hadoop:
hdfs集群:负责文件读写
yarn集群:负责为mapreduce程序分配运算硬件资源
name node 本身的地位是很重要的,它记录了用户上传的文件分别在哪些dat node 上,记录了这些文件的元信息.所以它叫名称节点,记录了文件的名称和实际对应的物理地址.它如果挂掉了,那么客户端是无法知道这些文件在哪台机器上的,所以name node 是很重要的,所以这个是单独一台机器的.
在做MAPREDUCE运算的时候,是靠yarn来运行的,yarn的老大也很重要,老大 resource manager 挂了话,那么就没人去管资源调度了.所以resource manager 也单独放一台机器.
其他的data node 跟 node manager 是应该放在一起的,如果data node 跟node manager是分开的,那么客户端发送一个mapreduce程序运行,是在node manager上运行,那么需要去读取hdfs文件系统上的数据,那么就得走网络文件传输了.这个时候会很慢.
但是在学习的时候,我们为了节省一点机器,就将 name node 跟 resource manager 放在同一台机器上.它们两个工作的端口是不同的,所以是不影响的.
1.首先需要新建一个用户 hadoop, 用来统一操作hadoop
useradd hadoop
设置密码:
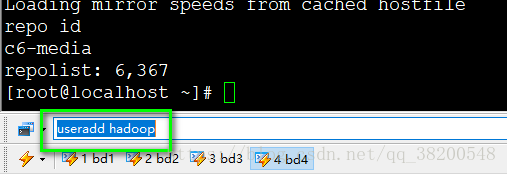
passwd hadoop
设置好了hadoop用户之后,把连接全部退掉,然后重新以hadoop的身份进行连接.
2.查看是否每台机器都安装好了jdk
使用命令 java -version 统一查看:
如果没有的话,假设bd4-hadoop这台机器上没有安装jdk
可以选择其他的任一一台安装了的机器使用scp进行传输
在bd1-hadoop上:
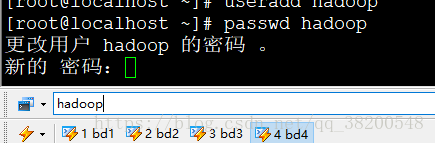
echo $JAVA_HOME
查看jdk的安装路径:
然后复制给bd4-haoop:
sudo scp -r /usr/local/jdk1.7.0_745 bd4:/usr/local
使用scp需要输入密码
如果没有配置 sudo 则可以先使用 su 切换到root用户,使用scp复制jdk.
然后在bd4-hadoop 配置 /etc/profile:
在后面追加
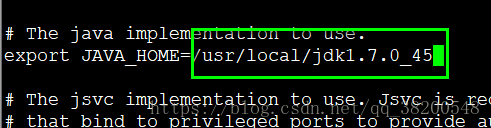
export JAVA_HOME=/usr/local/jdk1.7.0_45
export PATH=$PATH:$JAVA_HOME/bin
然后使用 source /etc/profile 使之生效
需要注意的是此时使用spurce 需要在hadoop用户下,如果只是在root用户下进行source,那么hadoop用户下是不会生效的
3.为了便于使用root用户的权限,我们可以配置sudo
3.1现在一台机器上进行配置,然后scp到其他的机器上:
配置之前要先切换到 root用户下,使用 su 进行切换
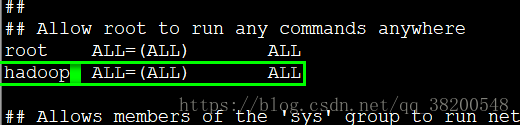
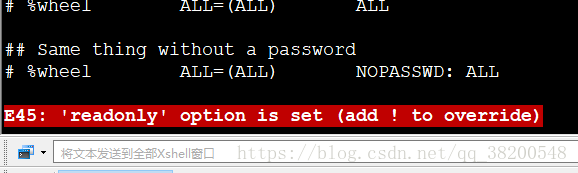
vi /etc/sudoers
yy p 复制 root ALL=(ALL) ALL 这一行,将名字改成hadoop
保存的时候应该使用强制保存,否则不让保存:
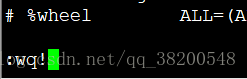
强制保存: :wq!
