前言
不知多久没有来这,并不是放弃了学习,只是这两多月工作实在紧凑胶着。原计划年底前在找一个自己感兴趣的方向看看,结果进度不佳。之前徘徊过Kotlin,如果有时间真应该好好看看。Google钦定的亲儿子,很多Java大神都给予不错评价。不过个人缺少Java工程经验,结合后一阶段工作需求,决定深入去了解MySQL。
途径还是看书加示例验证。推荐书籍《高性能MySQL》,目前读了两章,个人强烈推荐,同时也感觉到自己对数据库了解的浅薄~希望深入的同学,可以买来学习。笔者能力一般,水平有限,此处仅仅对自己读书收获做简单记录。
MySQL架构
MySQL总体是一个分层结构,共3层。
上层:连接层,用以处理和MySQL的链接,授权认证,安全等。
中间层:服务层,MySQL服务功能的核心层。
下层:存储层,包含了各式存储引擎。
一张来自Google的图库的MySQL架构图:
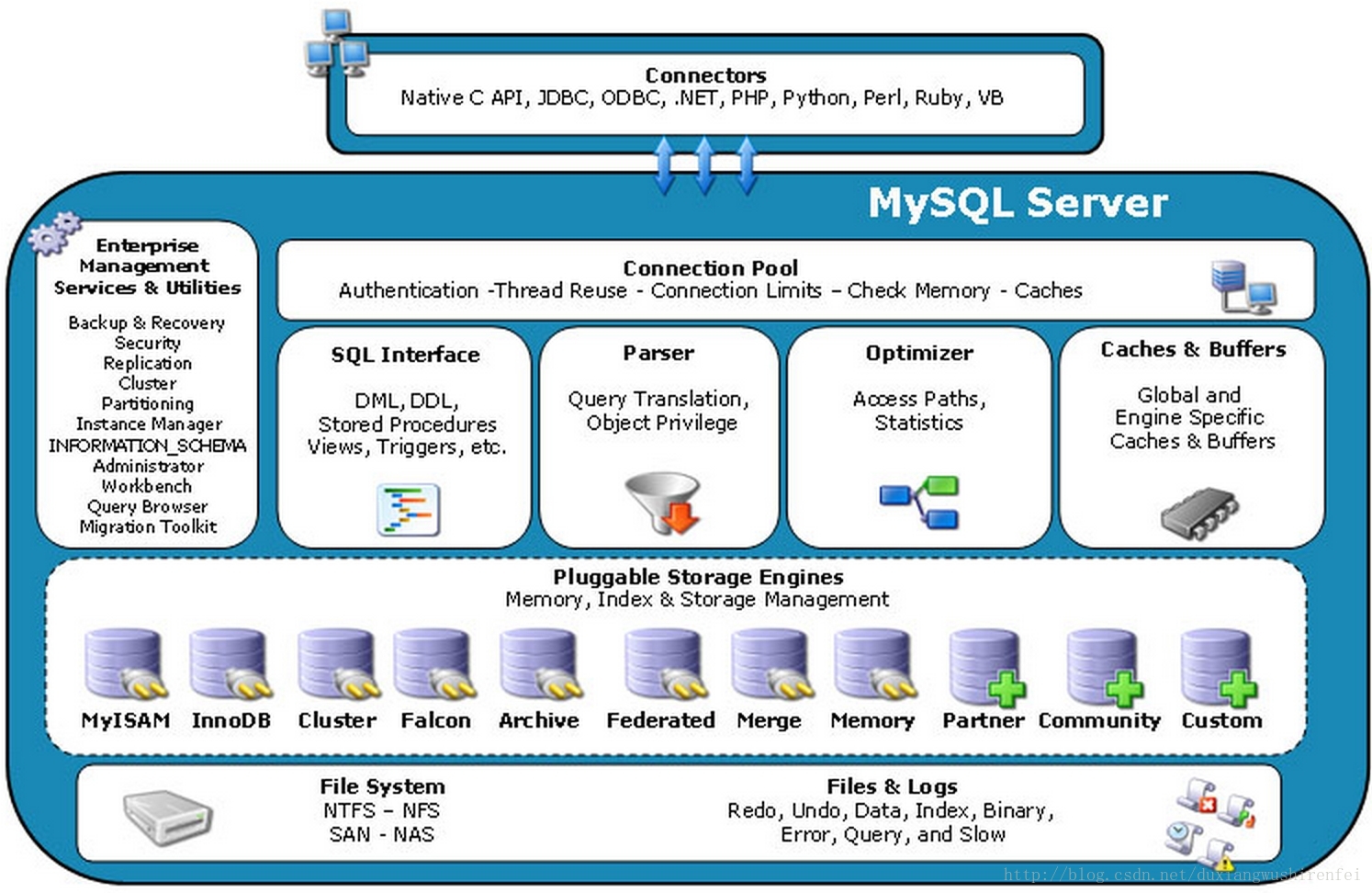
对于核心中间层,分为4个组件:
SQL Interface:接受用户的sql指令,并且返回结果,同时存储了用户定义的存储过程(procedures),视图(views),触发器(views)等。
Parser:解析器,对用户给出的sql指令进行验证解析,如果解析出错,该sql将不会被执行。
Optimizer:优化器,对解析通过的sql进行查询优化。
Cache 和 Buffer:对查询结果和sql的hash值做一个对应缓存到内存中。sql所取数据基表数据发生任何变化,该缓存失效。
用户在链接MySQL进行数据查询的一个基本过程是:
1,客户发送查询指令
2,MySQL服务接受指令
