前言
本应在两月前完成文章,硬生生拖到现在才来补齐,不想找借口开脱,还是时间利用不够充分。紧接上文,此处会呈现MySQL中一些高阶的sql用法。包括view(视图),procedure(存储过程),transaction(事务处理)。
view – 视图
视图view可以理解成虚拟的表,MySQL 5以上添加了对view的支持,所以低版本MySQL无法使用试图。为什么说是虚拟的表,因为通常意义的TABLE是有一行一行实在数据的,但是view并不是。例如现有一个从表中进行数据检索的一个查询sql,但是每次要执行该查询时候,都要重复该sql如果想重复利用,就可以将该sql新建成一个view虚拟表保存在数据库中。view基本操作:
-- 新建视图
> CREATE VIEW `tview` AS SELECT `hr_media`.`id` AS `id`,
`hr_media`.`longtext` AS `longtext`,
`hr_media`.`attrs` AS `attrs`,
`hr_media`.`title` AS `title`,
`hr_media`.`sub_title` AS `sub_title`,
`hr_media`.`link` AS `link`,
`hr_media`.`res_id` AS `res_id`
FROM `hr_media`
WHERE `hr_media`.`id`>50
ADN `hr_media`.`title`<>'';
> SELECT * FROM `tview`;
-- 查看视图 由于view被视为抽象table所以show tables会查询出所有table和view,如果仅想查看所有view
> SHOW TABLE STATUS WHERE COMMENT='VIEW';
-- 查看视图新建信息
> SHOW CREATE VIEW `tview`;
-- 删除视图
> DROP VIEW `tview`;视图更新可以是整体替换select语句或是类似table更新的update操作,不过update有许多条件限定,具体使用可根据情况选择。其实视图最大的作用是隐藏一些复杂检索的sql和某些无不开发权限表信息访问,可以间接通过view给予访问者权限。
procedure – 存储过程
存储过程是为了以后使用保存的一条或多条sql集合,是一组用来完成特功能sql的集合,其有几个特点如下:
1,一般的sql每执行一次就编译一次,而存储过程是在新建时候进行编译,可见存储过程调用效率肯定更高。
2,新建好的存储过程可重复使用,并且对外隐藏一些复杂的sql逻辑。
3,存储过程也是有权限控制的,并且参数化的存储过程可以防治sql注入。安全性也得到提高。
任然沿用书中给出的数据及实例在本地test数据库中:
-- 新建procedure
> DELIMITER // --将MySQL分隔符从默认的 ; 改为 //
> CREATE PROCEDURE productpricing()
BEGIN
SELECT AVG(`prod_price`) AS `price_average`
From `products`;
END //
> DELIMITER ; --将MySQL分隔符再改为从默认的 ;
-- 查看指定数据库test中包含的procedure
> SELECT * FROM `mysql`.`proc`
WHERE db='test'
AND `type`='procedure';
-- 存储过程调用
> CALL productpricing();
-- 删除存储过程
> DROP PROCEDURE productpricing;其实存储过程就是一个对sql封装了的函数定义,上面调用存储过程的形式都形似。相应的存储过程也能接受参数,创建带参数的存储过程的运行实例如下图:
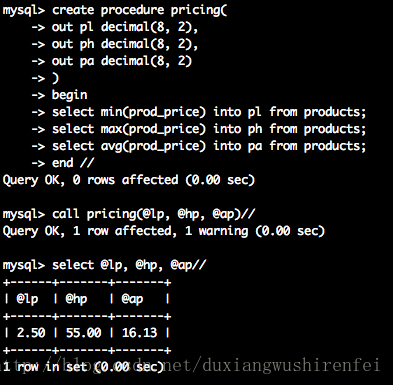
此处创建的名为 pricing 的 procedure,其调用要求三个参数,并且out表示着三个参数是输出的。也就是说将来在外面可以调用,MySQL用@符号表示变量,可以理解成声明了三个为lp, hp, ap的参数。当参数标示符尾in,表示该参数是输入procedure供使用的,此时必须根据声明的类型传入相应的值。
transaction – 事务处理
MySQL 中 transaction
事务处理和之前说的 view 以及 procedure 不太一样,其是通过COMMIT 和 ROLLBACK来维护数据的完整性。技术上解释,将一系列数据的更改操作作为一个整体,一但其中某一个更新操作失败,则整个一系列数据更新操作都视为失败。
前几日遇到一个需求:同步客户订单到自己公司订单数据。结构是订单 + 订单明细,要求同步数据且备份原始数据,因此共涉及四张数据表更新分别是 my_order, my_order_items, origin_order, origin_order_items,因此四张表数据必须同步,如果同步成功,备份失败则撤回所有数据。此就是一个事务处理的一个实际应用。
> START TRANSACTION; -- 开启事务
> DELETE FROM `orderitems` WHERE `order_num`=20;
> DELETE FROM `orders` WHERE `order_num`=10;
> COMMIT; -- 提交执行结果,此时才真正更改数据如果在第二条数据执行失败,则不会COMMIT,表中数据不会被修改,也可用ROLLBACK来手动回滚已经修改的数据表。
注意:
并非所有引擎都支持事务处理,常用的MySQL引擎有MyISAM和InnoDB,其中MyISAM作为MySQL的默认引擎就不支持事务处理。
Python 中 transaction
Tornado-MySQL是一个异步MySQL操作的Python第三方包,官网介绍:
https://github.com/PyMySQL/Tornado-MySQL
其中提供了事务处理的方便实现:
# 以下用伪码实现之前需求
import logging
from tornado import gen
from tornado_mysql import pools
@gen.coroutine
# 开启连接池
pl = pools.Pool(*settings)
# 启动事务
trs = pl.begin()
try:
# 生成订单my_order
yield trs.execute(create_my_order_sql, *p1)
# 获取新建新单相关信息
cursor = yield trs.execute(get_my_order_sql, *p2)
new_my_order = cursor.fetchall()
# 生成my_order对应items
yield trs.execute(create_my_order_item_sql, *p3)
# 备份原始订单origin_order,
yield trs.execute(create_origin_order_sql, *p4)
# 备份origin_order对应origin_order_items,
yield trs.execute(create_origin_order_item_sql, *p5)
except Exception as error:
# 异常回滚数据
yield trs.rollback()
logging.error(error)
else:
# 正常提交写入输入
yield trs.commit()
raise gen.Return(new_my_order)
注意:
trs为Transaction的实例并没有fetchall方法,获取缓存数据需要先获取cousor后fetch。
至此MySQL基本使用暂且告一段落。