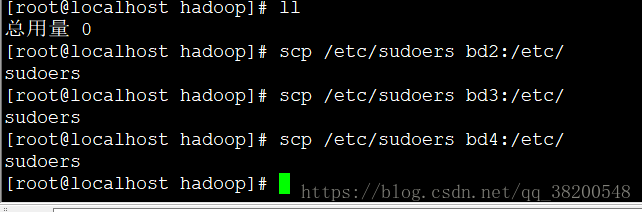
3.2 将配置好的文件复制到另外的三台机器上.
scp /etc/sudoers bd2:/etc/
由于我之前在bd1上配置了对于其他三台机器的免密登录,所以不需要输入登录密码
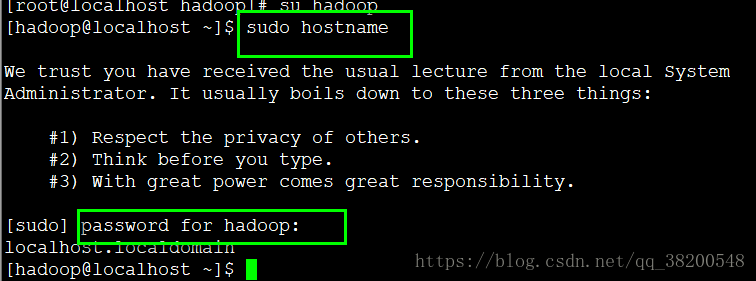
3.3测试 sudo 是否配置成功:
sudo hostname
第一次使用sudo需要输入密码
4.每台机器都切换到root用户,然后关闭防火墙
service iptables stop
配置下次启动时自动关闭防火墙:
chkconfig iptables off
5.hadoop的安装包,需要编译好的安装包:
https://pan.baidu.com/s/1eFpKbExrpT7AcgQvpjvETQ
5.1 将软件包上传到一台服务器上 - bd1
可以使用 rz 命令 进行文件上传
在 /root目录下新建一个文件夹 apps 之后所有的软件都放在这个文件夹里面.
解压压缩包到 apps/ 里面
tar -zxvf cenos-6.5-hadoop-2.6.4.tar.gz -C apps/
hadoop的目录结构:
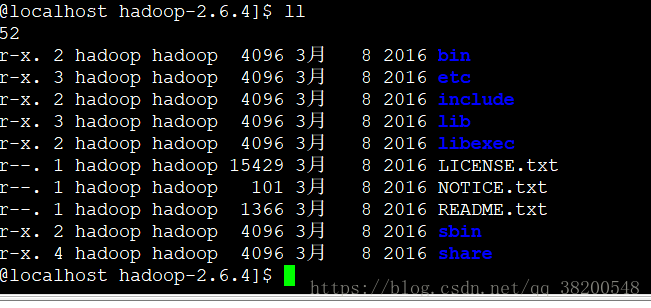
bin : 自己的操作命令
sbin : 系统启动管理的命令
etc : 配置文件
include : C 语言本地库的头
lib : 本地库 里面有一个 native 文件夹 .so
share : doc (文档) 和 hadoop (jar包)
6.配置Hadoop
进入:/home/hadoop/apps/hadoop-2.6.4/etc/hadoop
里面有非常多的配置文件
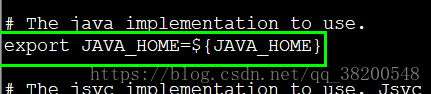
6.1 配置 hadoop-env.sh – 运行时的环境变量
只需要给它一个 java 就可以了
先获取JAVA_HOME:
echo $JAVA_HOME — — /usr/local/jdk1.7.0_45
然后修改 hadoop-env.sh 找到JAVE_HOME处的配置
这种方式是获取一个JAVA_HOEM,但是启动的时候是通过SSH来远程启动的,在子进程里面是没有JAVA_HOME的,所以这种获取的方式是失效的,所以得手动进行指定配置.