3,去缓存中查询该指令是否有缓存结果,如果有立刻返回,如果没有继续执行 (前提是缓存查询是打开的)
4,解析用户发送的sql,并优化
5,调用存储引擎API执行查询,将结果返回给用户
查看MySQL 查询缓存设定
> SHOW VARIABLES LIKE 'query_cache%';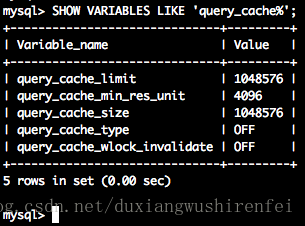
个人机器 MySQL 配置:
query_cache_limit:MySQL能够缓存的结果所占空间最大值 图中数值为 1024 * 1024 个字节,就是1M,也就是说超过1M的结果缓存不了。
query_cache_min_res_unit:创建缓存是分配的最单元 4096 字节,也就是说缓存数据是按这个步长分配空间。
query_cache_size:MySQL缓存上限大小,本机也是1M。
query_cache_type:是否打开 OFF/ON。
query_cache_wlock_invalidate:如果查询涉及表被锁住,是否仍然从缓存中返回结果,OFF/ON。
> SELECT VERSION(); -- 查看数据库版本
> SHOW STATUS; -- 查看数据状态锁
锁 – 根本目的是为了进行并发控制,数据库有两种类型的锁 “共享锁”和“排他锁”,亦称之为“读锁”和“写锁”。
二者的核心区别在于,读锁 是一个共享锁,相互之间是不阻塞的,不同客户可以同时时间读取同一资源。而写锁是一个排他锁,会阻塞其他写锁和读锁。
由于锁的存在,保证了数据的一致性,安全型。但是加锁的操作,一定会有额外开销。锁的策略就是一种开销和数据安全之间的平衡。
