所示:


注意看网址:http://sz.diandianzu.com/listing/p2/,你翻到第三页就是http://sz.diandianzu.com/listing/p3/,以此类推,我们知道只需要改变p后面的数值就能获取到第N的数据啦,这在代码实现上很简单,我们只要在一个循环就能读取到所有页的数据了,怎么才知道当前页是最后一页数据呢?我们可以通过比较一下有数据和没有数据的页面源码区别就知道了,代码部分后面讲。获取所有页的id规律我们知道了,怎么通过id获取当详情数据呢?我们随便点开一个楼盘的详情页,如图所示,还是重点看url部分:
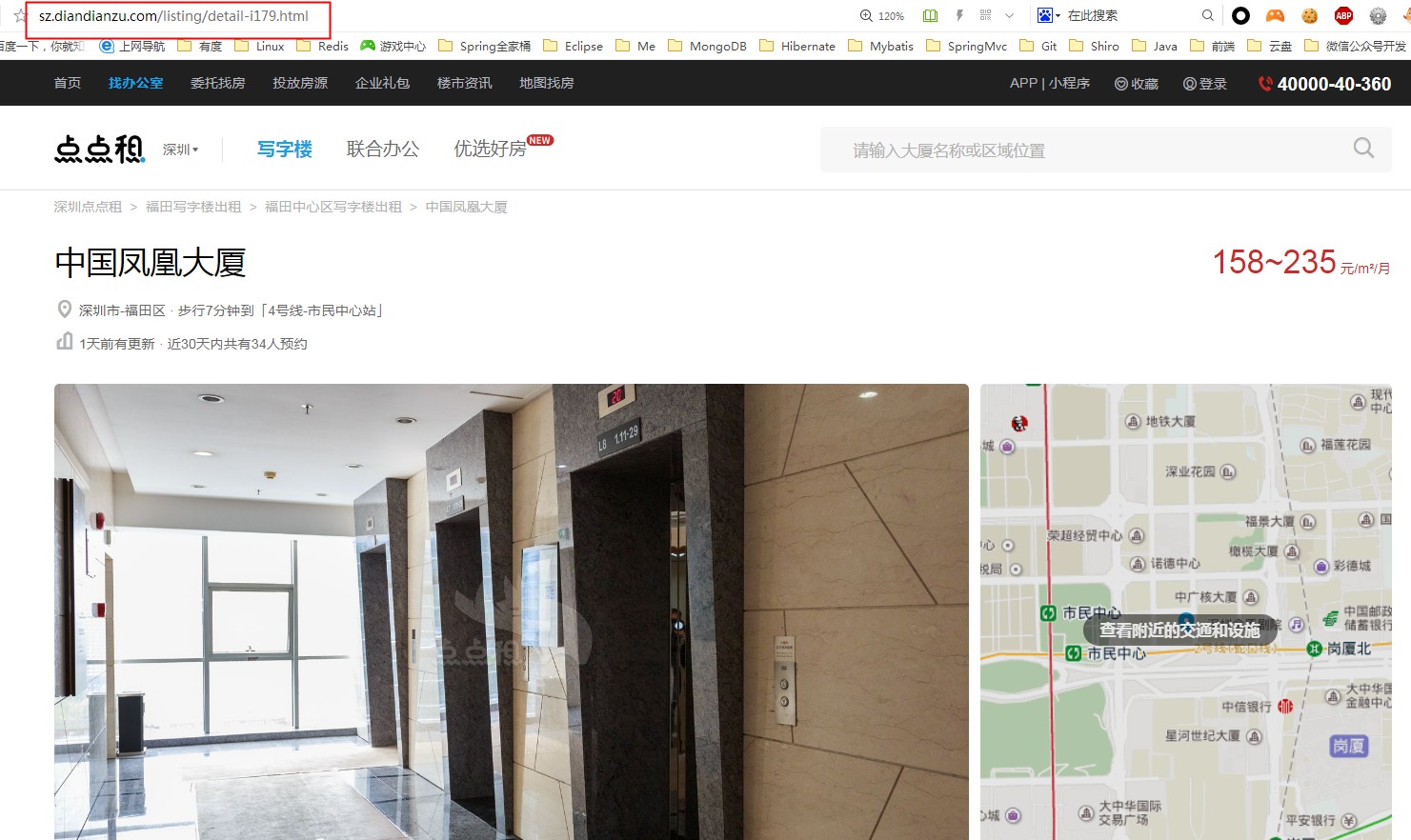
看到http://sz.diandianzu.com/listing/detail-i179.html这个url,我们再随便打开一下另外一个项目详情的url:http://sz.diandianzu.com/listing/detail-i3484.html,发现他们的区别只是i后面的数值不一样,这个179和3484是什么呢?你肯定想的到就是我们的楼盘id啦,所以通过循环楼盘id列表,然后循环解析http://sz.diandianzu.com/listing/detail-i{楼盘id}.html的方式就能获取到所有楼盘详情啦!
规律是找到了,现在我们开始简单的代码过程吧!在码代码之前,我们可以先看看jsoup的中文文档:http://www.open-open.com/jsoup/dom-navigation.htm,只需要根据文档就能轻易获取到当前页任意一段代码内容。首先我们从一个URL加载一个Document,如图所示:

我的代码也是这样的,直接在main方法中运行。别忘了先把jsoup 的jar包引入进来:
Document doc = Jsoup.connect("http://sz.diandianzu.com/listing").get();
debug以下查看doc输出内容拷贝到文本编辑器我们可看到就是当前页的html源代码,我们先找到楼盘列表这一块的div源代码,如图所示:
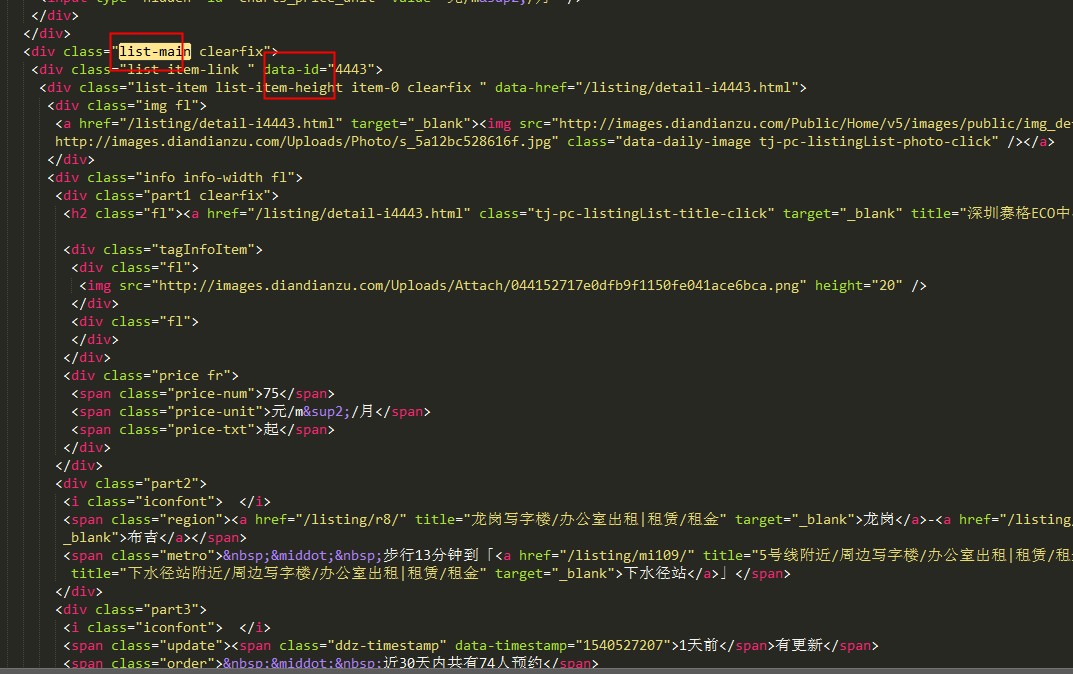
我们的楼盘数据都在class为list-main里面呢,根据jsoup文档我们通过查找元素方法:getElementsByClass(String className)定位到list-main这个div里面去,再根据使用选择器语法来查找元素Element.select(String selector),遍历div里面的data-id就能获取到所有的楼盘id了,代码如图所示:
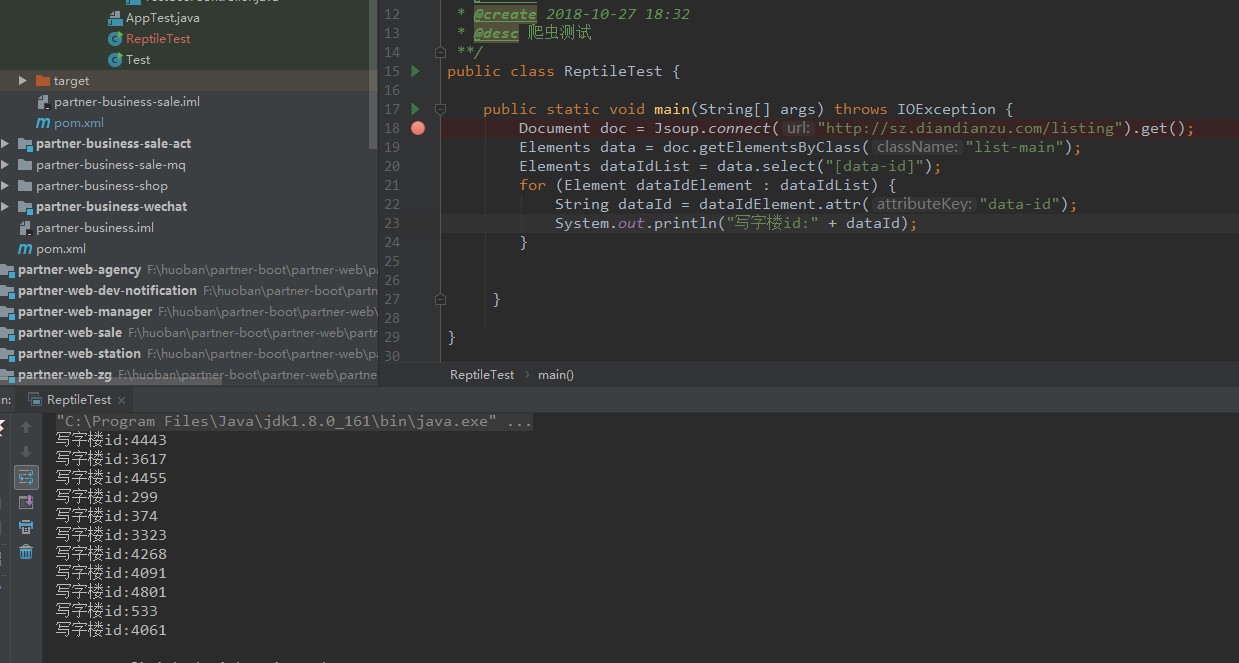
只需要根据jsoup文档就能很快获取到我们想要的元素值。怎么获取所有页面的写字楼id呢?我们改造一下这段代码,如图所示:

是不是很简单呢?但这里还有一个问题,是怎么判断是不是最后一页,是最后一页我们就得跳出循环,不然会一直查找下去,导致程序停止不了,我们查找一下没有数据的list-main跟有数据的list-main里面的源代码区别,在url输入http://sz.diandianzu.com/listing/p2000/ 看到没有楼盘数据了,如图所示:

好,我们解析一下这个页面的html源码,看一下它的代码是怎么样的?解析出来后如图所示:
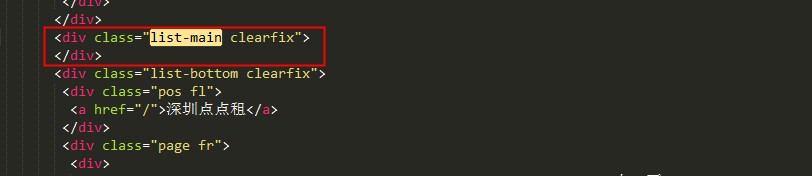
看到没有,list-main类选择这个div里面没有任何东西,所以我们只需要判断data-id这个标签值存不存在,就可以知道是不是最后一页,不存在值就直接退出,完整获取所有楼盘id的代码:
package com.zhaoshang800.boot;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* @author zhx
* @create 2018-10-27 18:32
* @desc 爬虫测试
**/
public class ReptileTest {
public static void main(String[] args) throws IOException {
try {
long startTime = System.currentTimeMillis();
List<String> buildingIdList = new ArrayList<>();
int pageNum = 0;
while (1 == 1) {
pageNum++;
try {
System.out.println("当前页:" + pageNum);
String url = "http://sz.diandianzu.com/listing/p"+pageNum;
Document doc = Jsoup.connect(url).get();
if(doc == null){
continue;
}
Elements data = doc.getElementsByClass("list-main");
Elements dataIdList = data.select("[data-id]");
if (null == dataIdList || dataIdList.size() <= 0) {
break;
}
for (Element dataIdElement : dataIdList) {
String dataId = dataIdElement.attr("data-id");
System.out.println("写字楼id:" + dataId);
buildingIdList.add(dataId);
}
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("一共有写字楼"+buildingIdList.size());
long endTime = System.currentTimeMillis();
System.out.println("获取楼盘id一共用时"+(endTime - startTime)/1000+"秒");
} catch (Exception e) {
e.printStackTrace();
}
}
把我这段代码复制过去直接运行main方法就可以打印出所有的楼盘id了,如图所示:

是不是很简单,后面的获取所有楼盘详情想必大家应该知道怎么做了吧?留给大家自己动手去做吧,如果还有疑问的或是有什么指教的话,可以在评论区联系我,我会第一时间一一答复。