剩下的都是Hadoop运行时参数配置: 这些参数其实是配在哪个文件里面都可以的,之所以要分开,是为了对用不同的功能,便于管理查看
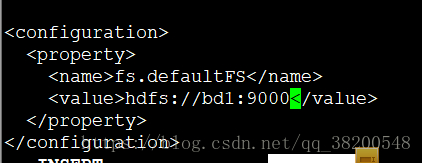
6.2 core-site.xml – 核心的配置 (公共的配置)
注意修改的时候,别改错了,里面是xml文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bd1:9000</value>
</property>
</configuration>
上面配置的其实就是name node, name node 才是为客户提供服务的,客户端去访问hdfs的时候,hdfs是有好多好多台机器的,所以要统统找name node , name node 是记录了哪些文件存在哪些机器上的.
所以客户端访问的时候首先访问的是name node
hadoop.tmp.dir:
hadoop是一个集群版的软件,没一台机器上都有它的工作进程,既然有工作进程那么肯定有本地的工作目录,hadoop.tmp.dir就是这个工作目录
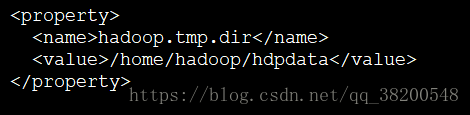
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hdpdata</value>
</property>
6.3 hdfs-site.xml
这个配置文件可以配很多,也可以不用配,因为它都有默认值
副本的数量:
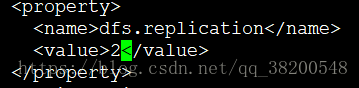
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
客户端把文件交给hdfs之后,hdfs如果只给我保留一份,万一它保留的那份数据的机器宕机了,那么数据就拿不到了,配置副本为2,宕机一台还有另一台,默认是3
6.4 mapred-site.xml.template
mapreduce运行的平台的名称: yarn
mapreduce程序提交完之后就交给yarn去跑了
默认是local,如果是local的话,那么mapreduce程序就会在本机单机上模拟跑一下,就不会到集群上分布式运行了,就变成了一个单机版的小程序,
也能运行
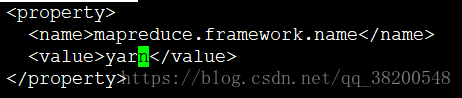
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
修改之后还需要将文件名mapred-site.xml.template变成mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
6.5 yarn-site.xml
找一个老大yarn去分配资源
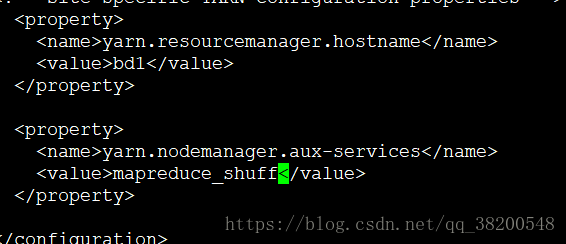
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bd1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuff</value>
</property>
遇到集群搭建出现问题的时候,一般都是配置文件配置的时候出现问题.
在配置的时候需要注意点
完成上面的配置之后,hadoop的配置就完成了.接下来就是要将bd1上配置好的hadoop分发到其他的三台机器上
scp -r apps bd2:/home/hadoop
scp -r apps bd3:/home/hadoop
scp -r apps bd4:/home/hadoop
复制完之后,还先不能启动hadoop,需要先对hadoop做格式化.