MySQL中的锁是有不同颗粒度的。表级锁,整表锁定,例如ALTER TABLE操作会锁定整表。行级锁,锁定修改的行数据。不同存储引擎都有自己锁的机制。
事务
事务基础特性
在之前的笔记中MySQL 小结(三) 中给出了事务基本使用方式。事务的核心是将一组sql作为一个整体,要么全部成功执行所有这一组sql,要么全部失败。MySQL常用的存储引擎中,MyISAM是不支持事务的,而InnoDB支持。并且在InnoDB中,所有的query都是事务的,默认情况下AUTOCOMMIT 是开启的,所有逐一执行的query都是要作为事务开启,提交。
> SHOW VARIABLES LIKE 'AUTOCOMMIT%'; -- 查看自动提交状态
> START TRANSACTION; -- 手动开启事务
> ROLLBACK; -- 手动回滚数据
> BEGIN; -- 手动开启事务
> COMMIT; -- 提交事务事务操作具有ACID,
Atomicity – 原子性:一组sql是作为一个整体,但凡一个执行失败,整体即归为失败。
Consistency – 一致性:事务未提交之前,数据库的数据不会正真修改。
Isolation – 隔离性:事务中对数据修改未提交之前,对其他事务是不可见的。
Durability – 持久性:一旦事务提交了数据,则该事务中做出的所有数据修改都将被持久保存。即便MySQL服务宕机,数据任然保存在机器中。
事务隔离级别
我们常用MySQL的事务型存储引擎都是InnoDB,其在事务中的隔离级别一共有四个等级,四个不同隔离等级对应事务数据的隔离特性也不相同。
> SHOW VARIABLES LIKE 'tx_isolation%'; -- 查看数据库默认隔离级别