hdfs不是一个底层的文件系统,而是架构再Linux文件系统之上的文件系统,它存文件就是把文件分散地放在Linux文件系统里面的.hdfs文件系统是一个高层的抽象的文件系统,借助于操作系统的本地的文件系统的文件系统,它的格式化无非就是生成相应的文件目录.把数据目录生成
1.先配置hadoop的环境变量,不然每一次在敲命令的时候都要进入bin目录
进入hadoop-2.6.4安装目录:
pwd:
/home/hadoop/apps/hadoop-2.6.4

export JAVA_HOME=/usr/local/jdk1.7.0_45
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
bd1配置了hadoop的环境变量之后,将配置文件scp到其他的机器上:
sudo scp /etc/profile bd2:/etc/
sudo scp /etc/profile bd3:/etc/
sudo scp /etc/profile bd4:/etc/
然后让配置文件的环境变量生效:

source /etc/profile
配置好了hadoop的环境变量之后就需要做格式化了:
需要格式化 name node (name node 是记录整个文件的位置,需要生成一些初识目录)
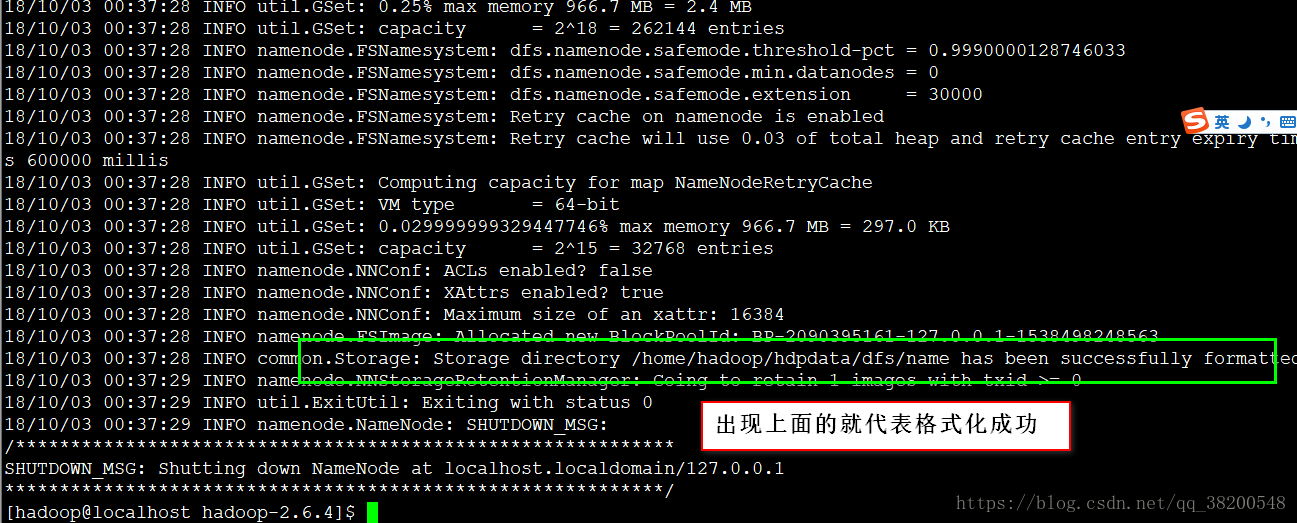
hadoop namenode -format
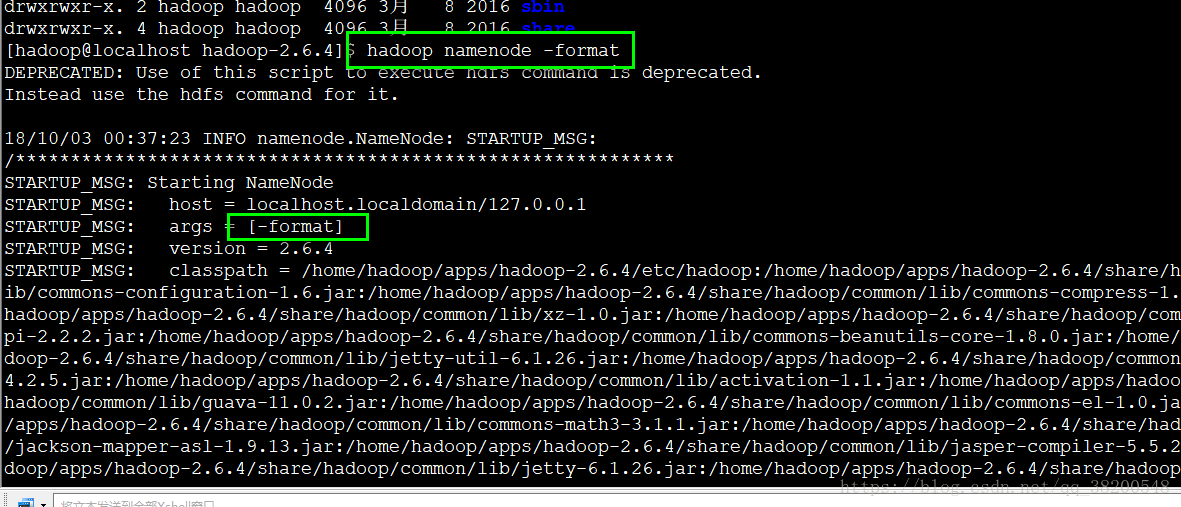
首先得使用 start-dfs.sh 命令,才能帮你生成 hdpdata 文件.
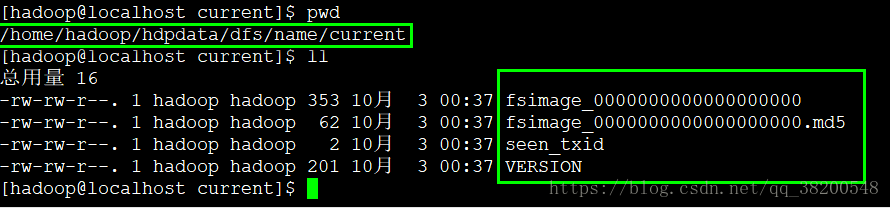
查看hdpdata目录里面生成的内容:
fsimage_0000000000000000000 : 文件系统的那些元信息的镜像
上面的步骤完成之后,hadoop的格式化就完成了.
接下来就可以启动hadoop了
启动name node :
使用jps可以查看name node 是否启动成功
可以查看 name node 的界面 :
访问的地址:
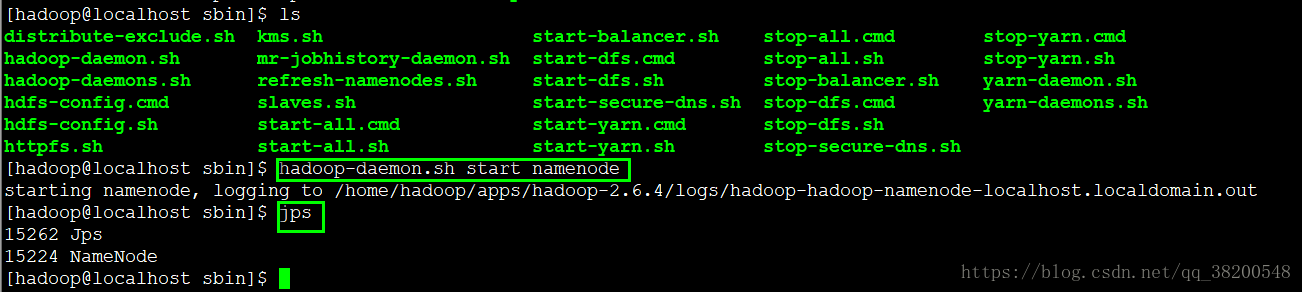
http://bd1:50070/
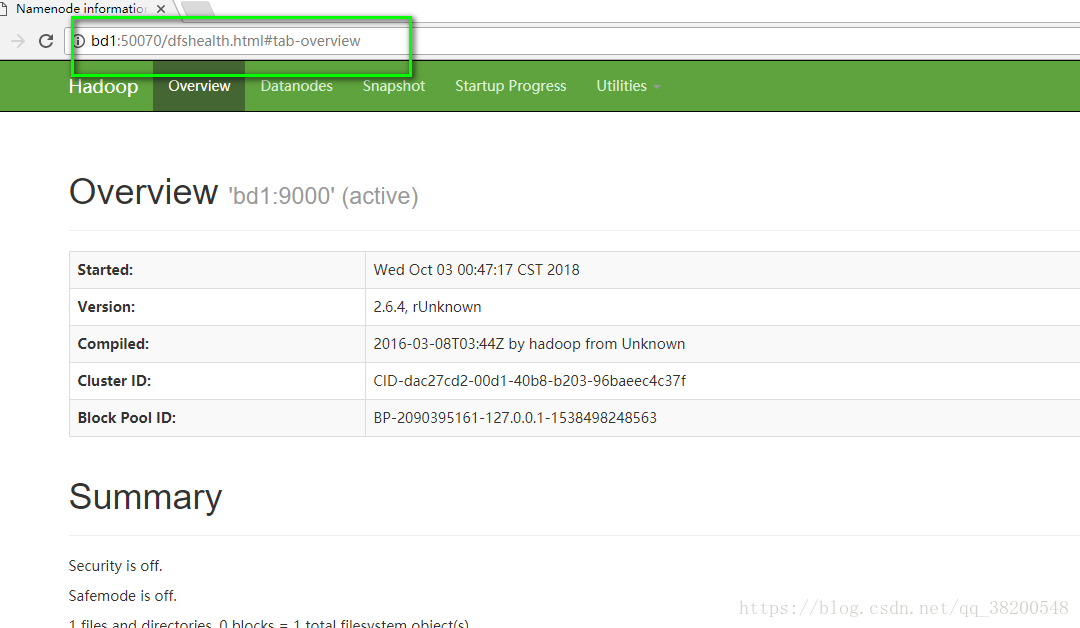
你会发现文件系统的空间为0 原因是没有配置 data note , 只有data note才是存放数据的
在 bd3 上启动datanode
hadoop-daemon.sh start datanode
把start 换成 stop 就可以关闭了
每一台机器上的hadoop的配置文件都是一样的,所以每一台机器都能看到name node 的地址,所以其他的机器就可以跟name node 握手成功.