> SELECT @@global.tx_isolation; -- 查看全局隔离级别
> SELECT @@session.tx_isolation; --查看当前会话隔离级别
> SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE}; -- 修改[全局|当前会话]隔离级别{4个等级中的一个}READ UNCOMMITTED – 未提交读:亦称为“脏读”,即使事务未提交的数据,对其他事务也是可见的。这种隔离级别很少用到,因为读取了尚未提交的数据,会存在很多问题,设置session参数,执行结果如下:
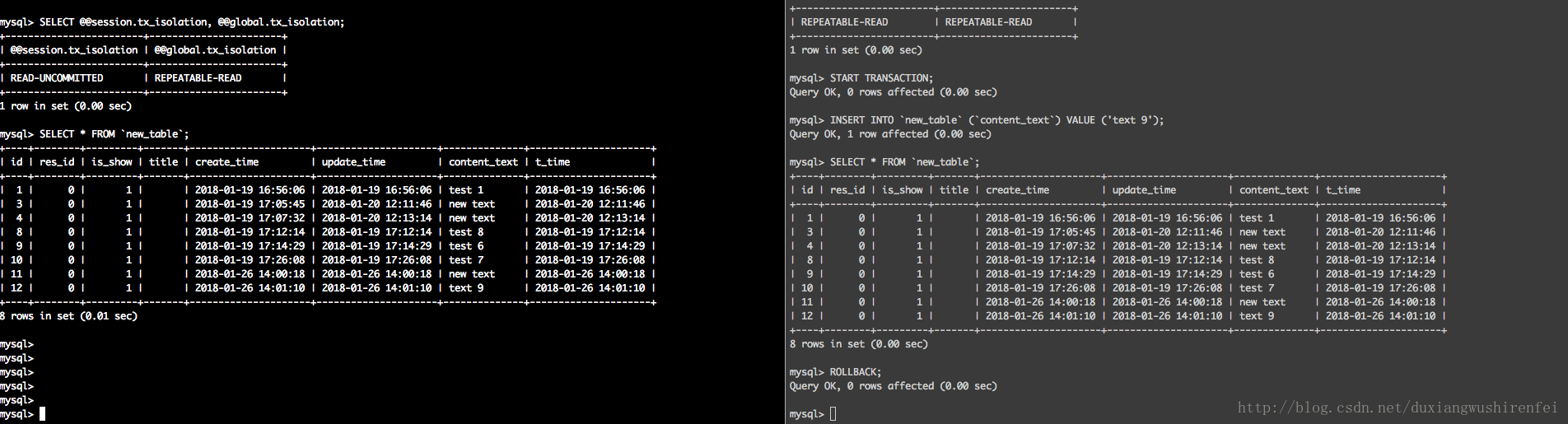
READ COMMITTED – 提交读:事务会读取到其他事务已经提交的数据。这样带来的后果是相同的检索,在同一个事务中可能会得出不同的结果,因为期间如果其他事务提交了符合条件的数据,亦会被检索出,修改session 隔离级别,执行如下:
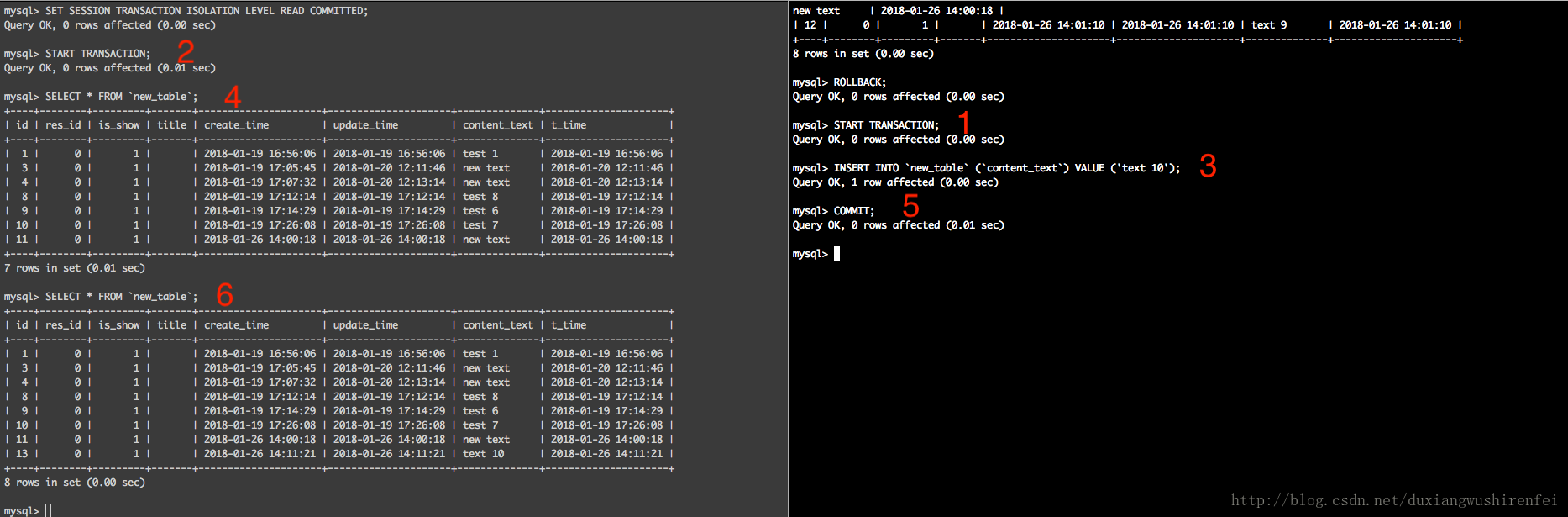
REPEATABLE READ – 可重读:该级别是MySQL 默认的全局事务隔离级别,其解决了之前两种隔离存在的“脏读”和不一致数据的问题,但是其会存在 “幻读”。重新设置session隔离级别,跟觉执行图中的红色操作顺序,结果如下:
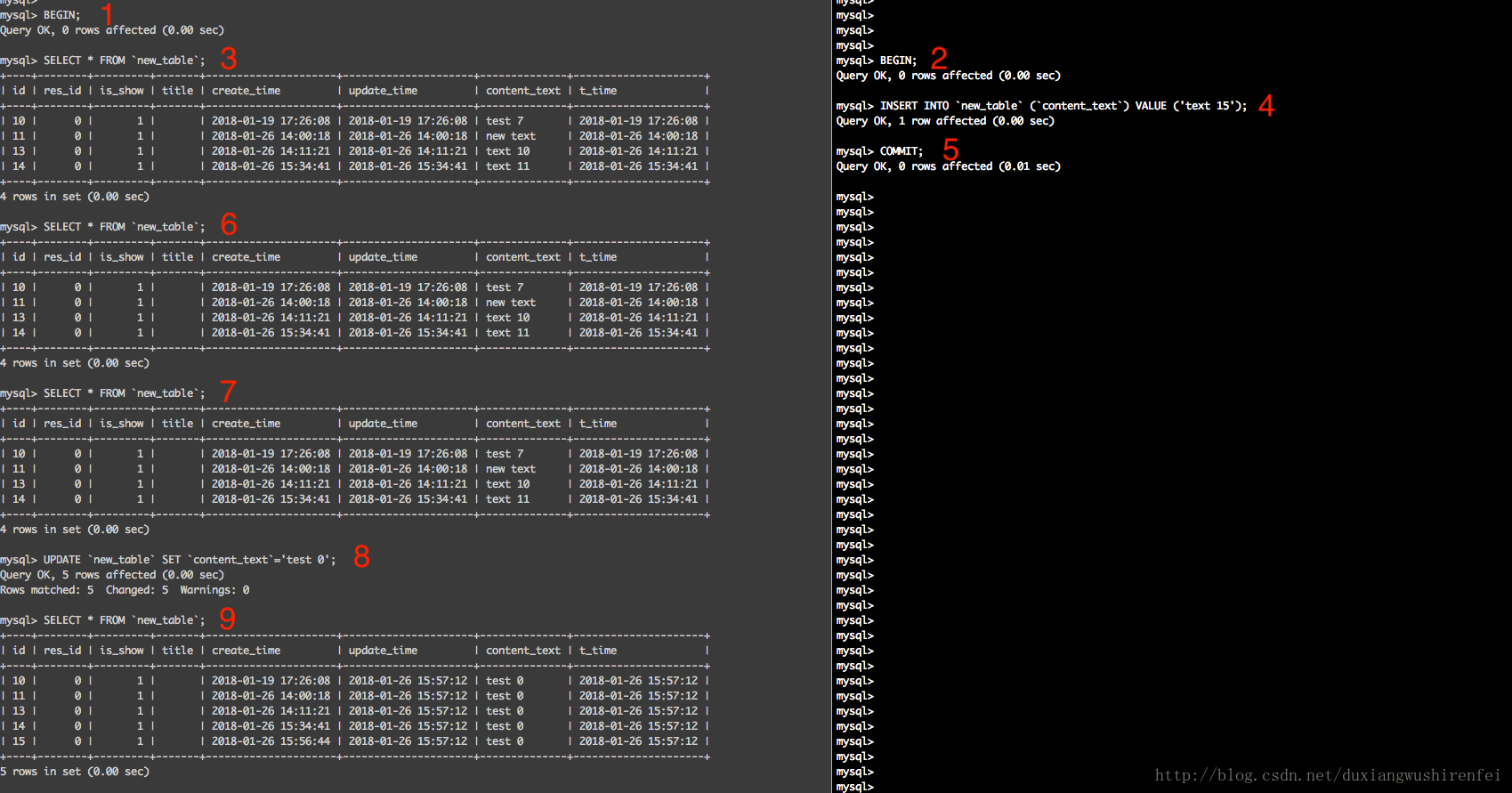
在执行完update语句后,检索出了在右侧事务中提交的id未15的数据了,此为幻读。
SERIALIZABLE – 串行化:强制事务串行执行,能够避“脏读”,“幻读”,但是没读取一行数据都会加锁,造成大量锁争夺等待。