问题:
我启动了一台name node , bd3 跟 bd4 都能正常启动data node ,但是bd2 却一直启动不了data node.
所以我们需要查看日志,看报错在哪?
日志是打在 .log 文件里面的
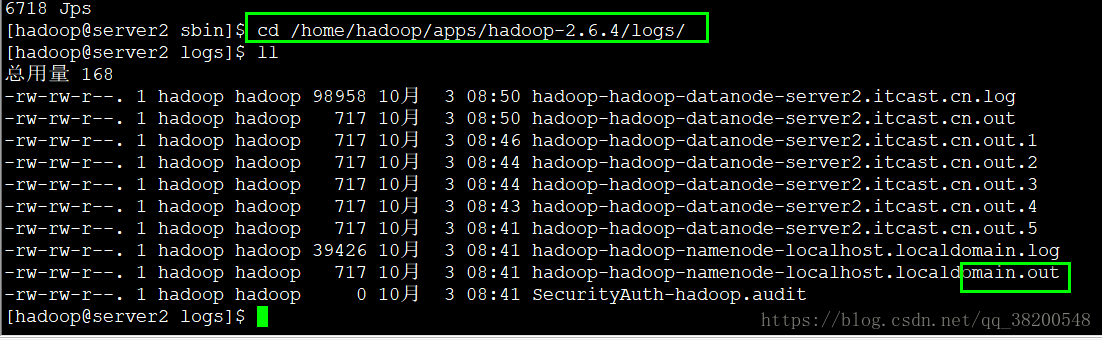
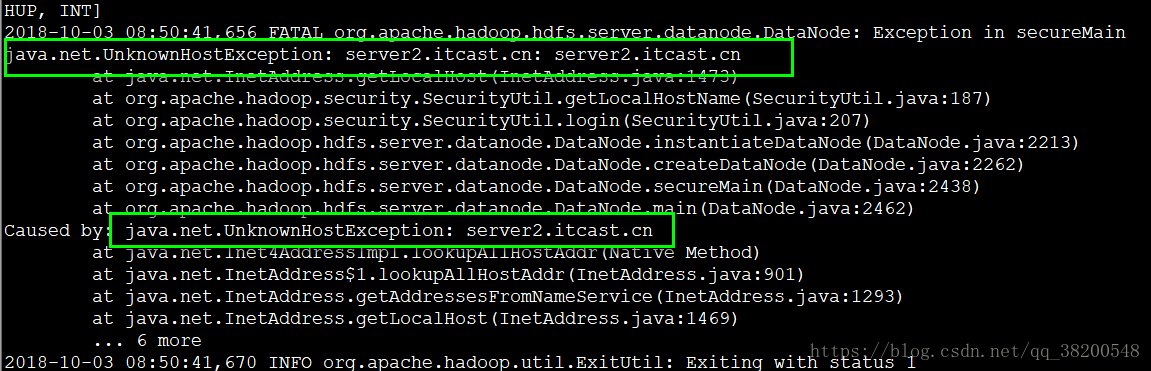
妈的,我之前/etc/sysconfig/network 这个文件跟其他的不一致
所以得修改成主机名字,修改之后,得 reboot 重新启动,否则是不会生效的
------即使是一台机器的data node 启动失败了,也不会影响整个机器的启动
通过脚本自动化启动 hadoop 集群
hadoop自身带了启动集群的脚本:

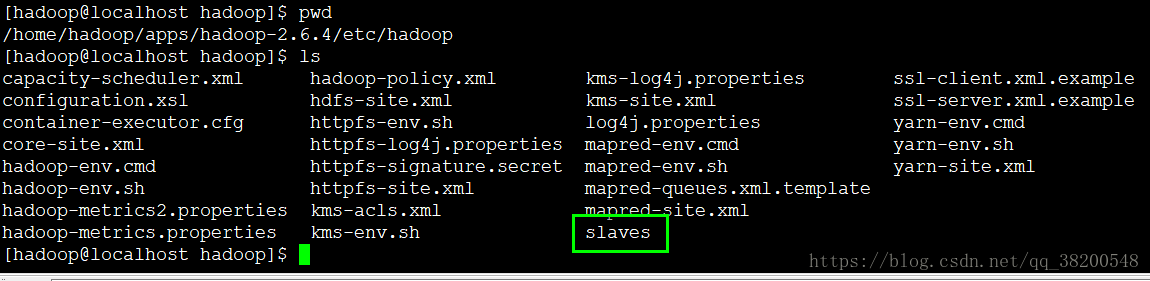
但是有这个脚本之外,还得有一个文件告诉它,我需要启动的机器在哪里
在hadoop的配置文件 etc 里面就有这个文件:
这个slave 文件跟hadoop没有关系,纯粹是为了给这个自动化启动脚本用的,就跟我们自己写的一样
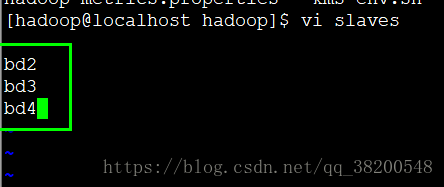