死锁
在上面的示例中可以看出,InnoDB中不同级别的隔离成都,InnoDB默认是为事务涉及的行数据加锁,设想两条事务同时先后修修改相同的两行数据如何?
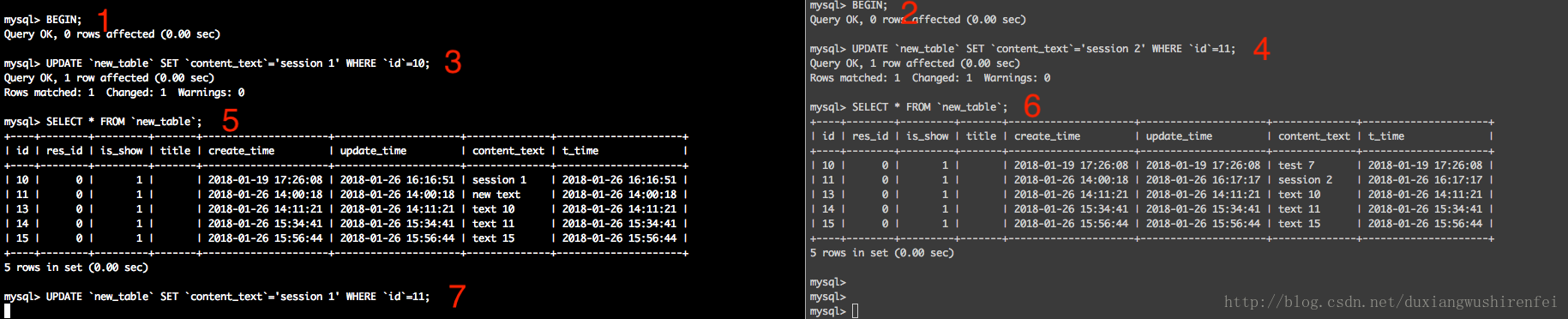
此时如果session2 修改id为10的数据,会触发死锁的错误,直接退出当前事务,而session1也因此获取了id为10的数据的修改权限,进而修改。如果session2迟迟不做处理,session1会因此获取锁超时,无法修改,但是任然处在当前事务中,之前的修改任然在缓存中,提交后任然会生效。
MVCC
多版本并发控制 MVCC,是行级锁的一个变种,通过保存数据在某个时间节点的快照(snapshot),类似实现了行级锁。由此不同事务对同一表,同一时刻看到的数据可能是不一样的。
实现上通过在不同的数据行后增加创建日期版本号和删除日期版本号,且版本号不断递增,进而实现了数据快照。在默认的隔离级别 REPEATABLE READ级别下,查,增,删,改操作分别是:
SELECT:
InnoDB只会检索出比当前事务版本号小的数据和当前事务自身创建的数据。
行的删除数据要么为空,要么比当前版本号大
符合以上2者的数据才会被检索出
INSERT:
InnoDB为每一行数据保存当前版本号。
DELETE:
InnoDB为每所删除的每一行的删除日期标识保存当前版本号。
UPDATE:
InnoDB为更新的每一行旧数据添加删除日期标识保存当前版本号,并且复制添加一条新数据作为修改记录此记录的新建日期为当前版本号。
操作锁
SELECT:是共享锁,不会阻塞其他操作。
UPDATE:写锁,会阻塞问题是其是什么颗粒度的锁?