这个slaves 文件默认就只有一个 localhost
只需要配置主机名字,脚本就可以读取到这个文件,通过for循环逐一启动data node
这个自动化脚本是通过 ssh 来 启动远程的机器的
ssh bd2 hadoop-daemon.sh start datanode
ssh bd3 hadoop-daemon.sh start datanode
ssh bd4 hadoop-daemon.sh start datanode
ssh 需要输入密码:
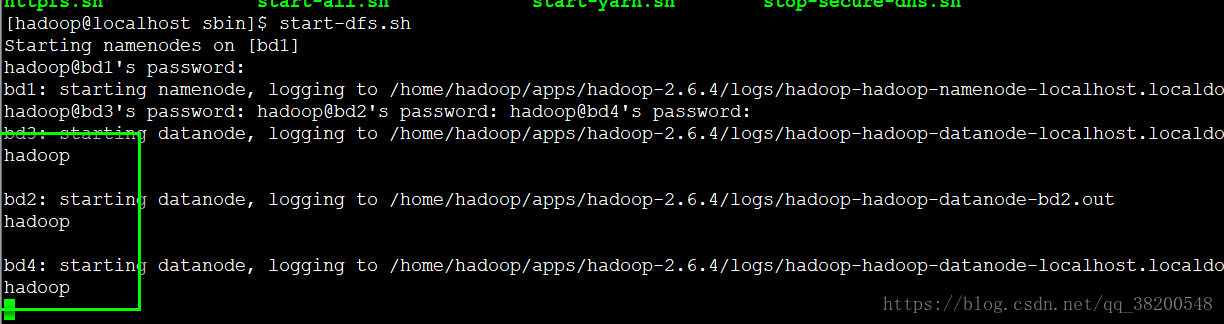
根据它的提示输入密码会出现错位的情况,根本就不知道哪个地方等待的时候是需要输入密码的
所以现在需要配置免密登录: bd1 到 bd2 , bd3, bd4 的免密登录
因为是在bd1上启动这个脚本的:
ssh-keygen
ssh-copy-id bd1
ssh-copy-id bd2
ssh-copy-id bd3
ssh-copy-id bd4
测试免密登录是否成功:
ssh bd2
ssh bd3
ssh bd4
这样就可以直接使用自动化的脚本了,启动跟关闭的时候都不需要输入密码