对于之前展示的数据,UPDATE操作查询WHERE中所用的条件是主键字段,此时只有当前更新行会被锁定,如果使用非主键字段,则会锁定整张表。
DELETE:写锁,同样如果使用主键作为筛选条件只会锁定行,否则会整表锁定。
INSERT:只会锁定待新建的行数据。如果UPDATE操作涉及改尚未提交的行数据,则会被阻塞。比如开启两个事务,session1先进行了INSERT数据,session2执行整表更新,此时session2会等待session1提交新建数据后,再执行更新操作,session1的INSERT组赛了session2。但是如果session2如果更新以其他的主键值未条件,则不会受到组赛。
理解幻读
由之前提到的MVCC的控制逻辑,结合上述操作的锁逻辑,基本可以理解“幻读”数据从何而来。
1:session2插入数据后,session1执行检索只能读取到之前事务开启的快照数据,没有任何问题。
2:session1执行update整表操作,锁定全表,更新所有数据。由MVCC的更新操作可以知道,实质是执行删除标记置位,新建新数据。
3:再次执行检索操作,会将在其事务执行期间,其他事务已提交的数据,由于2步骤更新时复制新建保存当前事务版本号,同样检索出来。
附注
专有名词
四种语言
DDL数据库定义语言包括诸如:
CREATE – 新建
ALTER – 修改
DROP – 删除数据库,表
COMMENT – 注释
RENAME – 修改表名称
DML数据库操作语言诸如:
SELECT,INSERT,UPDATE,DELETE
CALL – 调用存储过程
EXPLAIN – 查看sql执行计划
LOCK TABLE – 表锁定
TRUNCATE – 清空表中数据
DCL数据库控制语言诸如:
GRANT – 授权
REVOKE – 取消授权
TCL事务控制语言诸如:
START TRANSACTION
BENGIN
COMMIT
ROLLBACK
SAVEPOINT – 设置保存点
@ 符号
在MySQL中,一个@符表示用户自定义的局部变量
> SET @my_variable='hello world'; -- 定义局部变量
> SELECT @my_variable; -- 检索局部变量,如果不存在检索值为NULL @@符号两个连用表示引用系统中的全局变量,之前的检索数据库隔离级别便是查看了全局变量值。
查看status
> SHOW STATUS; -- 查看数据库当前状态
> SHOW STATUS LIKE 'status_name%'; -- 过滤指定状态变量状态变量含义:
Aborted_clients 由于客户没有正确关闭连接已经死掉,已经放弃的连接数量。
Aborted_connects 尝试已经失败的MySQL服务器的连接的次数。
Connections 试图连接MySQL服务器的次数。
Created_tmp_tables 当执行语句时,已经被创造了的隐含临时表的数量。
Delayed_insert_threads 正在使用的延迟插入处理器线程的数量。
Delayed_writes 用INSERT DELAYED写入的行数。
Delayed_errors 用INSERT DELAYED写入的发生某些错误(可能重复键值)的行数。
Flush_commands 执行FLUSH命令的次数。
Handler_delete 请求从一张表中删除行的次数。
Handler_read_first 请求读入表中第一行的次数。
Handler_read_key 请求数字基于键读行。
Handler_read_next 请求读入基于一个键的一行的次数。
Handler_read_rnd 请求读入基于一个固定位置的一行的次数。
Handler_update 请求更新表中一行的次数。
Handler_write 请求向表中插入一行的次数。
Key_blocks_used 用于关键字缓存的块的数量。
Key_read_requests 请求从缓存读入一个键值的次数。
Key_reads 从磁盘物理读入一个键值的次数。
Key_write_requests 请求将一个关键字块写入缓存次数。
Key_writes 将一个键值块物理写入磁盘的次数。
Max_used_connections 同时使用的连接的最大数目。
Not_flushed_key_blocks 在键缓存中已经改变但是还没被清空到磁盘上的键块。
Not_flushed_delayed_rows 在INSERT DELAY队列中等待写入的行的数量。
Open_tables 打开表的数量。
Open_files 打开文件的数量。
Open_streams 打开流的数量(主要用于日志记载)
Opened_tables 已经打开的表的数量。
Questions 发往服务器的查询的数量。
Slow_queries 要花超过long_query_time时间的查询数量。
Threads_connected 当前打开的连接的数量。
Threads_running 不在睡眠的线程数量。
Uptime 服务器工作了多少秒。